

Upload folder using huggingface_hub
Browse files- README.md +209 -0
- added_tokens.json +33 -0
- config.json +225 -0
- configuration_intern_vit.py +120 -0
- configuration_internvl_chat.py +97 -0
- conversation.py +391 -0
- examples/image.png +0 -0
- generation_config.json +4 -0
- merges.txt +0 -0
- model-00001-of-00004.safetensors +3 -0
- model-00002-of-00004.safetensors +3 -0
- model-00003-of-00004.safetensors +3 -0
- model-00004-of-00004.safetensors +3 -0
- model.safetensors.index.json +692 -0
- modeling_intern_vit.py +431 -0
- modeling_internvl_chat.py +564 -0
- preprocessor_config.json +19 -0
- special_tokens_map.json +31 -0
- tokenizer.json +0 -0
- tokenizer_config.json +281 -0
- vocab.json +0 -0
README.md
ADDED
|
@@ -0,0 +1,209 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
license: mit
|
| 3 |
+
pipeline_tag: image-text-to-text
|
| 4 |
+
library_name: transformers
|
| 5 |
+
base_model:
|
| 6 |
+
- OpenGVLab/InternVL2_5-8B
|
| 7 |
+
- OpenGVLab/InternVL2_5-8B-MPO
|
| 8 |
+
base_model_relation: finetune
|
| 9 |
+
datasets:
|
| 10 |
+
- OpenGVLab/MMPR-v1.2
|
| 11 |
+
- OpenGVLab/VisualPRM400K-v1.1
|
| 12 |
+
language:
|
| 13 |
+
- multilingual
|
| 14 |
+
tags:
|
| 15 |
+
- internvl
|
| 16 |
+
- custom_code
|
| 17 |
+
---
|
| 18 |
+
|
| 19 |
+
# VisualPRM-8B-v1.1
|
| 20 |
+
|
| 21 |
+
[\[📂 GitHub\]](https://github.com/OpenGVLab/InternVL)
|
| 22 |
+
[\[📜 Paper\]](https://arxiv.org/abs/2503.10291)
|
| 23 |
+
[\[🆕 Blog\]](https://internvl.github.io/blog/2025-03-13-VisualPRM/)
|
| 24 |
+
[\[🤗 model\]](https://huggingface.co/OpenGVLab/VisualPRM-8B-v1.1)
|
| 25 |
+
[\[🤗 dataset\]](https://huggingface.co/datasets/OpenGVLab/VisualPRM400K)
|
| 26 |
+
[\[🤗 benchmark\]](https://huggingface.co/datasets/OpenGVLab/VisualProcessBench)
|
| 27 |
+
|
| 28 |
+
***This is a newer version of [VisualPRM-8B](https://huggingface.co/OpenGVLab/VisualPRM-8B), which exhibits superior performance compared to [VisualPRM-8B](https://huggingface.co/OpenGVLab/VisualPRM-8B).***
|
| 29 |
+
|
| 30 |
+
## Introduction
|
| 31 |
+
|
| 32 |
+
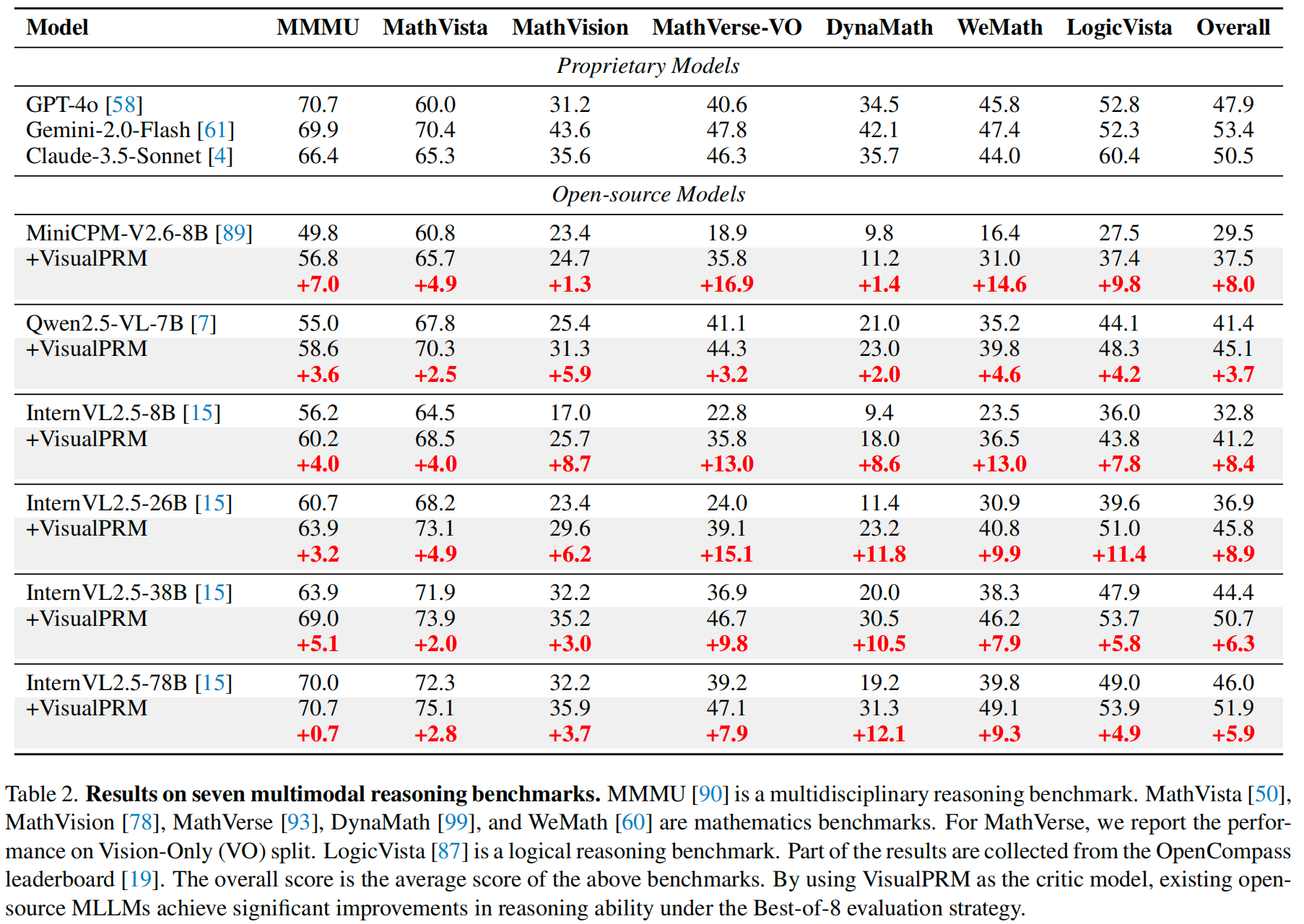
We introduce VisualPRM, an advanced multimodal Process Reward Model (PRM) with 8B parameters, which improves the reasoning abilities of existing Multimodal Large Language Models (MLLMs) across different model scales and families with Best-of-N (BoN) evaluation strategies. **Specifically, our model improves the reasoning performance of three types of MLLMs and four different model scales. Even when applied to the highly capable InternVL2.5-78B, it achieves a 5.9-point improvement across seven multimodal reasoning benchmarks.** Experimental results show that our model exhibits superior performance compared to Outcome Reward Models and Self-Consistency during BoN evaluation. To facilitate the training of multimodal PRMs, we construct a multimodal process supervision dataset VisualPRM400K using an automated data pipeline. For the evaluation of multimodal PRMs, we propose VisualProcessBench, a benchmark with human-annotated step-wise correctness labels, to measure the abilities of PRMs to detect erroneous steps in multimodal reasoning tasks. We hope that our work can inspire more future research and contribute to the development of MLLMs.
|
| 33 |
+
|
| 34 |
+

|
| 35 |
+
|
| 36 |
+
## Performance
|
| 37 |
+
|
| 38 |
+
|
| 39 |
+

|
| 40 |
+
|
| 41 |
+
|
| 42 |
+
## Inference with Transformers
|
| 43 |
+
|
| 44 |
+
```python
|
| 45 |
+
import torch
|
| 46 |
+
import torchvision.transforms as T
|
| 47 |
+
|
| 48 |
+
from PIL import Image
|
| 49 |
+
from transformers import AutoModel, AutoTokenizer
|
| 50 |
+
from torchvision.transforms.functional import InterpolationMode
|
| 51 |
+
|
| 52 |
+
IMAGENET_MEAN = (0.485, 0.456, 0.406)
|
| 53 |
+
IMAGENET_STD = (0.229, 0.224, 0.225)
|
| 54 |
+
|
| 55 |
+
def build_transform(input_size):
|
| 56 |
+
MEAN, STD = IMAGENET_MEAN, IMAGENET_STD
|
| 57 |
+
transform = T.Compose([
|
| 58 |
+
T.Lambda(lambda img: img.convert('RGB') if img.mode != 'RGB' else img),
|
| 59 |
+
T.Resize((input_size, input_size), interpolation=InterpolationMode.BICUBIC),
|
| 60 |
+
T.ToTensor(),
|
| 61 |
+
T.Normalize(mean=MEAN, std=STD)
|
| 62 |
+
])
|
| 63 |
+
return transform
|
| 64 |
+
|
| 65 |
+
def find_closest_aspect_ratio(aspect_ratio, target_ratios, width, height, image_size):
|
| 66 |
+
best_ratio_diff = float('inf')
|
| 67 |
+
best_ratio = (1, 1)
|
| 68 |
+
area = width * height
|
| 69 |
+
for ratio in target_ratios:
|
| 70 |
+
target_aspect_ratio = ratio[0] / ratio[1]
|
| 71 |
+
ratio_diff = abs(aspect_ratio - target_aspect_ratio)
|
| 72 |
+
if ratio_diff < best_ratio_diff:
|
| 73 |
+
best_ratio_diff = ratio_diff
|
| 74 |
+
best_ratio = ratio
|
| 75 |
+
elif ratio_diff == best_ratio_diff:
|
| 76 |
+
if area > 0.5 * image_size * image_size * ratio[0] * ratio[1]:
|
| 77 |
+
best_ratio = ratio
|
| 78 |
+
return best_ratio
|
| 79 |
+
|
| 80 |
+
def dynamic_preprocess(image, min_num=1, max_num=12, image_size=448, use_thumbnail=False):
|
| 81 |
+
orig_width, orig_height = image.size
|
| 82 |
+
aspect_ratio = orig_width / orig_height
|
| 83 |
+
|
| 84 |
+
# calculate the existing image aspect ratio
|
| 85 |
+
target_ratios = set(
|
| 86 |
+
(i, j) for n in range(min_num, max_num + 1) for i in range(1, n + 1) for j in range(1, n + 1) if
|
| 87 |
+
i * j <= max_num and i * j >= min_num)
|
| 88 |
+
target_ratios = sorted(target_ratios, key=lambda x: x[0] * x[1])
|
| 89 |
+
|
| 90 |
+
# find the closest aspect ratio to the target
|
| 91 |
+
target_aspect_ratio = find_closest_aspect_ratio(
|
| 92 |
+
aspect_ratio, target_ratios, orig_width, orig_height, image_size)
|
| 93 |
+
|
| 94 |
+
# calculate the target width and height
|
| 95 |
+
target_width = image_size * target_aspect_ratio[0]
|
| 96 |
+
target_height = image_size * target_aspect_ratio[1]
|
| 97 |
+
blocks = target_aspect_ratio[0] * target_aspect_ratio[1]
|
| 98 |
+
|
| 99 |
+
# resize the image
|
| 100 |
+
resized_img = image.resize((target_width, target_height))
|
| 101 |
+
processed_images = []
|
| 102 |
+
for i in range(blocks):
|
| 103 |
+
box = (
|
| 104 |
+
(i % (target_width // image_size)) * image_size,
|
| 105 |
+
(i // (target_width // image_size)) * image_size,
|
| 106 |
+
((i % (target_width // image_size)) + 1) * image_size,
|
| 107 |
+
((i // (target_width // image_size)) + 1) * image_size
|
| 108 |
+
)
|
| 109 |
+
# split the image
|
| 110 |
+
split_img = resized_img.crop(box)
|
| 111 |
+
processed_images.append(split_img)
|
| 112 |
+
assert len(processed_images) == blocks
|
| 113 |
+
if use_thumbnail and len(processed_images) != 1:
|
| 114 |
+
thumbnail_img = image.resize((image_size, image_size))
|
| 115 |
+
processed_images.append(thumbnail_img)
|
| 116 |
+
return processed_images
|
| 117 |
+
|
| 118 |
+
def load_image(image, input_size=448, max_num=12):
|
| 119 |
+
image = Image.open(image).convert('RGB')
|
| 120 |
+
transform = build_transform(input_size=input_size)
|
| 121 |
+
images = dynamic_preprocess(image, image_size=input_size, use_thumbnail=True, max_num=max_num)
|
| 122 |
+
pixel_values = [transform(image) for image in images]
|
| 123 |
+
pixel_values = torch.stack(pixel_values)
|
| 124 |
+
return pixel_values
|
| 125 |
+
|
| 126 |
+
def main():
|
| 127 |
+
path = 'OpenGVLab/VisualPRM-8B-v1.1'
|
| 128 |
+
tokenizer = AutoTokenizer.from_pretrained(path, trust_remote_code=True, use_fast=False)
|
| 129 |
+
model = AutoModel.from_pretrained(
|
| 130 |
+
path,
|
| 131 |
+
trust_remote_code=True,
|
| 132 |
+
low_cpu_mem_usage=True,
|
| 133 |
+
torch_dtype=torch.bfloat16,
|
| 134 |
+
).eval().cuda()
|
| 135 |
+
|
| 136 |
+
question = 'Find m \\angle 3.'
|
| 137 |
+
|
| 138 |
+
response_a = """
|
| 139 |
+
To find the measure of \\angle 3, we need to use the properties of the angles in the given geometric figure.
|
| 140 |
+
|
| 141 |
+
1. \\angle EDC is a right angle, and it is split into \\angle EDF and \\angle 3.
|
| 142 |
+
|
| 143 |
+
2. We know that \\angle EDF = 39^\\circ because it is labeled in the diagram.
|
| 144 |
+
|
| 145 |
+
3. Since \\angle EDC is 90^\\circ, we can set up the equation for \\angle 3: \\angle EDC = \\angle EDF + \\angle 3
|
| 146 |
+
|
| 147 |
+
4. Substituting the known values, we get: 90^\\circ = 39^\\circ + \\angle 3
|
| 148 |
+
|
| 149 |
+
5. Solving for \\angle 3: \\angle 3 = 90^\\circ - 39^\\circ
|
| 150 |
+
|
| 151 |
+
6. Simplifying the equation: \\angle 3 = 51^\\circ
|
| 152 |
+
|
| 153 |
+
Final answer: 51^\\circ
|
| 154 |
+
""".strip()
|
| 155 |
+
|
| 156 |
+
response_b = """
|
| 157 |
+
To find \\( m \\angle 3 \\), we need to analyze the given geometric figure carefully.
|
| 158 |
+
|
| 159 |
+
1. Recognize that \\( \\angle 3 \\) is part of triangle \\( BCE \\). Since \\( \\angle 1 \\) is given as 48° and \\( \\angle 2 \\) is a right angle (90°), we can use the properties of a right triangle to find \\( \\angle 3 \\).
|
| 160 |
+
|
| 161 |
+
2. The sum of the angles in any triangle is 180°. Therefore, in triangle \\( BCE \\): \[ \\angle 1 + \\angle 2 + \\angle 3 = 180° \]
|
| 162 |
+
|
| 163 |
+
3. Substitute the known values: \[ 48° + 90° + \\angle 3 = 180° \]
|
| 164 |
+
|
| 165 |
+
4. Solve for \\( \\angle 3 \\): \[ \\angle 3 = 180° - 48° - 90° = 42° \]
|
| 166 |
+
|
| 167 |
+
Thus, the measure of \\( \\angle 3 \\) is 42°.
|
| 168 |
+
|
| 169 |
+
Final answer: 42
|
| 170 |
+
""".strip()
|
| 171 |
+
|
| 172 |
+
response_list = [
|
| 173 |
+
response_a,
|
| 174 |
+
response_b,
|
| 175 |
+
]
|
| 176 |
+
image = 'examples/image.png'
|
| 177 |
+
pixel_values = load_image(image).to(torch.bfloat16).cuda()
|
| 178 |
+
|
| 179 |
+
sorted_response_list = model.select_best_response(
|
| 180 |
+
tokenizer=tokenizer,
|
| 181 |
+
question=question,
|
| 182 |
+
response_list=response_list,
|
| 183 |
+
pixel_values=pixel_values,
|
| 184 |
+
return_scores=True,
|
| 185 |
+
)
|
| 186 |
+
|
| 187 |
+
print('Best response:', sorted_response_list[0][0])
|
| 188 |
+
print('Highest score:', sorted_response_list[0][1])
|
| 189 |
+
|
| 190 |
+
if __name__ == '__main__':
|
| 191 |
+
main()
|
| 192 |
+
```
|
| 193 |
+
|
| 194 |
+
## License
|
| 195 |
+
|
| 196 |
+
This project is released under the MIT License. This project uses the pre-trained internlm2_5-7b-chat as a component, which is licensed under the Apache License 2.0.
|
| 197 |
+
|
| 198 |
+
## Citation
|
| 199 |
+
|
| 200 |
+
If you find this project useful in your research, please consider citing:
|
| 201 |
+
|
| 202 |
+
```BibTeX
|
| 203 |
+
@article{wang2025visualprm,
|
| 204 |
+
title={VisualPRM: An Effective Process Reward Model for Multimodal Reasoning},
|
| 205 |
+
author={Wang, Weiyun and Gao, Zhangwei and Chen, Lianjie and Chen, Zhe and Zhu, Jinguo and Zhao, Xiangyu and Liu, Yangzhou and Cao, Yue and Ye, Shenglong and Zhu, Xizhou and others},
|
| 206 |
+
journal={arXiv preprint arXiv:2503.10291},
|
| 207 |
+
year={2025}
|
| 208 |
+
}
|
| 209 |
+
```
|
added_tokens.json
ADDED
|
@@ -0,0 +1,33 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"</box>": 151673,
|
| 3 |
+
"</img>": 151666,
|
| 4 |
+
"</quad>": 151669,
|
| 5 |
+
"</ref>": 151671,
|
| 6 |
+
"</tool_call>": 151658,
|
| 7 |
+
"<IMG_CONTEXT>": 151667,
|
| 8 |
+
"<box>": 151672,
|
| 9 |
+
"<img>": 151665,
|
| 10 |
+
"<quad>": 151668,
|
| 11 |
+
"<ref>": 151670,
|
| 12 |
+
"<tool_call>": 151657,
|
| 13 |
+
"<|box_end|>": 151649,
|
| 14 |
+
"<|box_start|>": 151648,
|
| 15 |
+
"<|endoftext|>": 151643,
|
| 16 |
+
"<|file_sep|>": 151664,
|
| 17 |
+
"<|fim_middle|>": 151660,
|
| 18 |
+
"<|fim_pad|>": 151662,
|
| 19 |
+
"<|fim_prefix|>": 151659,
|
| 20 |
+
"<|fim_suffix|>": 151661,
|
| 21 |
+
"<|im_end|>": 151645,
|
| 22 |
+
"<|im_start|>": 151644,
|
| 23 |
+
"<|image_pad|>": 151655,
|
| 24 |
+
"<|object_ref_end|>": 151647,
|
| 25 |
+
"<|object_ref_start|>": 151646,
|
| 26 |
+
"<|quad_end|>": 151651,
|
| 27 |
+
"<|quad_start|>": 151650,
|
| 28 |
+
"<|repo_name|>": 151663,
|
| 29 |
+
"<|video_pad|>": 151656,
|
| 30 |
+
"<|vision_end|>": 151653,
|
| 31 |
+
"<|vision_pad|>": 151654,
|
| 32 |
+
"<|vision_start|>": 151652
|
| 33 |
+
}
|
config.json
ADDED
|
@@ -0,0 +1,225 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"_commit_hash": null,
|
| 3 |
+
"_name_or_path": "/mnt/petrelfs/share_data/wangweiyun/share_internvl/InternVL3-8B-MPO",
|
| 4 |
+
"architectures": [
|
| 5 |
+
"InternVLRewardModel"
|
| 6 |
+
],
|
| 7 |
+
"auto_map": {
|
| 8 |
+
"AutoConfig": "configuration_internvl_chat.InternVLChatConfig",
|
| 9 |
+
"AutoModel": "modeling_internvl_chat.InternVLRewardModel",
|
| 10 |
+
"AutoModelForCausalLM": "modeling_internvl_chat.InternVLRewardModel"
|
| 11 |
+
},
|
| 12 |
+
"downsample_ratio": 0.5,
|
| 13 |
+
"dynamic_image_size": true,
|
| 14 |
+
"force_image_size": 448,
|
| 15 |
+
"hidden_size": 3584,
|
| 16 |
+
"image_fold": null,
|
| 17 |
+
"llm_config": {
|
| 18 |
+
"_attn_implementation_autoset": true,
|
| 19 |
+
"_name_or_path": "./pretrained/Qwen2.5-32B-Instruct",
|
| 20 |
+
"add_cross_attention": false,
|
| 21 |
+
"architectures": [
|
| 22 |
+
"Qwen2ForCausalLM"
|
| 23 |
+
],
|
| 24 |
+
"attention_dropout": 0.0,
|
| 25 |
+
"attn_implementation": "flash_attention_2",
|
| 26 |
+
"bad_words_ids": null,
|
| 27 |
+
"begin_suppress_tokens": null,
|
| 28 |
+
"bos_token_id": 151643,
|
| 29 |
+
"chunk_size_feed_forward": 0,
|
| 30 |
+
"cross_attention_hidden_size": null,
|
| 31 |
+
"decoder_start_token_id": null,
|
| 32 |
+
"diversity_penalty": 0.0,
|
| 33 |
+
"do_sample": false,
|
| 34 |
+
"early_stopping": false,
|
| 35 |
+
"encoder_no_repeat_ngram_size": 0,
|
| 36 |
+
"eos_token_id": 151643,
|
| 37 |
+
"exponential_decay_length_penalty": null,
|
| 38 |
+
"finetuning_task": null,
|
| 39 |
+
"forced_bos_token_id": null,
|
| 40 |
+
"forced_eos_token_id": null,
|
| 41 |
+
"hidden_act": "silu",
|
| 42 |
+
"hidden_size": 3584,
|
| 43 |
+
"id2label": {
|
| 44 |
+
"0": "LABEL_0",
|
| 45 |
+
"1": "LABEL_1"
|
| 46 |
+
},
|
| 47 |
+
"initializer_range": 0.02,
|
| 48 |
+
"intermediate_size": 18944,
|
| 49 |
+
"is_decoder": false,
|
| 50 |
+
"is_encoder_decoder": false,
|
| 51 |
+
"label2id": {
|
| 52 |
+
"LABEL_0": 0,
|
| 53 |
+
"LABEL_1": 1
|
| 54 |
+
},
|
| 55 |
+
"length_penalty": 1.0,
|
| 56 |
+
"max_length": 20,
|
| 57 |
+
"max_position_embeddings": 32768,
|
| 58 |
+
"max_window_layers": 70,
|
| 59 |
+
"min_length": 0,
|
| 60 |
+
"model_type": "qwen2",
|
| 61 |
+
"moe_config": null,
|
| 62 |
+
"no_repeat_ngram_size": 0,
|
| 63 |
+
"num_attention_heads": 28,
|
| 64 |
+
"num_beam_groups": 1,
|
| 65 |
+
"num_beams": 1,
|
| 66 |
+
"num_hidden_layers": 28,
|
| 67 |
+
"num_key_value_heads": 4,
|
| 68 |
+
"num_return_sequences": 1,
|
| 69 |
+
"output_attentions": false,
|
| 70 |
+
"output_hidden_states": false,
|
| 71 |
+
"output_scores": false,
|
| 72 |
+
"pad_token_id": null,
|
| 73 |
+
"prefix": null,
|
| 74 |
+
"problem_type": null,
|
| 75 |
+
"pruned_heads": {},
|
| 76 |
+
"remove_invalid_values": false,
|
| 77 |
+
"repetition_penalty": 1.0,
|
| 78 |
+
"return_dict": true,
|
| 79 |
+
"return_dict_in_generate": false,
|
| 80 |
+
"rms_norm_eps": 1e-06,
|
| 81 |
+
"rope_scaling": {
|
| 82 |
+
"factor": 2.0,
|
| 83 |
+
"rope_type": "dynamic",
|
| 84 |
+
"type": "dynamic"
|
| 85 |
+
},
|
| 86 |
+
"rope_theta": 1000000.0,
|
| 87 |
+
"sep_token_id": null,
|
| 88 |
+
"sliding_window": null,
|
| 89 |
+
"suppress_tokens": null,
|
| 90 |
+
"task_specific_params": null,
|
| 91 |
+
"temperature": 1.0,
|
| 92 |
+
"tf_legacy_loss": false,
|
| 93 |
+
"tie_encoder_decoder": false,
|
| 94 |
+
"tie_word_embeddings": false,
|
| 95 |
+
"tokenizer_class": null,
|
| 96 |
+
"top_k": 50,
|
| 97 |
+
"top_p": 1.0,
|
| 98 |
+
"torch_dtype": "bfloat16",
|
| 99 |
+
"torchscript": false,
|
| 100 |
+
"transformers_version": "4.37.2",
|
| 101 |
+
"typical_p": 1.0,
|
| 102 |
+
"use_bfloat16": true,
|
| 103 |
+
"use_cache": false,
|
| 104 |
+
"use_sliding_window": false,
|
| 105 |
+
"vocab_size": 151674
|
| 106 |
+
},
|
| 107 |
+
"max_dynamic_patch": 12,
|
| 108 |
+
"min_dynamic_patch": 1,
|
| 109 |
+
"model_type": "internvl_chat",
|
| 110 |
+
"pad2square": false,
|
| 111 |
+
"ps_version": "v2",
|
| 112 |
+
"select_layer": -1,
|
| 113 |
+
"system_message": null,
|
| 114 |
+
"template": "internvl2_5",
|
| 115 |
+
"tie_word_embeddings": false,
|
| 116 |
+
"torch_dtype": "bfloat16",
|
| 117 |
+
"transformers_version": null,
|
| 118 |
+
"use_backbone_lora": 0,
|
| 119 |
+
"use_llm_lora": 0,
|
| 120 |
+
"use_thumbnail": true,
|
| 121 |
+
"vision_config": {
|
| 122 |
+
"_attn_implementation_autoset": true,
|
| 123 |
+
"_name_or_path": "OpenGVLab/InternViT-6B-448px-V1-5",
|
| 124 |
+
"add_cross_attention": false,
|
| 125 |
+
"architectures": [
|
| 126 |
+
"InternVisionModel"
|
| 127 |
+
],
|
| 128 |
+
"attention_dropout": 0.0,
|
| 129 |
+
"auto_map": {
|
| 130 |
+
"AutoConfig": "configuration_intern_vit.InternVisionConfig",
|
| 131 |
+
"AutoModel": "modeling_intern_vit.InternVisionModel"
|
| 132 |
+
},
|
| 133 |
+
"bad_words_ids": null,
|
| 134 |
+
"begin_suppress_tokens": null,
|
| 135 |
+
"bos_token_id": null,
|
| 136 |
+
"capacity_factor": 1.2,
|
| 137 |
+
"chunk_size_feed_forward": 0,
|
| 138 |
+
"cross_attention_hidden_size": null,
|
| 139 |
+
"decoder_start_token_id": null,
|
| 140 |
+
"diversity_penalty": 0.0,
|
| 141 |
+
"do_sample": false,
|
| 142 |
+
"drop_path_rate": 0.1,
|
| 143 |
+
"dropout": 0.0,
|
| 144 |
+
"early_stopping": false,
|
| 145 |
+
"encoder_no_repeat_ngram_size": 0,
|
| 146 |
+
"eos_token_id": null,
|
| 147 |
+
"eval_capacity_factor": 1.4,
|
| 148 |
+
"exponential_decay_length_penalty": null,
|
| 149 |
+
"finetuning_task": null,
|
| 150 |
+
"forced_bos_token_id": null,
|
| 151 |
+
"forced_eos_token_id": null,
|
| 152 |
+
"hidden_act": "gelu",
|
| 153 |
+
"hidden_size": 1024,
|
| 154 |
+
"id2label": {
|
| 155 |
+
"0": "LABEL_0",
|
| 156 |
+
"1": "LABEL_1"
|
| 157 |
+
},
|
| 158 |
+
"image_size": 448,
|
| 159 |
+
"initializer_factor": 0.1,
|
| 160 |
+
"initializer_range": 1e-10,
|
| 161 |
+
"intermediate_size": 4096,
|
| 162 |
+
"is_decoder": false,
|
| 163 |
+
"is_encoder_decoder": false,
|
| 164 |
+
"label2id": {
|
| 165 |
+
"LABEL_0": 0,
|
| 166 |
+
"LABEL_1": 1
|
| 167 |
+
},
|
| 168 |
+
"laux_allreduce": "all_nodes",
|
| 169 |
+
"layer_norm_eps": 1e-06,
|
| 170 |
+
"length_penalty": 1.0,
|
| 171 |
+
"max_length": 20,
|
| 172 |
+
"min_length": 0,
|
| 173 |
+
"model_type": "intern_vit_6b",
|
| 174 |
+
"moe_coeff_ratio": 0.5,
|
| 175 |
+
"moe_intermediate_size": 768,
|
| 176 |
+
"moe_output_scale": 4.0,
|
| 177 |
+
"no_repeat_ngram_size": 0,
|
| 178 |
+
"noisy_gate_policy": "RSample_before",
|
| 179 |
+
"norm_type": "layer_norm",
|
| 180 |
+
"num_attention_heads": 16,
|
| 181 |
+
"num_beam_groups": 1,
|
| 182 |
+
"num_beams": 1,
|
| 183 |
+
"num_channels": 3,
|
| 184 |
+
"num_experts": 8,
|
| 185 |
+
"num_hidden_layers": 24,
|
| 186 |
+
"num_return_sequences": 1,
|
| 187 |
+
"num_routed_experts": 4,
|
| 188 |
+
"num_shared_experts": 4,
|
| 189 |
+
"output_attentions": false,
|
| 190 |
+
"output_hidden_states": false,
|
| 191 |
+
"output_scores": false,
|
| 192 |
+
"pad_token_id": null,
|
| 193 |
+
"patch_size": 14,
|
| 194 |
+
"prefix": null,
|
| 195 |
+
"problem_type": null,
|
| 196 |
+
"pruned_heads": {},
|
| 197 |
+
"qk_normalization": false,
|
| 198 |
+
"qkv_bias": true,
|
| 199 |
+
"remove_invalid_values": false,
|
| 200 |
+
"repetition_penalty": 1.0,
|
| 201 |
+
"return_dict": true,
|
| 202 |
+
"return_dict_in_generate": false,
|
| 203 |
+
"sep_token_id": null,
|
| 204 |
+
"shared_expert_intermediate_size": 3072,
|
| 205 |
+
"suppress_tokens": null,
|
| 206 |
+
"task_specific_params": null,
|
| 207 |
+
"temperature": 1.0,
|
| 208 |
+
"tf_legacy_loss": false,
|
| 209 |
+
"tie_encoder_decoder": false,
|
| 210 |
+
"tie_word_embeddings": true,
|
| 211 |
+
"tokenizer_class": null,
|
| 212 |
+
"top_k": 50,
|
| 213 |
+
"top_p": 1.0,
|
| 214 |
+
"torch_dtype": "bfloat16",
|
| 215 |
+
"torchscript": false,
|
| 216 |
+
"transformers_version": "4.37.2",
|
| 217 |
+
"typical_p": 1.0,
|
| 218 |
+
"use_bfloat16": true,
|
| 219 |
+
"use_flash_attn": true,
|
| 220 |
+
"use_moe": false,
|
| 221 |
+
"use_residual": true,
|
| 222 |
+
"use_rts": false,
|
| 223 |
+
"use_weighted_residual": false
|
| 224 |
+
}
|
| 225 |
+
}
|
configuration_intern_vit.py
ADDED
|
@@ -0,0 +1,120 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# --------------------------------------------------------
|
| 2 |
+
# InternVL
|
| 3 |
+
# Copyright (c) 2024 OpenGVLab
|
| 4 |
+
# Licensed under The MIT License [see LICENSE for details]
|
| 5 |
+
# --------------------------------------------------------
|
| 6 |
+
|
| 7 |
+
import os
|
| 8 |
+
from typing import Union
|
| 9 |
+
|
| 10 |
+
from transformers.configuration_utils import PretrainedConfig
|
| 11 |
+
from transformers.utils import logging
|
| 12 |
+
|
| 13 |
+
logger = logging.get_logger(__name__)
|
| 14 |
+
|
| 15 |
+
|
| 16 |
+
class InternVisionConfig(PretrainedConfig):
|
| 17 |
+
r"""
|
| 18 |
+
This is the configuration class to store the configuration of a [`InternVisionModel`]. It is used to
|
| 19 |
+
instantiate a vision encoder according to the specified arguments, defining the model architecture.
|
| 20 |
+
|
| 21 |
+
Configuration objects inherit from [`PretrainedConfig`] and can be used to control the model outputs. Read the
|
| 22 |
+
documentation from [`PretrainedConfig`] for more information.
|
| 23 |
+
|
| 24 |
+
Args:
|
| 25 |
+
num_channels (`int`, *optional*, defaults to 3):
|
| 26 |
+
Number of color channels in the input images (e.g., 3 for RGB).
|
| 27 |
+
patch_size (`int`, *optional*, defaults to 14):
|
| 28 |
+
The size (resolution) of each patch.
|
| 29 |
+
image_size (`int`, *optional*, defaults to 224):
|
| 30 |
+
The size (resolution) of each image.
|
| 31 |
+
qkv_bias (`bool`, *optional*, defaults to `False`):
|
| 32 |
+
Whether to add a bias to the queries and values in the self-attention layers.
|
| 33 |
+
hidden_size (`int`, *optional*, defaults to 3200):
|
| 34 |
+
Dimensionality of the encoder layers and the pooler layer.
|
| 35 |
+
num_attention_heads (`int`, *optional*, defaults to 25):
|
| 36 |
+
Number of attention heads for each attention layer in the Transformer encoder.
|
| 37 |
+
intermediate_size (`int`, *optional*, defaults to 12800):
|
| 38 |
+
Dimensionality of the "intermediate" (i.e., feed-forward) layer in the Transformer encoder.
|
| 39 |
+
qk_normalization (`bool`, *optional*, defaults to `True`):
|
| 40 |
+
Whether to normalize the queries and keys in the self-attention layers.
|
| 41 |
+
num_hidden_layers (`int`, *optional*, defaults to 48):
|
| 42 |
+
Number of hidden layers in the Transformer encoder.
|
| 43 |
+
use_flash_attn (`bool`, *optional*, defaults to `True`):
|
| 44 |
+
Whether to use flash attention mechanism.
|
| 45 |
+
hidden_act (`str` or `function`, *optional*, defaults to `"gelu"`):
|
| 46 |
+
The non-linear activation function (function or string) in the encoder and pooler. If string, `"gelu"`,
|
| 47 |
+
`"relu"`, `"selu"` and `"gelu_new"` ``"gelu"` are supported.
|
| 48 |
+
layer_norm_eps (`float`, *optional*, defaults to 1e-6):
|
| 49 |
+
The epsilon used by the layer normalization layers.
|
| 50 |
+
dropout (`float`, *optional*, defaults to 0.0):
|
| 51 |
+
The dropout probability for all fully connected layers in the embeddings, encoder, and pooler.
|
| 52 |
+
drop_path_rate (`float`, *optional*, defaults to 0.0):
|
| 53 |
+
Dropout rate for stochastic depth.
|
| 54 |
+
attention_dropout (`float`, *optional*, defaults to 0.0):
|
| 55 |
+
The dropout ratio for the attention probabilities.
|
| 56 |
+
initializer_range (`float`, *optional*, defaults to 0.02):
|
| 57 |
+
The standard deviation of the truncated_normal_initializer for initializing all weight matrices.
|
| 58 |
+
initializer_factor (`float`, *optional*, defaults to 0.1):
|
| 59 |
+
A factor for layer scale.
|
| 60 |
+
"""
|
| 61 |
+
|
| 62 |
+
model_type = 'intern_vit_6b'
|
| 63 |
+
|
| 64 |
+
def __init__(
|
| 65 |
+
self,
|
| 66 |
+
num_channels=3,
|
| 67 |
+
patch_size=14,
|
| 68 |
+
image_size=224,
|
| 69 |
+
qkv_bias=False,
|
| 70 |
+
hidden_size=3200,
|
| 71 |
+
num_attention_heads=25,
|
| 72 |
+
intermediate_size=12800,
|
| 73 |
+
qk_normalization=True,
|
| 74 |
+
num_hidden_layers=48,
|
| 75 |
+
use_flash_attn=True,
|
| 76 |
+
hidden_act='gelu',
|
| 77 |
+
norm_type='rms_norm',
|
| 78 |
+
layer_norm_eps=1e-6,
|
| 79 |
+
dropout=0.0,
|
| 80 |
+
drop_path_rate=0.0,
|
| 81 |
+
attention_dropout=0.0,
|
| 82 |
+
initializer_range=0.02,
|
| 83 |
+
initializer_factor=0.1,
|
| 84 |
+
**kwargs,
|
| 85 |
+
):
|
| 86 |
+
super().__init__(**kwargs)
|
| 87 |
+
|
| 88 |
+
self.hidden_size = hidden_size
|
| 89 |
+
self.intermediate_size = intermediate_size
|
| 90 |
+
self.dropout = dropout
|
| 91 |
+
self.drop_path_rate = drop_path_rate
|
| 92 |
+
self.num_hidden_layers = num_hidden_layers
|
| 93 |
+
self.num_attention_heads = num_attention_heads
|
| 94 |
+
self.num_channels = num_channels
|
| 95 |
+
self.patch_size = patch_size
|
| 96 |
+
self.image_size = image_size
|
| 97 |
+
self.initializer_range = initializer_range
|
| 98 |
+
self.initializer_factor = initializer_factor
|
| 99 |
+
self.attention_dropout = attention_dropout
|
| 100 |
+
self.layer_norm_eps = layer_norm_eps
|
| 101 |
+
self.hidden_act = hidden_act
|
| 102 |
+
self.norm_type = norm_type
|
| 103 |
+
self.qkv_bias = qkv_bias
|
| 104 |
+
self.qk_normalization = qk_normalization
|
| 105 |
+
self.use_flash_attn = use_flash_attn
|
| 106 |
+
|
| 107 |
+
@classmethod
|
| 108 |
+
def from_pretrained(cls, pretrained_model_name_or_path: Union[str, os.PathLike], **kwargs) -> 'PretrainedConfig':
|
| 109 |
+
config_dict, kwargs = cls.get_config_dict(pretrained_model_name_or_path, **kwargs)
|
| 110 |
+
|
| 111 |
+
if 'vision_config' in config_dict:
|
| 112 |
+
config_dict = config_dict['vision_config']
|
| 113 |
+
|
| 114 |
+
if 'model_type' in config_dict and hasattr(cls, 'model_type') and config_dict['model_type'] != cls.model_type:
|
| 115 |
+
logger.warning(
|
| 116 |
+
f"You are using a model of type {config_dict['model_type']} to instantiate a model of type "
|
| 117 |
+
f'{cls.model_type}. This is not supported for all configurations of models and can yield errors.'
|
| 118 |
+
)
|
| 119 |
+
|
| 120 |
+
return cls.from_dict(config_dict, **kwargs)
|
configuration_internvl_chat.py
ADDED
|
@@ -0,0 +1,97 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# --------------------------------------------------------
|
| 2 |
+
# InternVL
|
| 3 |
+
# Copyright (c) 2024 OpenGVLab
|
| 4 |
+
# Licensed under The MIT License [see LICENSE for details]
|
| 5 |
+
# --------------------------------------------------------
|
| 6 |
+
|
| 7 |
+
import copy
|
| 8 |
+
|
| 9 |
+
from transformers import AutoConfig, LlamaConfig, Qwen2Config
|
| 10 |
+
from transformers.configuration_utils import PretrainedConfig
|
| 11 |
+
from transformers.utils import logging
|
| 12 |
+
|
| 13 |
+
from .configuration_intern_vit import InternVisionConfig
|
| 14 |
+
|
| 15 |
+
logger = logging.get_logger(__name__)
|
| 16 |
+
|
| 17 |
+
|
| 18 |
+
class InternVLChatConfig(PretrainedConfig):
|
| 19 |
+
model_type = 'internvl_chat'
|
| 20 |
+
is_composition = True
|
| 21 |
+
|
| 22 |
+
def __init__(
|
| 23 |
+
self,
|
| 24 |
+
vision_config=None,
|
| 25 |
+
llm_config=None,
|
| 26 |
+
use_backbone_lora=0,
|
| 27 |
+
use_llm_lora=0,
|
| 28 |
+
select_layer=-1,
|
| 29 |
+
force_image_size=None,
|
| 30 |
+
downsample_ratio=0.5,
|
| 31 |
+
template=None,
|
| 32 |
+
dynamic_image_size=False,
|
| 33 |
+
use_thumbnail=False,
|
| 34 |
+
ps_version='v1',
|
| 35 |
+
min_dynamic_patch=1,
|
| 36 |
+
max_dynamic_patch=6,
|
| 37 |
+
**kwargs):
|
| 38 |
+
super().__init__(**kwargs)
|
| 39 |
+
|
| 40 |
+
if vision_config is None:
|
| 41 |
+
vision_config = {'architectures': ['InternVisionModel']}
|
| 42 |
+
logger.info('vision_config is None. Initializing the InternVisionConfig with default values.')
|
| 43 |
+
|
| 44 |
+
if llm_config is None:
|
| 45 |
+
llm_config = {'architectures': ['Qwen2ForCausalLM']}
|
| 46 |
+
logger.info('llm_config is None. Initializing the LlamaConfig config with default values (`LlamaConfig`).')
|
| 47 |
+
|
| 48 |
+
self.vision_config = InternVisionConfig(**vision_config)
|
| 49 |
+
if llm_config.get('architectures')[0] == 'LlamaForCausalLM':
|
| 50 |
+
self.llm_config = LlamaConfig(**llm_config)
|
| 51 |
+
elif llm_config.get('architectures')[0] == 'Qwen2ForCausalLM':
|
| 52 |
+
self.llm_config = Qwen2Config(**llm_config)
|
| 53 |
+
else:
|
| 54 |
+
raise ValueError('Unsupported architecture: {}'.format(llm_config.get('architectures')[0]))
|
| 55 |
+
self.use_backbone_lora = use_backbone_lora
|
| 56 |
+
self.use_llm_lora = use_llm_lora
|
| 57 |
+
self.select_layer = select_layer
|
| 58 |
+
self.force_image_size = force_image_size
|
| 59 |
+
self.downsample_ratio = downsample_ratio
|
| 60 |
+
self.template = template
|
| 61 |
+
self.dynamic_image_size = dynamic_image_size
|
| 62 |
+
self.use_thumbnail = use_thumbnail
|
| 63 |
+
self.ps_version = ps_version # pixel shuffle version
|
| 64 |
+
self.min_dynamic_patch = min_dynamic_patch
|
| 65 |
+
self.max_dynamic_patch = max_dynamic_patch
|
| 66 |
+
# By default, we use tie_word_embeddings=False for models of all sizes.
|
| 67 |
+
self.tie_word_embeddings = self.llm_config.tie_word_embeddings
|
| 68 |
+
|
| 69 |
+
logger.info(f'vision_select_layer: {self.select_layer}')
|
| 70 |
+
logger.info(f'ps_version: {self.ps_version}')
|
| 71 |
+
logger.info(f'min_dynamic_patch: {self.min_dynamic_patch}')
|
| 72 |
+
logger.info(f'max_dynamic_patch: {self.max_dynamic_patch}')
|
| 73 |
+
|
| 74 |
+
def to_dict(self):
|
| 75 |
+
"""
|
| 76 |
+
Serializes this instance to a Python dictionary. Override the default [`~PretrainedConfig.to_dict`].
|
| 77 |
+
|
| 78 |
+
Returns:
|
| 79 |
+
`Dict[str, any]`: Dictionary of all the attributes that make up this configuration instance,
|
| 80 |
+
"""
|
| 81 |
+
output = copy.deepcopy(self.__dict__)
|
| 82 |
+
output['vision_config'] = self.vision_config.to_dict()
|
| 83 |
+
output['llm_config'] = self.llm_config.to_dict()
|
| 84 |
+
output['model_type'] = self.__class__.model_type
|
| 85 |
+
output['use_backbone_lora'] = self.use_backbone_lora
|
| 86 |
+
output['use_llm_lora'] = self.use_llm_lora
|
| 87 |
+
output['select_layer'] = self.select_layer
|
| 88 |
+
output['force_image_size'] = self.force_image_size
|
| 89 |
+
output['downsample_ratio'] = self.downsample_ratio
|
| 90 |
+
output['template'] = self.template
|
| 91 |
+
output['dynamic_image_size'] = self.dynamic_image_size
|
| 92 |
+
output['use_thumbnail'] = self.use_thumbnail
|
| 93 |
+
output['ps_version'] = self.ps_version
|
| 94 |
+
output['min_dynamic_patch'] = self.min_dynamic_patch
|
| 95 |
+
output['max_dynamic_patch'] = self.max_dynamic_patch
|
| 96 |
+
|
| 97 |
+
return output
|
conversation.py
ADDED
|
@@ -0,0 +1,391 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""
|
| 2 |
+
Conversation prompt templates.
|
| 3 |
+
|
| 4 |
+
We kindly request that you import fastchat instead of copying this file if you wish to use it.
|
| 5 |
+
If you have changes in mind, please contribute back so the community can benefit collectively and continue to maintain these valuable templates.
|
| 6 |
+
|
| 7 |
+
Modified from https://github.com/lm-sys/FastChat/blob/main/fastchat/conversation.py
|
| 8 |
+
"""
|
| 9 |
+
|
| 10 |
+
import dataclasses
|
| 11 |
+
from enum import IntEnum, auto
|
| 12 |
+
from typing import Dict, List, Tuple, Union
|
| 13 |
+
|
| 14 |
+
|
| 15 |
+
class SeparatorStyle(IntEnum):
|
| 16 |
+
"""Separator styles."""
|
| 17 |
+
|
| 18 |
+
ADD_COLON_SINGLE = auto()
|
| 19 |
+
ADD_COLON_TWO = auto()
|
| 20 |
+
ADD_COLON_SPACE_SINGLE = auto()
|
| 21 |
+
NO_COLON_SINGLE = auto()
|
| 22 |
+
NO_COLON_TWO = auto()
|
| 23 |
+
ADD_NEW_LINE_SINGLE = auto()
|
| 24 |
+
LLAMA2 = auto()
|
| 25 |
+
CHATGLM = auto()
|
| 26 |
+
CHATML = auto()
|
| 27 |
+
CHATINTERN = auto()
|
| 28 |
+
DOLLY = auto()
|
| 29 |
+
RWKV = auto()
|
| 30 |
+
PHOENIX = auto()
|
| 31 |
+
ROBIN = auto()
|
| 32 |
+
FALCON_CHAT = auto()
|
| 33 |
+
CHATGLM3 = auto()
|
| 34 |
+
INTERNVL_ZH = auto()
|
| 35 |
+
MPT = auto()
|
| 36 |
+
|
| 37 |
+
|
| 38 |
+
@dataclasses.dataclass
|
| 39 |
+
class Conversation:
|
| 40 |
+
"""A class that manages prompt templates and keeps all conversation history."""
|
| 41 |
+
|
| 42 |
+
# The name of this template
|
| 43 |
+
name: str
|
| 44 |
+
# The template of the system prompt
|
| 45 |
+
system_template: str = '{system_message}'
|
| 46 |
+
# The system message
|
| 47 |
+
system_message: str = ''
|
| 48 |
+
# The names of two roles
|
| 49 |
+
roles: Tuple[str] = ('USER', 'ASSISTANT')
|
| 50 |
+
# All messages. Each item is (role, message).
|
| 51 |
+
messages: List[List[str]] = ()
|
| 52 |
+
# The number of few shot examples
|
| 53 |
+
offset: int = 0
|
| 54 |
+
# The separator style and configurations
|
| 55 |
+
sep_style: SeparatorStyle = SeparatorStyle.ADD_COLON_SINGLE
|
| 56 |
+
sep: str = '\n'
|
| 57 |
+
sep2: str = None
|
| 58 |
+
# Stop criteria (the default one is EOS token)
|
| 59 |
+
stop_str: Union[str, List[str]] = None
|
| 60 |
+
# Stops generation if meeting any token in this list
|
| 61 |
+
stop_token_ids: List[int] = None
|
| 62 |
+
|
| 63 |
+
def get_prompt(self) -> str:
|
| 64 |
+
"""Get the prompt for generation."""
|
| 65 |
+
system_prompt = self.system_template.format(system_message=self.system_message)
|
| 66 |
+
if self.sep_style == SeparatorStyle.ADD_COLON_SINGLE:
|
| 67 |
+
ret = system_prompt + self.sep
|
| 68 |
+
for role, message in self.messages:
|
| 69 |
+
if message:
|
| 70 |
+
ret += role + ': ' + message + self.sep
|
| 71 |
+
else:
|
| 72 |
+
ret += role + ':'
|
| 73 |
+
return ret
|
| 74 |
+
elif self.sep_style == SeparatorStyle.ADD_COLON_TWO:
|
| 75 |
+
seps = [self.sep, self.sep2]
|
| 76 |
+
ret = system_prompt + seps[0]
|
| 77 |
+
for i, (role, message) in enumerate(self.messages):
|
| 78 |
+
if message:
|
| 79 |
+
ret += role + ': ' + message + seps[i % 2]
|
| 80 |
+
else:
|
| 81 |
+
ret += role + ':'
|
| 82 |
+
return ret
|
| 83 |
+
elif self.sep_style == SeparatorStyle.ADD_COLON_SPACE_SINGLE:
|
| 84 |
+
ret = system_prompt + self.sep
|
| 85 |
+
for role, message in self.messages:
|
| 86 |
+
if message:
|
| 87 |
+
ret += role + ': ' + message + self.sep
|
| 88 |
+
else:
|
| 89 |
+
ret += role + ': ' # must be end with a space
|
| 90 |
+
return ret
|
| 91 |
+
elif self.sep_style == SeparatorStyle.ADD_NEW_LINE_SINGLE:
|
| 92 |
+
ret = '' if system_prompt == '' else system_prompt + self.sep
|
| 93 |
+
for role, message in self.messages:
|
| 94 |
+
if message:
|
| 95 |
+
ret += role + '\n' + message + self.sep
|
| 96 |
+
else:
|
| 97 |
+
ret += role + '\n'
|
| 98 |
+
return ret
|
| 99 |
+
elif self.sep_style == SeparatorStyle.NO_COLON_SINGLE:
|
| 100 |
+
ret = system_prompt
|
| 101 |
+
for role, message in self.messages:
|
| 102 |
+
if message:
|
| 103 |
+
ret += role + message + self.sep
|
| 104 |
+
else:
|
| 105 |
+
ret += role
|
| 106 |
+
return ret
|
| 107 |
+
elif self.sep_style == SeparatorStyle.NO_COLON_TWO:
|
| 108 |
+
seps = [self.sep, self.sep2]
|
| 109 |
+
ret = system_prompt
|
| 110 |
+
for i, (role, message) in enumerate(self.messages):
|
| 111 |
+
if message:
|
| 112 |
+
ret += role + message + seps[i % 2]
|
| 113 |
+
else:
|
| 114 |
+
ret += role
|
| 115 |
+
return ret
|
| 116 |
+
elif self.sep_style == SeparatorStyle.RWKV:
|
| 117 |
+
ret = system_prompt
|
| 118 |
+
for i, (role, message) in enumerate(self.messages):
|
| 119 |
+
if message:
|
| 120 |
+
ret += (
|
| 121 |
+
role
|
| 122 |
+
+ ': '
|
| 123 |
+
+ message.replace('\r\n', '\n').replace('\n\n', '\n')
|
| 124 |
+
)
|
| 125 |
+
ret += '\n\n'
|
| 126 |
+
else:
|
| 127 |
+
ret += role + ':'
|
| 128 |
+
return ret
|
| 129 |
+
elif self.sep_style == SeparatorStyle.LLAMA2:
|
| 130 |
+
seps = [self.sep, self.sep2]
|
| 131 |
+
if self.system_message:
|
| 132 |
+
ret = system_prompt
|
| 133 |
+
else:
|
| 134 |
+
ret = '[INST] '
|
| 135 |
+
for i, (role, message) in enumerate(self.messages):
|
| 136 |
+
tag = self.roles[i % 2]
|
| 137 |
+
if message:
|
| 138 |
+
if i == 0:
|
| 139 |
+
ret += message + ' '
|
| 140 |
+
else:
|
| 141 |
+
ret += tag + ' ' + message + seps[i % 2]
|
| 142 |
+
else:
|
| 143 |
+
ret += tag
|
| 144 |
+
return ret
|
| 145 |
+
elif self.sep_style == SeparatorStyle.CHATGLM:
|
| 146 |
+
# source: https://huggingface.co/THUDM/chatglm-6b/blob/1d240ba371910e9282298d4592532d7f0f3e9f3e/modeling_chatglm.py#L1302-L1308
|
| 147 |
+
# source2: https://huggingface.co/THUDM/chatglm2-6b/blob/e186c891cf64310ac66ef10a87e6635fa6c2a579/modeling_chatglm.py#L926
|
| 148 |
+
round_add_n = 1 if self.name == 'chatglm2' else 0
|
| 149 |
+
if system_prompt:
|
| 150 |
+
ret = system_prompt + self.sep
|
| 151 |
+
else:
|
| 152 |
+
ret = ''
|
| 153 |
+
|
| 154 |
+
for i, (role, message) in enumerate(self.messages):
|
| 155 |
+
if i % 2 == 0:
|
| 156 |
+
ret += f'[Round {i//2 + round_add_n}]{self.sep}'
|
| 157 |
+
|
| 158 |
+
if message:
|
| 159 |
+
ret += f'{role}:{message}{self.sep}'
|
| 160 |
+
else:
|
| 161 |
+
ret += f'{role}:'
|
| 162 |
+
return ret
|
| 163 |
+
elif self.sep_style == SeparatorStyle.CHATML:
|
| 164 |
+
ret = '' if system_prompt == '' else system_prompt + self.sep + '\n'
|
| 165 |
+
for role, message in self.messages:
|
| 166 |
+
if message:
|
| 167 |
+
ret += role + '\n' + message + self.sep + '\n'
|
| 168 |
+
else:
|
| 169 |
+
ret += role + '\n'
|
| 170 |
+
return ret
|
| 171 |
+
elif self.sep_style == SeparatorStyle.CHATGLM3:
|
| 172 |
+
ret = ''
|
| 173 |
+
if self.system_message:
|
| 174 |
+
ret += system_prompt
|
| 175 |
+
for role, message in self.messages:
|
| 176 |
+
if message:
|
| 177 |
+
ret += role + '\n' + ' ' + message
|
| 178 |
+
else:
|
| 179 |
+
ret += role
|
| 180 |
+
return ret
|
| 181 |
+
elif self.sep_style == SeparatorStyle.CHATINTERN:
|
| 182 |
+
# source: https://huggingface.co/internlm/internlm-chat-7b-8k/blob/bd546fa984b4b0b86958f56bf37f94aa75ab8831/modeling_internlm.py#L771
|
| 183 |
+
seps = [self.sep, self.sep2]
|
| 184 |
+
ret = system_prompt
|
| 185 |
+
for i, (role, message) in enumerate(self.messages):
|
| 186 |
+
# if i % 2 == 0:
|
| 187 |
+
# ret += "<s>"
|
| 188 |
+
if message:
|
| 189 |
+
ret += role + ':' + message + seps[i % 2] + '\n'
|
| 190 |
+
else:
|
| 191 |
+
ret += role + ':'
|
| 192 |
+
return ret
|
| 193 |
+
elif self.sep_style == SeparatorStyle.DOLLY:
|
| 194 |
+
seps = [self.sep, self.sep2]
|
| 195 |
+
ret = system_prompt
|
| 196 |
+
for i, (role, message) in enumerate(self.messages):
|
| 197 |
+
if message:
|
| 198 |
+
ret += role + ':\n' + message + seps[i % 2]
|
| 199 |
+
if i % 2 == 1:
|
| 200 |
+
ret += '\n\n'
|
| 201 |
+
else:
|
| 202 |
+
ret += role + ':\n'
|
| 203 |
+
return ret
|
| 204 |
+
elif self.sep_style == SeparatorStyle.PHOENIX:
|
| 205 |
+
ret = system_prompt
|
| 206 |
+
for role, message in self.messages:
|
| 207 |
+
if message:
|
| 208 |
+
ret += role + ': ' + '<s>' + message + '</s>'
|
| 209 |
+
else:
|
| 210 |
+
ret += role + ': ' + '<s>'
|
| 211 |
+
return ret
|
| 212 |
+
elif self.sep_style == SeparatorStyle.ROBIN:
|
| 213 |
+
ret = system_prompt + self.sep
|
| 214 |
+
for role, message in self.messages:
|
| 215 |
+
if message:
|
| 216 |
+
ret += role + ':\n' + message + self.sep
|
| 217 |
+
else:
|
| 218 |
+
ret += role + ':\n'
|
| 219 |
+
return ret
|
| 220 |
+
elif self.sep_style == SeparatorStyle.FALCON_CHAT:
|
| 221 |
+
ret = ''
|
| 222 |
+
if self.system_message:
|
| 223 |
+
ret += system_prompt + self.sep
|
| 224 |
+
for role, message in self.messages:
|
| 225 |
+
if message:
|
| 226 |
+
ret += role + ': ' + message + self.sep
|
| 227 |
+
else:
|
| 228 |
+
ret += role + ':'
|
| 229 |
+
|
| 230 |
+
return ret
|
| 231 |
+
elif self.sep_style == SeparatorStyle.INTERNVL_ZH:
|
| 232 |
+
seps = [self.sep, self.sep2]
|
| 233 |
+
ret = self.system_message + seps[0]
|
| 234 |
+
for i, (role, message) in enumerate(self.messages):
|
| 235 |
+
if message:
|
| 236 |
+
ret += role + ': ' + message + seps[i % 2]
|
| 237 |
+
else:
|
| 238 |
+
ret += role + ':'
|
| 239 |
+
return ret
|
| 240 |
+
elif self.sep_style == SeparatorStyle.MPT:
|
| 241 |
+
ret = system_prompt + self.sep
|
| 242 |
+
for role, message in self.messages:
|
| 243 |
+
if message:
|
| 244 |
+
if type(message) is tuple:
|
| 245 |
+
message, _, _ = message
|
| 246 |
+
ret += role + message + self.sep
|
| 247 |
+
else:
|
| 248 |
+
ret += role
|
| 249 |
+
return ret
|
| 250 |
+
else:
|
| 251 |
+
raise ValueError(f'Invalid style: {self.sep_style}')
|
| 252 |
+
|
| 253 |
+
def set_system_message(self, system_message: str):
|
| 254 |
+
"""Set the system message."""
|
| 255 |
+
self.system_message = system_message
|
| 256 |
+
|
| 257 |
+
def append_message(self, role: str, message: str):
|
| 258 |
+
"""Append a new message."""
|
| 259 |
+
self.messages.append([role, message])
|
| 260 |
+
|
| 261 |
+
def update_last_message(self, message: str):
|
| 262 |
+
"""Update the last output.
|
| 263 |
+
|
| 264 |
+
The last message is typically set to be None when constructing the prompt,
|
| 265 |
+
so we need to update it in-place after getting the response from a model.
|
| 266 |
+
"""
|
| 267 |
+
self.messages[-1][1] = message
|
| 268 |
+
|
| 269 |
+
def to_gradio_chatbot(self):
|
| 270 |
+
"""Convert the conversation to gradio chatbot format."""
|
| 271 |
+
ret = []
|
| 272 |
+
for i, (role, msg) in enumerate(self.messages[self.offset :]):
|
| 273 |
+
if i % 2 == 0:
|
| 274 |
+
ret.append([msg, None])
|
| 275 |
+
else:
|
| 276 |
+
ret[-1][-1] = msg
|
| 277 |
+
return ret
|
| 278 |
+
|
| 279 |
+
def to_openai_api_messages(self):
|
| 280 |
+
"""Convert the conversation to OpenAI chat completion format."""
|
| 281 |
+
ret = [{'role': 'system', 'content': self.system_message}]
|
| 282 |
+
|
| 283 |
+
for i, (_, msg) in enumerate(self.messages[self.offset :]):
|
| 284 |
+
if i % 2 == 0:
|
| 285 |
+
ret.append({'role': 'user', 'content': msg})
|
| 286 |
+
else:
|
| 287 |
+
if msg is not None:
|
| 288 |
+
ret.append({'role': 'assistant', 'content': msg})
|
| 289 |
+
return ret
|
| 290 |
+
|
| 291 |
+
def copy(self):
|
| 292 |
+
return Conversation(
|
| 293 |
+
name=self.name,
|
| 294 |
+
system_template=self.system_template,
|
| 295 |
+
system_message=self.system_message,
|
| 296 |
+
roles=self.roles,
|
| 297 |
+
messages=[[x, y] for x, y in self.messages],
|
| 298 |
+
offset=self.offset,
|
| 299 |
+
sep_style=self.sep_style,
|
| 300 |
+
sep=self.sep,
|
| 301 |
+
sep2=self.sep2,
|
| 302 |
+
stop_str=self.stop_str,
|
| 303 |
+
stop_token_ids=self.stop_token_ids,
|
| 304 |
+
)
|
| 305 |
+
|
| 306 |
+
def dict(self):
|
| 307 |
+
return {
|
| 308 |
+
'template_name': self.name,
|
| 309 |
+
'system_message': self.system_message,
|
| 310 |
+
'roles': self.roles,
|
| 311 |
+
'messages': self.messages,
|
| 312 |
+
'offset': self.offset,
|
| 313 |
+
}
|
| 314 |
+
|
| 315 |
+
|
| 316 |
+
# A global registry for all conversation templates
|
| 317 |
+
conv_templates: Dict[str, Conversation] = {}
|
| 318 |
+
|
| 319 |
+
|
| 320 |
+
def register_conv_template(template: Conversation, override: bool = False):
|
| 321 |
+
"""Register a new conversation template."""
|
| 322 |
+
if not override:
|
| 323 |
+
assert (
|
| 324 |
+
template.name not in conv_templates
|
| 325 |
+
), f'{template.name} has been registered.'
|
| 326 |
+
|
| 327 |
+
conv_templates[template.name] = template
|
| 328 |
+
|
| 329 |
+
|
| 330 |
+
def get_conv_template(name: str) -> Conversation:
|
| 331 |
+
"""Get a conversation template."""
|
| 332 |
+
return conv_templates[name].copy()
|
| 333 |
+
|
| 334 |
+
|
| 335 |
+
# Both Hermes-2 and internlm2-chat are chatml-format conversation templates. The difference
|
| 336 |
+
# is that during training, the preprocessing function for the Hermes-2 template doesn't add
|
| 337 |
+
# <s> at the beginning of the tokenized sequence, while the internlm2-chat template does.
|
| 338 |
+
# Therefore, they are completely equivalent during inference.
|
| 339 |
+
register_conv_template(
|
| 340 |
+
Conversation(
|
| 341 |
+
name='Hermes-2',
|
| 342 |
+
system_template='<|im_start|>system\n{system_message}',
|
| 343 |
+
# note: The new system prompt was not used here to avoid changes in benchmark performance.
|
| 344 |
+
# system_message='我是书生·万象,英文名是InternVL,是由上海人工智能实验室、清华大学及多家合作单位联合开发的多模态大语言模型。',
|
| 345 |
+
system_message='你是由上海人工智能实验室联合商汤科技开发的书生多模态大模型,英文名叫InternVL, 是一个有用无害的人工智能助手。',
|
| 346 |
+
roles=('<|im_start|>user\n', '<|im_start|>assistant\n'),
|
| 347 |
+
sep_style=SeparatorStyle.MPT,
|
| 348 |
+
sep='<|im_end|>',
|
| 349 |
+
stop_str='<|endoftext|>',
|
| 350 |
+
)
|
| 351 |
+
)
|
| 352 |
+
|
| 353 |
+
|
| 354 |
+
register_conv_template(
|
| 355 |
+
Conversation(
|
| 356 |
+
name='internlm2-chat',
|
| 357 |
+
system_template='<|im_start|>system\n{system_message}',
|
| 358 |
+
# note: The new system prompt was not used here to avoid changes in benchmark performance.
|
| 359 |
+
# system_message='我是书生·万象,英文名是InternVL,是由上海人工智能实验室、清华大学及多家合作单位联合开发的多模态大语言模型。',
|
| 360 |
+
system_message='你是由上海人工智能实验室联合商汤科技开发的书生多模态大模型,英文名叫InternVL, 是一个有用无害的人工智能助手。',
|
| 361 |
+
roles=('<|im_start|>user\n', '<|im_start|>assistant\n'),
|
| 362 |
+
sep_style=SeparatorStyle.MPT,
|
| 363 |
+
sep='<|im_end|>',
|
| 364 |
+
)
|
| 365 |
+
)
|
| 366 |
+
|
| 367 |
+
|
| 368 |
+
register_conv_template(
|
| 369 |
+
Conversation(
|
| 370 |
+
name='phi3-chat',
|
| 371 |
+
system_template='<|system|>\n{system_message}',
|
| 372 |
+
# note: The new system prompt was not used here to avoid changes in benchmark performance.
|
| 373 |
+
# system_message='我是书生·万象,英文名是InternVL,是由上海人工智能实验室、清华大学及多家合作单位联合开发的多模态大语言模型。',
|
| 374 |
+
system_message='你是由上海人工智能实验室联合商汤科技开发的书生多模态大模型,英文名叫InternVL, 是一个有用无害的人工智能助手。',
|
| 375 |
+
roles=('<|user|>\n', '<|assistant|>\n'),
|
| 376 |
+
sep_style=SeparatorStyle.MPT,
|
| 377 |
+
sep='<|end|>',
|
| 378 |
+
)
|
| 379 |
+
)
|
| 380 |
+
|
| 381 |
+
|
| 382 |
+
register_conv_template(
|
| 383 |
+
Conversation(
|
| 384 |
+
name='internvl2_5',
|
| 385 |
+
system_template='<|im_start|>system\n{system_message}',
|
| 386 |
+
system_message='你是书生·万象,英文名是InternVL,是由上海人工智能实验室、清华大学及多家合作单位联合开发的多模态大语言模型。',
|
| 387 |
+
roles=('<|im_start|>user\n', '<|im_start|>assistant\n'),
|
| 388 |
+
sep_style=SeparatorStyle.MPT,
|
| 389 |
+
sep='<|im_end|>\n',
|
| 390 |
+
)
|
| 391 |
+
)
|
examples/image.png
ADDED

|
generation_config.json
ADDED
|
@@ -0,0 +1,4 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"_from_model_config": true,
|
| 3 |
+
"transformers_version": "4.37.2"
|
| 4 |
+
}
|
merges.txt
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
model-00001-of-00004.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:7837c6ad2de487324836545b6761d9260fccb8983147453cf71771a7c8e8dc3a
|
| 3 |
+
size 4991123960
|
model-00002-of-00004.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:b718a6fe40ec0feff64fe11684140654a1cd68084c67c95c57e55d94e23a2a01
|
| 3 |
+
size 4958443072
|
model-00003-of-00004.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:a5129c058ef84053ec8316cc9d5e7621e12c7a6f7cc22d7f43a2306e14a947a5
|
| 3 |
+
size 4796984024
|
model-00004-of-00004.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:8a6d51ce50635af4d524d7d3f5f7ee5027b232eb14fa3859338f5c5feb55d6bc
|
| 3 |
+
size 1142280864
|
model.safetensors.index.json
ADDED
|
@@ -0,0 +1,692 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"metadata": {
|
| 3 |
+
"total_size": 15888747520
|
| 4 |
+
},
|
| 5 |
+
"weight_map": {
|
| 6 |
+
"language_model.lm_head.weight": "model-00004-of-00004.safetensors",
|
| 7 |
+
"language_model.model.embed_tokens.weight": "model-00001-of-00004.safetensors",
|
| 8 |
+
"language_model.model.layers.0.input_layernorm.weight": "model-00001-of-00004.safetensors",
|
| 9 |
+
"language_model.model.layers.0.mlp.down_proj.weight": "model-00001-of-00004.safetensors",
|
| 10 |
+
"language_model.model.layers.0.mlp.gate_proj.weight": "model-00001-of-00004.safetensors",
|
| 11 |
+
"language_model.model.layers.0.mlp.up_proj.weight": "model-00001-of-00004.safetensors",
|
| 12 |
+
"language_model.model.layers.0.post_attention_layernorm.weight": "model-00001-of-00004.safetensors",
|
| 13 |
+
"language_model.model.layers.0.self_attn.k_proj.bias": "model-00001-of-00004.safetensors",
|
| 14 |
+
"language_model.model.layers.0.self_attn.k_proj.weight": "model-00001-of-00004.safetensors",
|
| 15 |
+
"language_model.model.layers.0.self_attn.o_proj.weight": "model-00001-of-00004.safetensors",
|
| 16 |
+
"language_model.model.layers.0.self_attn.q_proj.bias": "model-00001-of-00004.safetensors",
|
| 17 |
+
"language_model.model.layers.0.self_attn.q_proj.weight": "model-00001-of-00004.safetensors",
|
| 18 |
+
"language_model.model.layers.0.self_attn.v_proj.bias": "model-00001-of-00004.safetensors",
|
| 19 |
+
"language_model.model.layers.0.self_attn.v_proj.weight": "model-00001-of-00004.safetensors",
|
| 20 |
+
"language_model.model.layers.1.input_layernorm.weight": "model-00001-of-00004.safetensors",
|
| 21 |
+
"language_model.model.layers.1.mlp.down_proj.weight": "model-00001-of-00004.safetensors",
|
| 22 |
+
"language_model.model.layers.1.mlp.gate_proj.weight": "model-00001-of-00004.safetensors",
|
| 23 |
+
"language_model.model.layers.1.mlp.up_proj.weight": "model-00001-of-00004.safetensors",
|
| 24 |
+
"language_model.model.layers.1.post_attention_layernorm.weight": "model-00001-of-00004.safetensors",
|
| 25 |
+
"language_model.model.layers.1.self_attn.k_proj.bias": "model-00001-of-00004.safetensors",
|
| 26 |
+
"language_model.model.layers.1.self_attn.k_proj.weight": "model-00001-of-00004.safetensors",
|
| 27 |
+
"language_model.model.layers.1.self_attn.o_proj.weight": "model-00001-of-00004.safetensors",
|
| 28 |
+
"language_model.model.layers.1.self_attn.q_proj.bias": "model-00001-of-00004.safetensors",
|
| 29 |
+
"language_model.model.layers.1.self_attn.q_proj.weight": "model-00001-of-00004.safetensors",
|
| 30 |
+
"language_model.model.layers.1.self_attn.v_proj.bias": "model-00001-of-00004.safetensors",
|
| 31 |
+
"language_model.model.layers.1.self_attn.v_proj.weight": "model-00001-of-00004.safetensors",
|
| 32 |
+
"language_model.model.layers.10.input_layernorm.weight": "model-00002-of-00004.safetensors",
|
| 33 |
+
"language_model.model.layers.10.mlp.down_proj.weight": "model-00002-of-00004.safetensors",
|
| 34 |
+
"language_model.model.layers.10.mlp.gate_proj.weight": "model-00002-of-00004.safetensors",
|
| 35 |
+
"language_model.model.layers.10.mlp.up_proj.weight": "model-00002-of-00004.safetensors",
|
| 36 |
+
"language_model.model.layers.10.post_attention_layernorm.weight": "model-00002-of-00004.safetensors",
|
| 37 |
+
"language_model.model.layers.10.self_attn.k_proj.bias": "model-00002-of-00004.safetensors",
|
| 38 |
+
"language_model.model.layers.10.self_attn.k_proj.weight": "model-00002-of-00004.safetensors",
|
| 39 |
+
"language_model.model.layers.10.self_attn.o_proj.weight": "model-00002-of-00004.safetensors",
|
| 40 |
+
"language_model.model.layers.10.self_attn.q_proj.bias": "model-00002-of-00004.safetensors",
|
| 41 |
+
"language_model.model.layers.10.self_attn.q_proj.weight": "model-00002-of-00004.safetensors",
|
| 42 |
+
"language_model.model.layers.10.self_attn.v_proj.bias": "model-00002-of-00004.safetensors",
|
| 43 |
+
"language_model.model.layers.10.self_attn.v_proj.weight": "model-00002-of-00004.safetensors",
|
| 44 |
+
"language_model.model.layers.11.input_layernorm.weight": "model-00002-of-00004.safetensors",
|
| 45 |
+
"language_model.model.layers.11.mlp.down_proj.weight": "model-00002-of-00004.safetensors",
|
| 46 |
+
"language_model.model.layers.11.mlp.gate_proj.weight": "model-00002-of-00004.safetensors",
|
| 47 |
+
"language_model.model.layers.11.mlp.up_proj.weight": "model-00002-of-00004.safetensors",
|
| 48 |
+
"language_model.model.layers.11.post_attention_layernorm.weight": "model-00002-of-00004.safetensors",
|
| 49 |
+
"language_model.model.layers.11.self_attn.k_proj.bias": "model-00002-of-00004.safetensors",
|
| 50 |
+
"language_model.model.layers.11.self_attn.k_proj.weight": "model-00002-of-00004.safetensors",
|
| 51 |
+
"language_model.model.layers.11.self_attn.o_proj.weight": "model-00002-of-00004.safetensors",
|
| 52 |
+
"language_model.model.layers.11.self_attn.q_proj.bias": "model-00002-of-00004.safetensors",
|
| 53 |
+
"language_model.model.layers.11.self_attn.q_proj.weight": "model-00002-of-00004.safetensors",
|
| 54 |
+
"language_model.model.layers.11.self_attn.v_proj.bias": "model-00002-of-00004.safetensors",
|
| 55 |
+
"language_model.model.layers.11.self_attn.v_proj.weight": "model-00002-of-00004.safetensors",
|
| 56 |
+
"language_model.model.layers.12.input_layernorm.weight": "model-00002-of-00004.safetensors",
|
| 57 |
+
"language_model.model.layers.12.mlp.down_proj.weight": "model-00002-of-00004.safetensors",
|
| 58 |
+
"language_model.model.layers.12.mlp.gate_proj.weight": "model-00002-of-00004.safetensors",
|
| 59 |
+
"language_model.model.layers.12.mlp.up_proj.weight": "model-00002-of-00004.safetensors",
|
| 60 |
+
"language_model.model.layers.12.post_attention_layernorm.weight": "model-00002-of-00004.safetensors",
|
| 61 |
+
"language_model.model.layers.12.self_attn.k_proj.bias": "model-00002-of-00004.safetensors",
|
| 62 |
+
"language_model.model.layers.12.self_attn.k_proj.weight": "model-00002-of-00004.safetensors",
|
| 63 |
+
"language_model.model.layers.12.self_attn.o_proj.weight": "model-00002-of-00004.safetensors",
|
| 64 |
+
"language_model.model.layers.12.self_attn.q_proj.bias": "model-00002-of-00004.safetensors",
|
| 65 |
+
"language_model.model.layers.12.self_attn.q_proj.weight": "model-00002-of-00004.safetensors",
|
| 66 |
+
"language_model.model.layers.12.self_attn.v_proj.bias": "model-00002-of-00004.safetensors",
|
| 67 |
+
"language_model.model.layers.12.self_attn.v_proj.weight": "model-00002-of-00004.safetensors",
|
| 68 |
+
"language_model.model.layers.13.input_layernorm.weight": "model-00002-of-00004.safetensors",
|
| 69 |
+
"language_model.model.layers.13.mlp.down_proj.weight": "model-00002-of-00004.safetensors",
|
| 70 |
+
"language_model.model.layers.13.mlp.gate_proj.weight": "model-00002-of-00004.safetensors",
|
| 71 |
+
"language_model.model.layers.13.mlp.up_proj.weight": "model-00002-of-00004.safetensors",
|
| 72 |
+
"language_model.model.layers.13.post_attention_layernorm.weight": "model-00002-of-00004.safetensors",
|
| 73 |
+
"language_model.model.layers.13.self_attn.k_proj.bias": "model-00002-of-00004.safetensors",
|
| 74 |
+
"language_model.model.layers.13.self_attn.k_proj.weight": "model-00002-of-00004.safetensors",
|
| 75 |
+
"language_model.model.layers.13.self_attn.o_proj.weight": "model-00002-of-00004.safetensors",
|
| 76 |
+
"language_model.model.layers.13.self_attn.q_proj.bias": "model-00002-of-00004.safetensors",
|
| 77 |
+
"language_model.model.layers.13.self_attn.q_proj.weight": "model-00002-of-00004.safetensors",
|
| 78 |
+
"language_model.model.layers.13.self_attn.v_proj.bias": "model-00002-of-00004.safetensors",
|
| 79 |
+
"language_model.model.layers.13.self_attn.v_proj.weight": "model-00002-of-00004.safetensors",
|
| 80 |
+
"language_model.model.layers.14.input_layernorm.weight": "model-00002-of-00004.safetensors",
|
| 81 |
+
"language_model.model.layers.14.mlp.down_proj.weight": "model-00002-of-00004.safetensors",
|
| 82 |
+
"language_model.model.layers.14.mlp.gate_proj.weight": "model-00002-of-00004.safetensors",
|
| 83 |
+
"language_model.model.layers.14.mlp.up_proj.weight": "model-00002-of-00004.safetensors",
|
| 84 |
+
"language_model.model.layers.14.post_attention_layernorm.weight": "model-00002-of-00004.safetensors",
|
| 85 |
+
"language_model.model.layers.14.self_attn.k_proj.bias": "model-00002-of-00004.safetensors",
|
| 86 |
+
"language_model.model.layers.14.self_attn.k_proj.weight": "model-00002-of-00004.safetensors",
|
| 87 |
+
"language_model.model.layers.14.self_attn.o_proj.weight": "model-00002-of-00004.safetensors",
|
| 88 |
+
"language_model.model.layers.14.self_attn.q_proj.bias": "model-00002-of-00004.safetensors",
|
| 89 |
+
"language_model.model.layers.14.self_attn.q_proj.weight": "model-00002-of-00004.safetensors",
|
| 90 |
+
"language_model.model.layers.14.self_attn.v_proj.bias": "model-00002-of-00004.safetensors",
|
| 91 |
+
"language_model.model.layers.14.self_attn.v_proj.weight": "model-00002-of-00004.safetensors",
|
| 92 |
+
"language_model.model.layers.15.input_layernorm.weight": "model-00002-of-00004.safetensors",
|
| 93 |
+
"language_model.model.layers.15.mlp.down_proj.weight": "model-00002-of-00004.safetensors",
|
| 94 |
+
"language_model.model.layers.15.mlp.gate_proj.weight": "model-00002-of-00004.safetensors",
|
| 95 |
+
"language_model.model.layers.15.mlp.up_proj.weight": "model-00002-of-00004.safetensors",
|
| 96 |
+
"language_model.model.layers.15.post_attention_layernorm.weight": "model-00002-of-00004.safetensors",
|
| 97 |
+
"language_model.model.layers.15.self_attn.k_proj.bias": "model-00002-of-00004.safetensors",
|
| 98 |
+
"language_model.model.layers.15.self_attn.k_proj.weight": "model-00002-of-00004.safetensors",
|
| 99 |
+
"language_model.model.layers.15.self_attn.o_proj.weight": "model-00002-of-00004.safetensors",
|
| 100 |
+
"language_model.model.layers.15.self_attn.q_proj.bias": "model-00002-of-00004.safetensors",
|
| 101 |
+
"language_model.model.layers.15.self_attn.q_proj.weight": "model-00002-of-00004.safetensors",
|
| 102 |
+
"language_model.model.layers.15.self_attn.v_proj.bias": "model-00002-of-00004.safetensors",
|
| 103 |
+
"language_model.model.layers.15.self_attn.v_proj.weight": "model-00002-of-00004.safetensors",
|
| 104 |
+
"language_model.model.layers.16.input_layernorm.weight": "model-00002-of-00004.safetensors",
|
| 105 |
+
"language_model.model.layers.16.mlp.down_proj.weight": "model-00002-of-00004.safetensors",
|
| 106 |
+
"language_model.model.layers.16.mlp.gate_proj.weight": "model-00002-of-00004.safetensors",
|
| 107 |
+
"language_model.model.layers.16.mlp.up_proj.weight": "model-00002-of-00004.safetensors",
|
| 108 |
+
"language_model.model.layers.16.post_attention_layernorm.weight": "model-00002-of-00004.safetensors",
|
| 109 |
+
"language_model.model.layers.16.self_attn.k_proj.bias": "model-00002-of-00004.safetensors",
|
| 110 |
+
"language_model.model.layers.16.self_attn.k_proj.weight": "model-00002-of-00004.safetensors",
|
| 111 |
+
"language_model.model.layers.16.self_attn.o_proj.weight": "model-00002-of-00004.safetensors",
|
| 112 |
+
"language_model.model.layers.16.self_attn.q_proj.bias": "model-00002-of-00004.safetensors",
|
| 113 |
+
"language_model.model.layers.16.self_attn.q_proj.weight": "model-00002-of-00004.safetensors",
|
| 114 |
+
"language_model.model.layers.16.self_attn.v_proj.bias": "model-00002-of-00004.safetensors",
|
| 115 |
+
"language_model.model.layers.16.self_attn.v_proj.weight": "model-00002-of-00004.safetensors",
|
| 116 |
+
"language_model.model.layers.17.input_layernorm.weight": "model-00003-of-00004.safetensors",
|
| 117 |
+
"language_model.model.layers.17.mlp.down_proj.weight": "model-00003-of-00004.safetensors",
|
| 118 |
+
"language_model.model.layers.17.mlp.gate_proj.weight": "model-00002-of-00004.safetensors",
|
| 119 |
+
"language_model.model.layers.17.mlp.up_proj.weight": "model-00002-of-00004.safetensors",
|
| 120 |
+
"language_model.model.layers.17.post_attention_layernorm.weight": "model-00003-of-00004.safetensors",
|
| 121 |
+
"language_model.model.layers.17.self_attn.k_proj.bias": "model-00002-of-00004.safetensors",
|
| 122 |
+
"language_model.model.layers.17.self_attn.k_proj.weight": "model-00002-of-00004.safetensors",
|
| 123 |
+
"language_model.model.layers.17.self_attn.o_proj.weight": "model-00002-of-00004.safetensors",
|
| 124 |
+
"language_model.model.layers.17.self_attn.q_proj.bias": "model-00002-of-00004.safetensors",
|
| 125 |
+
"language_model.model.layers.17.self_attn.q_proj.weight": "model-00002-of-00004.safetensors",
|
| 126 |
+
"language_model.model.layers.17.self_attn.v_proj.bias": "model-00002-of-00004.safetensors",
|
| 127 |
+
"language_model.model.layers.17.self_attn.v_proj.weight": "model-00002-of-00004.safetensors",
|
| 128 |
+
"language_model.model.layers.18.input_layernorm.weight": "model-00003-of-00004.safetensors",
|
| 129 |
+
"language_model.model.layers.18.mlp.down_proj.weight": "model-00003-of-00004.safetensors",
|
| 130 |
+
"language_model.model.layers.18.mlp.gate_proj.weight": "model-00003-of-00004.safetensors",
|
| 131 |
+
"language_model.model.layers.18.mlp.up_proj.weight": "model-00003-of-00004.safetensors",
|
| 132 |
+
"language_model.model.layers.18.post_attention_layernorm.weight": "model-00003-of-00004.safetensors",
|
| 133 |
+
"language_model.model.layers.18.self_attn.k_proj.bias": "model-00003-of-00004.safetensors",
|
| 134 |
+
"language_model.model.layers.18.self_attn.k_proj.weight": "model-00003-of-00004.safetensors",
|
| 135 |
+
"language_model.model.layers.18.self_attn.o_proj.weight": "model-00003-of-00004.safetensors",
|
| 136 |
+
"language_model.model.layers.18.self_attn.q_proj.bias": "model-00003-of-00004.safetensors",
|
| 137 |
+
"language_model.model.layers.18.self_attn.q_proj.weight": "model-00003-of-00004.safetensors",
|
| 138 |
+
"language_model.model.layers.18.self_attn.v_proj.bias": "model-00003-of-00004.safetensors",
|
| 139 |
+
"language_model.model.layers.18.self_attn.v_proj.weight": "model-00003-of-00004.safetensors",
|
| 140 |
+
"language_model.model.layers.19.input_layernorm.weight": "model-00003-of-00004.safetensors",
|
| 141 |
+
"language_model.model.layers.19.mlp.down_proj.weight": "model-00003-of-00004.safetensors",
|
| 142 |
+
"language_model.model.layers.19.mlp.gate_proj.weight": "model-00003-of-00004.safetensors",
|
| 143 |
+
"language_model.model.layers.19.mlp.up_proj.weight": "model-00003-of-00004.safetensors",
|
| 144 |
+
"language_model.model.layers.19.post_attention_layernorm.weight": "model-00003-of-00004.safetensors",
|
| 145 |
+
"language_model.model.layers.19.self_attn.k_proj.bias": "model-00003-of-00004.safetensors",
|
| 146 |
+
"language_model.model.layers.19.self_attn.k_proj.weight": "model-00003-of-00004.safetensors",
|
| 147 |
+
"language_model.model.layers.19.self_attn.o_proj.weight": "model-00003-of-00004.safetensors",
|
| 148 |
+
"language_model.model.layers.19.self_attn.q_proj.bias": "model-00003-of-00004.safetensors",
|
| 149 |
+
"language_model.model.layers.19.self_attn.q_proj.weight": "model-00003-of-00004.safetensors",
|
| 150 |
+
"language_model.model.layers.19.self_attn.v_proj.bias": "model-00003-of-00004.safetensors",
|
| 151 |
+
"language_model.model.layers.19.self_attn.v_proj.weight": "model-00003-of-00004.safetensors",
|
| 152 |
+
"language_model.model.layers.2.input_layernorm.weight": "model-00001-of-00004.safetensors",
|
| 153 |
+
"language_model.model.layers.2.mlp.down_proj.weight": "model-00001-of-00004.safetensors",
|
| 154 |
+
"language_model.model.layers.2.mlp.gate_proj.weight": "model-00001-of-00004.safetensors",
|
| 155 |
+
"language_model.model.layers.2.mlp.up_proj.weight": "model-00001-of-00004.safetensors",
|
| 156 |
+
"language_model.model.layers.2.post_attention_layernorm.weight": "model-00001-of-00004.safetensors",
|
| 157 |
+
"language_model.model.layers.2.self_attn.k_proj.bias": "model-00001-of-00004.safetensors",
|
| 158 |
+
"language_model.model.layers.2.self_attn.k_proj.weight": "model-00001-of-00004.safetensors",
|
| 159 |
+
"language_model.model.layers.2.self_attn.o_proj.weight": "model-00001-of-00004.safetensors",
|
| 160 |
+
"language_model.model.layers.2.self_attn.q_proj.bias": "model-00001-of-00004.safetensors",
|
| 161 |
+
"language_model.model.layers.2.self_attn.q_proj.weight": "model-00001-of-00004.safetensors",
|
| 162 |
+
"language_model.model.layers.2.self_attn.v_proj.bias": "model-00001-of-00004.safetensors",
|
| 163 |
+
"language_model.model.layers.2.self_attn.v_proj.weight": "model-00001-of-00004.safetensors",
|
| 164 |
+
"language_model.model.layers.20.input_layernorm.weight": "model-00003-of-00004.safetensors",
|
| 165 |
+
"language_model.model.layers.20.mlp.down_proj.weight": "model-00003-of-00004.safetensors",
|
| 166 |
+
"language_model.model.layers.20.mlp.gate_proj.weight": "model-00003-of-00004.safetensors",
|
| 167 |
+
"language_model.model.layers.20.mlp.up_proj.weight": "model-00003-of-00004.safetensors",
|
| 168 |
+
"language_model.model.layers.20.post_attention_layernorm.weight": "model-00003-of-00004.safetensors",
|
| 169 |
+
"language_model.model.layers.20.self_attn.k_proj.bias": "model-00003-of-00004.safetensors",
|
| 170 |
+
"language_model.model.layers.20.self_attn.k_proj.weight": "model-00003-of-00004.safetensors",
|
| 171 |
+
"language_model.model.layers.20.self_attn.o_proj.weight": "model-00003-of-00004.safetensors",
|
| 172 |
+
"language_model.model.layers.20.self_attn.q_proj.bias": "model-00003-of-00004.safetensors",
|
| 173 |
+
"language_model.model.layers.20.self_attn.q_proj.weight": "model-00003-of-00004.safetensors",
|
| 174 |
+
"language_model.model.layers.20.self_attn.v_proj.bias": "model-00003-of-00004.safetensors",
|
| 175 |
+
"language_model.model.layers.20.self_attn.v_proj.weight": "model-00003-of-00004.safetensors",
|
| 176 |
+
"language_model.model.layers.21.input_layernorm.weight": "model-00003-of-00004.safetensors",
|
| 177 |
+
"language_model.model.layers.21.mlp.down_proj.weight": "model-00003-of-00004.safetensors",
|
| 178 |
+
"language_model.model.layers.21.mlp.gate_proj.weight": "model-00003-of-00004.safetensors",
|
| 179 |
+
"language_model.model.layers.21.mlp.up_proj.weight": "model-00003-of-00004.safetensors",
|
| 180 |
+
"language_model.model.layers.21.post_attention_layernorm.weight": "model-00003-of-00004.safetensors",
|
| 181 |
+
"language_model.model.layers.21.self_attn.k_proj.bias": "model-00003-of-00004.safetensors",
|
| 182 |
+
"language_model.model.layers.21.self_attn.k_proj.weight": "model-00003-of-00004.safetensors",
|
| 183 |
+
"language_model.model.layers.21.self_attn.o_proj.weight": "model-00003-of-00004.safetensors",
|
| 184 |
+
"language_model.model.layers.21.self_attn.q_proj.bias": "model-00003-of-00004.safetensors",
|
| 185 |
+
"language_model.model.layers.21.self_attn.q_proj.weight": "model-00003-of-00004.safetensors",
|
| 186 |
+
"language_model.model.layers.21.self_attn.v_proj.bias": "model-00003-of-00004.safetensors",
|
| 187 |
+
"language_model.model.layers.21.self_attn.v_proj.weight": "model-00003-of-00004.safetensors",
|
| 188 |
+
"language_model.model.layers.22.input_layernorm.weight": "model-00003-of-00004.safetensors",
|
| 189 |
+
"language_model.model.layers.22.mlp.down_proj.weight": "model-00003-of-00004.safetensors",
|
| 190 |
+
"language_model.model.layers.22.mlp.gate_proj.weight": "model-00003-of-00004.safetensors",
|
| 191 |
+
"language_model.model.layers.22.mlp.up_proj.weight": "model-00003-of-00004.safetensors",
|
| 192 |
+
"language_model.model.layers.22.post_attention_layernorm.weight": "model-00003-of-00004.safetensors",
|
| 193 |
+
"language_model.model.layers.22.self_attn.k_proj.bias": "model-00003-of-00004.safetensors",
|
| 194 |
+
"language_model.model.layers.22.self_attn.k_proj.weight": "model-00003-of-00004.safetensors",
|
| 195 |
+
"language_model.model.layers.22.self_attn.o_proj.weight": "model-00003-of-00004.safetensors",
|
| 196 |
+
"language_model.model.layers.22.self_attn.q_proj.bias": "model-00003-of-00004.safetensors",
|
| 197 |
+
"language_model.model.layers.22.self_attn.q_proj.weight": "model-00003-of-00004.safetensors",
|
| 198 |
+
"language_model.model.layers.22.self_attn.v_proj.bias": "model-00003-of-00004.safetensors",
|
| 199 |
+
"language_model.model.layers.22.self_attn.v_proj.weight": "model-00003-of-00004.safetensors",
|
| 200 |
+
"language_model.model.layers.23.input_layernorm.weight": "model-00003-of-00004.safetensors",
|
| 201 |
+
"language_model.model.layers.23.mlp.down_proj.weight": "model-00003-of-00004.safetensors",
|
| 202 |
+
"language_model.model.layers.23.mlp.gate_proj.weight": "model-00003-of-00004.safetensors",
|
| 203 |
+
"language_model.model.layers.23.mlp.up_proj.weight": "model-00003-of-00004.safetensors",
|
| 204 |
+
"language_model.model.layers.23.post_attention_layernorm.weight": "model-00003-of-00004.safetensors",
|
| 205 |
+
"language_model.model.layers.23.self_attn.k_proj.bias": "model-00003-of-00004.safetensors",
|
| 206 |
+
"language_model.model.layers.23.self_attn.k_proj.weight": "model-00003-of-00004.safetensors",
|
| 207 |
+
"language_model.model.layers.23.self_attn.o_proj.weight": "model-00003-of-00004.safetensors",
|
| 208 |
+
"language_model.model.layers.23.self_attn.q_proj.bias": "model-00003-of-00004.safetensors",
|
| 209 |
+
"language_model.model.layers.23.self_attn.q_proj.weight": "model-00003-of-00004.safetensors",
|
| 210 |
+
"language_model.model.layers.23.self_attn.v_proj.bias": "model-00003-of-00004.safetensors",
|
| 211 |
+
"language_model.model.layers.23.self_attn.v_proj.weight": "model-00003-of-00004.safetensors",
|
| 212 |
+
"language_model.model.layers.24.input_layernorm.weight": "model-00003-of-00004.safetensors",
|
| 213 |
+
"language_model.model.layers.24.mlp.down_proj.weight": "model-00003-of-00004.safetensors",
|
| 214 |
+
"language_model.model.layers.24.mlp.gate_proj.weight": "model-00003-of-00004.safetensors",
|
| 215 |
+
"language_model.model.layers.24.mlp.up_proj.weight": "model-00003-of-00004.safetensors",
|
| 216 |
+
"language_model.model.layers.24.post_attention_layernorm.weight": "model-00003-of-00004.safetensors",
|
| 217 |
+
"language_model.model.layers.24.self_attn.k_proj.bias": "model-00003-of-00004.safetensors",
|
| 218 |
+
"language_model.model.layers.24.self_attn.k_proj.weight": "model-00003-of-00004.safetensors",
|
| 219 |
+
"language_model.model.layers.24.self_attn.o_proj.weight": "model-00003-of-00004.safetensors",
|
| 220 |
+
"language_model.model.layers.24.self_attn.q_proj.bias": "model-00003-of-00004.safetensors",
|
| 221 |
+
"language_model.model.layers.24.self_attn.q_proj.weight": "model-00003-of-00004.safetensors",
|
| 222 |
+
"language_model.model.layers.24.self_attn.v_proj.bias": "model-00003-of-00004.safetensors",
|
| 223 |
+
"language_model.model.layers.24.self_attn.v_proj.weight": "model-00003-of-00004.safetensors",
|
| 224 |
+
"language_model.model.layers.25.input_layernorm.weight": "model-00003-of-00004.safetensors",
|
| 225 |
+
"language_model.model.layers.25.mlp.down_proj.weight": "model-00003-of-00004.safetensors",
|
| 226 |
+
"language_model.model.layers.25.mlp.gate_proj.weight": "model-00003-of-00004.safetensors",
|
| 227 |
+
"language_model.model.layers.25.mlp.up_proj.weight": "model-00003-of-00004.safetensors",
|
| 228 |
+
"language_model.model.layers.25.post_attention_layernorm.weight": "model-00003-of-00004.safetensors",
|
| 229 |
+
"language_model.model.layers.25.self_attn.k_proj.bias": "model-00003-of-00004.safetensors",
|
| 230 |
+
"language_model.model.layers.25.self_attn.k_proj.weight": "model-00003-of-00004.safetensors",
|
| 231 |
+
"language_model.model.layers.25.self_attn.o_proj.weight": "model-00003-of-00004.safetensors",
|
| 232 |
+
"language_model.model.layers.25.self_attn.q_proj.bias": "model-00003-of-00004.safetensors",
|
| 233 |
+
"language_model.model.layers.25.self_attn.q_proj.weight": "model-00003-of-00004.safetensors",
|
| 234 |
+
"language_model.model.layers.25.self_attn.v_proj.bias": "model-00003-of-00004.safetensors",
|
| 235 |
+
"language_model.model.layers.25.self_attn.v_proj.weight": "model-00003-of-00004.safetensors",
|
| 236 |
+
"language_model.model.layers.26.input_layernorm.weight": "model-00003-of-00004.safetensors",
|
| 237 |
+
"language_model.model.layers.26.mlp.down_proj.weight": "model-00003-of-00004.safetensors",
|
| 238 |
+
"language_model.model.layers.26.mlp.gate_proj.weight": "model-00003-of-00004.safetensors",
|
| 239 |
+
"language_model.model.layers.26.mlp.up_proj.weight": "model-00003-of-00004.safetensors",
|
| 240 |
+
"language_model.model.layers.26.post_attention_layernorm.weight": "model-00003-of-00004.safetensors",
|
| 241 |
+
"language_model.model.layers.26.self_attn.k_proj.bias": "model-00003-of-00004.safetensors",
|
| 242 |
+
"language_model.model.layers.26.self_attn.k_proj.weight": "model-00003-of-00004.safetensors",
|
| 243 |
+
"language_model.model.layers.26.self_attn.o_proj.weight": "model-00003-of-00004.safetensors",
|
| 244 |
+
"language_model.model.layers.26.self_attn.q_proj.bias": "model-00003-of-00004.safetensors",
|
| 245 |
+
"language_model.model.layers.26.self_attn.q_proj.weight": "model-00003-of-00004.safetensors",
|
| 246 |
+
"language_model.model.layers.26.self_attn.v_proj.bias": "model-00003-of-00004.safetensors",
|
| 247 |
+
"language_model.model.layers.26.self_attn.v_proj.weight": "model-00003-of-00004.safetensors",
|
| 248 |
+
"language_model.model.layers.27.input_layernorm.weight": "model-00003-of-00004.safetensors",
|
| 249 |
+
"language_model.model.layers.27.mlp.down_proj.weight": "model-00003-of-00004.safetensors",
|
| 250 |
+
"language_model.model.layers.27.mlp.gate_proj.weight": "model-00003-of-00004.safetensors",
|
| 251 |
+
"language_model.model.layers.27.mlp.up_proj.weight": "model-00003-of-00004.safetensors",
|
| 252 |
+
"language_model.model.layers.27.post_attention_layernorm.weight": "model-00003-of-00004.safetensors",
|
| 253 |
+
"language_model.model.layers.27.self_attn.k_proj.bias": "model-00003-of-00004.safetensors",
|
| 254 |
+
"language_model.model.layers.27.self_attn.k_proj.weight": "model-00003-of-00004.safetensors",
|
| 255 |
+
"language_model.model.layers.27.self_attn.o_proj.weight": "model-00003-of-00004.safetensors",
|
| 256 |
+
"language_model.model.layers.27.self_attn.q_proj.bias": "model-00003-of-00004.safetensors",
|
| 257 |
+
"language_model.model.layers.27.self_attn.q_proj.weight": "model-00003-of-00004.safetensors",
|
| 258 |
+
"language_model.model.layers.27.self_attn.v_proj.bias": "model-00003-of-00004.safetensors",
|
| 259 |
+
"language_model.model.layers.27.self_attn.v_proj.weight": "model-00003-of-00004.safetensors",
|
| 260 |
+
"language_model.model.layers.3.input_layernorm.weight": "model-00001-of-00004.safetensors",
|
| 261 |
+
"language_model.model.layers.3.mlp.down_proj.weight": "model-00001-of-00004.safetensors",
|
| 262 |
+
"language_model.model.layers.3.mlp.gate_proj.weight": "model-00001-of-00004.safetensors",
|
| 263 |
+
"language_model.model.layers.3.mlp.up_proj.weight": "model-00001-of-00004.safetensors",
|
| 264 |
+
"language_model.model.layers.3.post_attention_layernorm.weight": "model-00001-of-00004.safetensors",
|
| 265 |
+
"language_model.model.layers.3.self_attn.k_proj.bias": "model-00001-of-00004.safetensors",
|
| 266 |
+
"language_model.model.layers.3.self_attn.k_proj.weight": "model-00001-of-00004.safetensors",
|
| 267 |
+
"language_model.model.layers.3.self_attn.o_proj.weight": "model-00001-of-00004.safetensors",
|
| 268 |
+
"language_model.model.layers.3.self_attn.q_proj.bias": "model-00001-of-00004.safetensors",
|
| 269 |
+
"language_model.model.layers.3.self_attn.q_proj.weight": "model-00001-of-00004.safetensors",
|
| 270 |
+
"language_model.model.layers.3.self_attn.v_proj.bias": "model-00001-of-00004.safetensors",
|
| 271 |
+
"language_model.model.layers.3.self_attn.v_proj.weight": "model-00001-of-00004.safetensors",
|
| 272 |
+
"language_model.model.layers.4.input_layernorm.weight": "model-00001-of-00004.safetensors",
|
| 273 |
+
"language_model.model.layers.4.mlp.down_proj.weight": "model-00001-of-00004.safetensors",
|
| 274 |
+
"language_model.model.layers.4.mlp.gate_proj.weight": "model-00001-of-00004.safetensors",
|
| 275 |
+
"language_model.model.layers.4.mlp.up_proj.weight": "model-00001-of-00004.safetensors",
|
| 276 |
+
"language_model.model.layers.4.post_attention_layernorm.weight": "model-00001-of-00004.safetensors",
|
| 277 |
+
"language_model.model.layers.4.self_attn.k_proj.bias": "model-00001-of-00004.safetensors",
|
| 278 |
+
"language_model.model.layers.4.self_attn.k_proj.weight": "model-00001-of-00004.safetensors",
|
| 279 |
+
"language_model.model.layers.4.self_attn.o_proj.weight": "model-00001-of-00004.safetensors",
|
| 280 |
+
"language_model.model.layers.4.self_attn.q_proj.bias": "model-00001-of-00004.safetensors",
|
| 281 |
+
"language_model.model.layers.4.self_attn.q_proj.weight": "model-00001-of-00004.safetensors",
|
| 282 |
+
"language_model.model.layers.4.self_attn.v_proj.bias": "model-00001-of-00004.safetensors",
|
| 283 |
+
"language_model.model.layers.4.self_attn.v_proj.weight": "model-00001-of-00004.safetensors",
|
| 284 |
+
"language_model.model.layers.5.input_layernorm.weight": "model-00001-of-00004.safetensors",
|
| 285 |
+
"language_model.model.layers.5.mlp.down_proj.weight": "model-00001-of-00004.safetensors",
|
| 286 |
+
"language_model.model.layers.5.mlp.gate_proj.weight": "model-00001-of-00004.safetensors",
|
| 287 |
+
"language_model.model.layers.5.mlp.up_proj.weight": "model-00001-of-00004.safetensors",
|
| 288 |
+
"language_model.model.layers.5.post_attention_layernorm.weight": "model-00001-of-00004.safetensors",
|
| 289 |
+
"language_model.model.layers.5.self_attn.k_proj.bias": "model-00001-of-00004.safetensors",
|
| 290 |
+
"language_model.model.layers.5.self_attn.k_proj.weight": "model-00001-of-00004.safetensors",
|
| 291 |
+
"language_model.model.layers.5.self_attn.o_proj.weight": "model-00001-of-00004.safetensors",
|
| 292 |
+
"language_model.model.layers.5.self_attn.q_proj.bias": "model-00001-of-00004.safetensors",
|
| 293 |
+
"language_model.model.layers.5.self_attn.q_proj.weight": "model-00001-of-00004.safetensors",
|
| 294 |
+
"language_model.model.layers.5.self_attn.v_proj.bias": "model-00001-of-00004.safetensors",
|
| 295 |
+
"language_model.model.layers.5.self_attn.v_proj.weight": "model-00001-of-00004.safetensors",
|
| 296 |
+
"language_model.model.layers.6.input_layernorm.weight": "model-00001-of-00004.safetensors",
|
| 297 |
+
"language_model.model.layers.6.mlp.down_proj.weight": "model-00001-of-00004.safetensors",
|
| 298 |
+
"language_model.model.layers.6.mlp.gate_proj.weight": "model-00001-of-00004.safetensors",
|
| 299 |
+
"language_model.model.layers.6.mlp.up_proj.weight": "model-00001-of-00004.safetensors",
|
| 300 |
+
"language_model.model.layers.6.post_attention_layernorm.weight": "model-00001-of-00004.safetensors",
|
| 301 |
+
"language_model.model.layers.6.self_attn.k_proj.bias": "model-00001-of-00004.safetensors",
|
| 302 |
+
"language_model.model.layers.6.self_attn.k_proj.weight": "model-00001-of-00004.safetensors",
|
| 303 |
+
"language_model.model.layers.6.self_attn.o_proj.weight": "model-00001-of-00004.safetensors",
|
| 304 |
+
"language_model.model.layers.6.self_attn.q_proj.bias": "model-00001-of-00004.safetensors",
|
| 305 |
+
"language_model.model.layers.6.self_attn.q_proj.weight": "model-00001-of-00004.safetensors",
|
| 306 |
+
"language_model.model.layers.6.self_attn.v_proj.bias": "model-00001-of-00004.safetensors",
|
| 307 |
+
"language_model.model.layers.6.self_attn.v_proj.weight": "model-00001-of-00004.safetensors",
|
| 308 |
+
"language_model.model.layers.7.input_layernorm.weight": "model-00002-of-00004.safetensors",
|
| 309 |
+
"language_model.model.layers.7.mlp.down_proj.weight": "model-00002-of-00004.safetensors",
|
| 310 |
+
"language_model.model.layers.7.mlp.gate_proj.weight": "model-00002-of-00004.safetensors",
|
| 311 |
+
"language_model.model.layers.7.mlp.up_proj.weight": "model-00002-of-00004.safetensors",
|
| 312 |
+
"language_model.model.layers.7.post_attention_layernorm.weight": "model-00002-of-00004.safetensors",
|
| 313 |
+
"language_model.model.layers.7.self_attn.k_proj.bias": "model-00001-of-00004.safetensors",
|
| 314 |
+
"language_model.model.layers.7.self_attn.k_proj.weight": "model-00001-of-00004.safetensors",
|
| 315 |
+
"language_model.model.layers.7.self_attn.o_proj.weight": "model-00002-of-00004.safetensors",
|
| 316 |
+
"language_model.model.layers.7.self_attn.q_proj.bias": "model-00001-of-00004.safetensors",
|
| 317 |
+
"language_model.model.layers.7.self_attn.q_proj.weight": "model-00001-of-00004.safetensors",
|
| 318 |
+
"language_model.model.layers.7.self_attn.v_proj.bias": "model-00001-of-00004.safetensors",
|
| 319 |
+
"language_model.model.layers.7.self_attn.v_proj.weight": "model-00001-of-00004.safetensors",
|
| 320 |
+
"language_model.model.layers.8.input_layernorm.weight": "model-00002-of-00004.safetensors",
|
| 321 |
+
"language_model.model.layers.8.mlp.down_proj.weight": "model-00002-of-00004.safetensors",
|
| 322 |
+
"language_model.model.layers.8.mlp.gate_proj.weight": "model-00002-of-00004.safetensors",
|
| 323 |
+
"language_model.model.layers.8.mlp.up_proj.weight": "model-00002-of-00004.safetensors",
|
| 324 |
+
"language_model.model.layers.8.post_attention_layernorm.weight": "model-00002-of-00004.safetensors",
|
| 325 |
+
"language_model.model.layers.8.self_attn.k_proj.bias": "model-00002-of-00004.safetensors",
|
| 326 |
+
"language_model.model.layers.8.self_attn.k_proj.weight": "model-00002-of-00004.safetensors",
|
| 327 |
+
"language_model.model.layers.8.self_attn.o_proj.weight": "model-00002-of-00004.safetensors",
|
| 328 |
+
"language_model.model.layers.8.self_attn.q_proj.bias": "model-00002-of-00004.safetensors",
|
| 329 |
+
"language_model.model.layers.8.self_attn.q_proj.weight": "model-00002-of-00004.safetensors",
|
| 330 |
+
"language_model.model.layers.8.self_attn.v_proj.bias": "model-00002-of-00004.safetensors",
|
| 331 |
+
"language_model.model.layers.8.self_attn.v_proj.weight": "model-00002-of-00004.safetensors",
|
| 332 |
+
"language_model.model.layers.9.input_layernorm.weight": "model-00002-of-00004.safetensors",
|
| 333 |
+
"language_model.model.layers.9.mlp.down_proj.weight": "model-00002-of-00004.safetensors",
|
| 334 |
+
"language_model.model.layers.9.mlp.gate_proj.weight": "model-00002-of-00004.safetensors",
|
| 335 |
+
"language_model.model.layers.9.mlp.up_proj.weight": "model-00002-of-00004.safetensors",
|
| 336 |
+
"language_model.model.layers.9.post_attention_layernorm.weight": "model-00002-of-00004.safetensors",
|
| 337 |
+
"language_model.model.layers.9.self_attn.k_proj.bias": "model-00002-of-00004.safetensors",
|
| 338 |
+
"language_model.model.layers.9.self_attn.k_proj.weight": "model-00002-of-00004.safetensors",
|
| 339 |
+
"language_model.model.layers.9.self_attn.o_proj.weight": "model-00002-of-00004.safetensors",
|
| 340 |
+
"language_model.model.layers.9.self_attn.q_proj.bias": "model-00002-of-00004.safetensors",
|
| 341 |
+
"language_model.model.layers.9.self_attn.q_proj.weight": "model-00002-of-00004.safetensors",
|
| 342 |
+
"language_model.model.layers.9.self_attn.v_proj.bias": "model-00002-of-00004.safetensors",
|
| 343 |
+
"language_model.model.layers.9.self_attn.v_proj.weight": "model-00002-of-00004.safetensors",
|
| 344 |
+
"language_model.model.norm.weight": "model-00003-of-00004.safetensors",
|
| 345 |
+
"mlp1.0.bias": "model-00004-of-00004.safetensors",
|
| 346 |
+
"mlp1.0.weight": "model-00004-of-00004.safetensors",
|
| 347 |
+
"mlp1.1.bias": "model-00004-of-00004.safetensors",
|
| 348 |
+
"mlp1.1.weight": "model-00004-of-00004.safetensors",
|
| 349 |
+
"mlp1.3.bias": "model-00004-of-00004.safetensors",
|
| 350 |
+
"mlp1.3.weight": "model-00004-of-00004.safetensors",
|
| 351 |
+
"vision_model.embeddings.class_embedding": "model-00001-of-00004.safetensors",
|
| 352 |
+
"vision_model.embeddings.patch_embedding.bias": "model-00001-of-00004.safetensors",
|
| 353 |
+
"vision_model.embeddings.patch_embedding.weight": "model-00001-of-00004.safetensors",
|
| 354 |
+
"vision_model.embeddings.position_embedding": "model-00001-of-00004.safetensors",
|
| 355 |
+
"vision_model.encoder.layers.0.attn.proj.bias": "model-00001-of-00004.safetensors",
|
| 356 |
+
"vision_model.encoder.layers.0.attn.proj.weight": "model-00001-of-00004.safetensors",
|
| 357 |
+
"vision_model.encoder.layers.0.attn.qkv.bias": "model-00001-of-00004.safetensors",
|
| 358 |
+
"vision_model.encoder.layers.0.attn.qkv.weight": "model-00001-of-00004.safetensors",
|
| 359 |
+
"vision_model.encoder.layers.0.ls1": "model-00001-of-00004.safetensors",
|
| 360 |
+
"vision_model.encoder.layers.0.ls2": "model-00001-of-00004.safetensors",
|
| 361 |
+
"vision_model.encoder.layers.0.mlp.fc1.bias": "model-00001-of-00004.safetensors",
|
| 362 |
+
"vision_model.encoder.layers.0.mlp.fc1.weight": "model-00001-of-00004.safetensors",
|
| 363 |
+
"vision_model.encoder.layers.0.mlp.fc2.bias": "model-00001-of-00004.safetensors",
|
| 364 |
+
"vision_model.encoder.layers.0.mlp.fc2.weight": "model-00001-of-00004.safetensors",
|
| 365 |
+
"vision_model.encoder.layers.0.norm1.bias": "model-00001-of-00004.safetensors",
|
| 366 |
+
"vision_model.encoder.layers.0.norm1.weight": "model-00001-of-00004.safetensors",
|
| 367 |
+
"vision_model.encoder.layers.0.norm2.bias": "model-00001-of-00004.safetensors",
|
| 368 |
+
"vision_model.encoder.layers.0.norm2.weight": "model-00001-of-00004.safetensors",
|
| 369 |
+
"vision_model.encoder.layers.1.attn.proj.bias": "model-00001-of-00004.safetensors",
|
| 370 |
+
"vision_model.encoder.layers.1.attn.proj.weight": "model-00001-of-00004.safetensors",
|
| 371 |
+
"vision_model.encoder.layers.1.attn.qkv.bias": "model-00001-of-00004.safetensors",
|
| 372 |
+
"vision_model.encoder.layers.1.attn.qkv.weight": "model-00001-of-00004.safetensors",
|
| 373 |
+
"vision_model.encoder.layers.1.ls1": "model-00001-of-00004.safetensors",
|
| 374 |
+
"vision_model.encoder.layers.1.ls2": "model-00001-of-00004.safetensors",
|
| 375 |
+
"vision_model.encoder.layers.1.mlp.fc1.bias": "model-00001-of-00004.safetensors",
|
| 376 |
+
"vision_model.encoder.layers.1.mlp.fc1.weight": "model-00001-of-00004.safetensors",
|
| 377 |
+
"vision_model.encoder.layers.1.mlp.fc2.bias": "model-00001-of-00004.safetensors",
|
| 378 |
+
"vision_model.encoder.layers.1.mlp.fc2.weight": "model-00001-of-00004.safetensors",
|
| 379 |
+
"vision_model.encoder.layers.1.norm1.bias": "model-00001-of-00004.safetensors",
|
| 380 |
+
"vision_model.encoder.layers.1.norm1.weight": "model-00001-of-00004.safetensors",
|
| 381 |
+
"vision_model.encoder.layers.1.norm2.bias": "model-00001-of-00004.safetensors",
|
| 382 |
+
"vision_model.encoder.layers.1.norm2.weight": "model-00001-of-00004.safetensors",
|
| 383 |
+
"vision_model.encoder.layers.10.attn.proj.bias": "model-00001-of-00004.safetensors",
|
| 384 |
+
"vision_model.encoder.layers.10.attn.proj.weight": "model-00001-of-00004.safetensors",
|
| 385 |
+
"vision_model.encoder.layers.10.attn.qkv.bias": "model-00001-of-00004.safetensors",
|
| 386 |
+
"vision_model.encoder.layers.10.attn.qkv.weight": "model-00001-of-00004.safetensors",
|
| 387 |
+
"vision_model.encoder.layers.10.ls1": "model-00001-of-00004.safetensors",
|
| 388 |
+
"vision_model.encoder.layers.10.ls2": "model-00001-of-00004.safetensors",
|
| 389 |
+
"vision_model.encoder.layers.10.mlp.fc1.bias": "model-00001-of-00004.safetensors",
|
| 390 |
+
"vision_model.encoder.layers.10.mlp.fc1.weight": "model-00001-of-00004.safetensors",
|
| 391 |
+
"vision_model.encoder.layers.10.mlp.fc2.bias": "model-00001-of-00004.safetensors",
|
| 392 |
+
"vision_model.encoder.layers.10.mlp.fc2.weight": "model-00001-of-00004.safetensors",
|
| 393 |
+
"vision_model.encoder.layers.10.norm1.bias": "model-00001-of-00004.safetensors",
|
| 394 |
+
"vision_model.encoder.layers.10.norm1.weight": "model-00001-of-00004.safetensors",
|
| 395 |
+
"vision_model.encoder.layers.10.norm2.bias": "model-00001-of-00004.safetensors",
|
| 396 |
+
"vision_model.encoder.layers.10.norm2.weight": "model-00001-of-00004.safetensors",
|
| 397 |
+
"vision_model.encoder.layers.11.attn.proj.bias": "model-00001-of-00004.safetensors",
|
| 398 |
+
"vision_model.encoder.layers.11.attn.proj.weight": "model-00001-of-00004.safetensors",
|
| 399 |
+
"vision_model.encoder.layers.11.attn.qkv.bias": "model-00001-of-00004.safetensors",
|
| 400 |
+
"vision_model.encoder.layers.11.attn.qkv.weight": "model-00001-of-00004.safetensors",
|
| 401 |
+
"vision_model.encoder.layers.11.ls1": "model-00001-of-00004.safetensors",
|
| 402 |
+
"vision_model.encoder.layers.11.ls2": "model-00001-of-00004.safetensors",
|
| 403 |
+
"vision_model.encoder.layers.11.mlp.fc1.bias": "model-00001-of-00004.safetensors",
|
| 404 |
+
"vision_model.encoder.layers.11.mlp.fc1.weight": "model-00001-of-00004.safetensors",
|
| 405 |
+
"vision_model.encoder.layers.11.mlp.fc2.bias": "model-00001-of-00004.safetensors",
|
| 406 |
+
"vision_model.encoder.layers.11.mlp.fc2.weight": "model-00001-of-00004.safetensors",
|
| 407 |
+
"vision_model.encoder.layers.11.norm1.bias": "model-00001-of-00004.safetensors",
|
| 408 |
+
"vision_model.encoder.layers.11.norm1.weight": "model-00001-of-00004.safetensors",
|
| 409 |
+
"vision_model.encoder.layers.11.norm2.bias": "model-00001-of-00004.safetensors",
|
| 410 |
+
"vision_model.encoder.layers.11.norm2.weight": "model-00001-of-00004.safetensors",
|
| 411 |
+
"vision_model.encoder.layers.12.attn.proj.bias": "model-00001-of-00004.safetensors",
|
| 412 |
+
"vision_model.encoder.layers.12.attn.proj.weight": "model-00001-of-00004.safetensors",
|
| 413 |
+
"vision_model.encoder.layers.12.attn.qkv.bias": "model-00001-of-00004.safetensors",
|
| 414 |
+
"vision_model.encoder.layers.12.attn.qkv.weight": "model-00001-of-00004.safetensors",
|
| 415 |
+
"vision_model.encoder.layers.12.ls1": "model-00001-of-00004.safetensors",
|
| 416 |
+
"vision_model.encoder.layers.12.ls2": "model-00001-of-00004.safetensors",
|
| 417 |
+
"vision_model.encoder.layers.12.mlp.fc1.bias": "model-00001-of-00004.safetensors",
|
| 418 |
+
"vision_model.encoder.layers.12.mlp.fc1.weight": "model-00001-of-00004.safetensors",
|
| 419 |
+
"vision_model.encoder.layers.12.mlp.fc2.bias": "model-00001-of-00004.safetensors",
|
| 420 |
+
"vision_model.encoder.layers.12.mlp.fc2.weight": "model-00001-of-00004.safetensors",
|
| 421 |
+
"vision_model.encoder.layers.12.norm1.bias": "model-00001-of-00004.safetensors",
|
| 422 |
+
"vision_model.encoder.layers.12.norm1.weight": "model-00001-of-00004.safetensors",
|
| 423 |
+
"vision_model.encoder.layers.12.norm2.bias": "model-00001-of-00004.safetensors",
|
| 424 |
+
"vision_model.encoder.layers.12.norm2.weight": "model-00001-of-00004.safetensors",
|
| 425 |
+
"vision_model.encoder.layers.13.attn.proj.bias": "model-00001-of-00004.safetensors",
|
| 426 |
+
"vision_model.encoder.layers.13.attn.proj.weight": "model-00001-of-00004.safetensors",
|
| 427 |
+
"vision_model.encoder.layers.13.attn.qkv.bias": "model-00001-of-00004.safetensors",
|
| 428 |
+
"vision_model.encoder.layers.13.attn.qkv.weight": "model-00001-of-00004.safetensors",
|
| 429 |
+
"vision_model.encoder.layers.13.ls1": "model-00001-of-00004.safetensors",
|
| 430 |
+
"vision_model.encoder.layers.13.ls2": "model-00001-of-00004.safetensors",
|
| 431 |
+
"vision_model.encoder.layers.13.mlp.fc1.bias": "model-00001-of-00004.safetensors",
|
| 432 |
+
"vision_model.encoder.layers.13.mlp.fc1.weight": "model-00001-of-00004.safetensors",
|
| 433 |
+
"vision_model.encoder.layers.13.mlp.fc2.bias": "model-00001-of-00004.safetensors",
|
| 434 |
+
"vision_model.encoder.layers.13.mlp.fc2.weight": "model-00001-of-00004.safetensors",
|
| 435 |
+
"vision_model.encoder.layers.13.norm1.bias": "model-00001-of-00004.safetensors",
|
| 436 |
+
"vision_model.encoder.layers.13.norm1.weight": "model-00001-of-00004.safetensors",
|
| 437 |
+
"vision_model.encoder.layers.13.norm2.bias": "model-00001-of-00004.safetensors",
|
| 438 |
+
"vision_model.encoder.layers.13.norm2.weight": "model-00001-of-00004.safetensors",
|
| 439 |
+
"vision_model.encoder.layers.14.attn.proj.bias": "model-00001-of-00004.safetensors",
|
| 440 |
+
"vision_model.encoder.layers.14.attn.proj.weight": "model-00001-of-00004.safetensors",
|
| 441 |
+
"vision_model.encoder.layers.14.attn.qkv.bias": "model-00001-of-00004.safetensors",
|
| 442 |
+
"vision_model.encoder.layers.14.attn.qkv.weight": "model-00001-of-00004.safetensors",
|
| 443 |
+
"vision_model.encoder.layers.14.ls1": "model-00001-of-00004.safetensors",
|
| 444 |
+
"vision_model.encoder.layers.14.ls2": "model-00001-of-00004.safetensors",
|
| 445 |
+
"vision_model.encoder.layers.14.mlp.fc1.bias": "model-00001-of-00004.safetensors",
|
| 446 |
+
"vision_model.encoder.layers.14.mlp.fc1.weight": "model-00001-of-00004.safetensors",
|
| 447 |
+
"vision_model.encoder.layers.14.mlp.fc2.bias": "model-00001-of-00004.safetensors",
|
| 448 |
+
"vision_model.encoder.layers.14.mlp.fc2.weight": "model-00001-of-00004.safetensors",
|
| 449 |
+
"vision_model.encoder.layers.14.norm1.bias": "model-00001-of-00004.safetensors",
|
| 450 |
+
"vision_model.encoder.layers.14.norm1.weight": "model-00001-of-00004.safetensors",
|
| 451 |
+
"vision_model.encoder.layers.14.norm2.bias": "model-00001-of-00004.safetensors",
|
| 452 |
+
"vision_model.encoder.layers.14.norm2.weight": "model-00001-of-00004.safetensors",
|
| 453 |
+
"vision_model.encoder.layers.15.attn.proj.bias": "model-00001-of-00004.safetensors",
|
| 454 |
+
"vision_model.encoder.layers.15.attn.proj.weight": "model-00001-of-00004.safetensors",
|
| 455 |
+
"vision_model.encoder.layers.15.attn.qkv.bias": "model-00001-of-00004.safetensors",
|
| 456 |
+
"vision_model.encoder.layers.15.attn.qkv.weight": "model-00001-of-00004.safetensors",
|
| 457 |
+
"vision_model.encoder.layers.15.ls1": "model-00001-of-00004.safetensors",
|
| 458 |
+
"vision_model.encoder.layers.15.ls2": "model-00001-of-00004.safetensors",
|
| 459 |
+
"vision_model.encoder.layers.15.mlp.fc1.bias": "model-00001-of-00004.safetensors",
|
| 460 |
+
"vision_model.encoder.layers.15.mlp.fc1.weight": "model-00001-of-00004.safetensors",
|
| 461 |
+
"vision_model.encoder.layers.15.mlp.fc2.bias": "model-00001-of-00004.safetensors",
|
| 462 |
+
"vision_model.encoder.layers.15.mlp.fc2.weight": "model-00001-of-00004.safetensors",
|
| 463 |
+
"vision_model.encoder.layers.15.norm1.bias": "model-00001-of-00004.safetensors",
|
| 464 |
+
"vision_model.encoder.layers.15.norm1.weight": "model-00001-of-00004.safetensors",
|
| 465 |
+
"vision_model.encoder.layers.15.norm2.bias": "model-00001-of-00004.safetensors",
|
| 466 |
+
"vision_model.encoder.layers.15.norm2.weight": "model-00001-of-00004.safetensors",
|
| 467 |
+
"vision_model.encoder.layers.16.attn.proj.bias": "model-00001-of-00004.safetensors",
|
| 468 |
+
"vision_model.encoder.layers.16.attn.proj.weight": "model-00001-of-00004.safetensors",
|
| 469 |
+
"vision_model.encoder.layers.16.attn.qkv.bias": "model-00001-of-00004.safetensors",
|
| 470 |
+
"vision_model.encoder.layers.16.attn.qkv.weight": "model-00001-of-00004.safetensors",
|
| 471 |
+
"vision_model.encoder.layers.16.ls1": "model-00001-of-00004.safetensors",
|
| 472 |
+
"vision_model.encoder.layers.16.ls2": "model-00001-of-00004.safetensors",
|
| 473 |
+
"vision_model.encoder.layers.16.mlp.fc1.bias": "model-00001-of-00004.safetensors",
|
| 474 |
+
"vision_model.encoder.layers.16.mlp.fc1.weight": "model-00001-of-00004.safetensors",
|
| 475 |
+
"vision_model.encoder.layers.16.mlp.fc2.bias": "model-00001-of-00004.safetensors",
|
| 476 |
+
"vision_model.encoder.layers.16.mlp.fc2.weight": "model-00001-of-00004.safetensors",
|
| 477 |
+
"vision_model.encoder.layers.16.norm1.bias": "model-00001-of-00004.safetensors",
|
| 478 |
+
"vision_model.encoder.layers.16.norm1.weight": "model-00001-of-00004.safetensors",
|
| 479 |
+
"vision_model.encoder.layers.16.norm2.bias": "model-00001-of-00004.safetensors",
|
| 480 |
+
"vision_model.encoder.layers.16.norm2.weight": "model-00001-of-00004.safetensors",
|
| 481 |
+
"vision_model.encoder.layers.17.attn.proj.bias": "model-00001-of-00004.safetensors",
|
| 482 |
+
"vision_model.encoder.layers.17.attn.proj.weight": "model-00001-of-00004.safetensors",
|
| 483 |
+
"vision_model.encoder.layers.17.attn.qkv.bias": "model-00001-of-00004.safetensors",
|
| 484 |
+
"vision_model.encoder.layers.17.attn.qkv.weight": "model-00001-of-00004.safetensors",
|
| 485 |
+
"vision_model.encoder.layers.17.ls1": "model-00001-of-00004.safetensors",
|
| 486 |
+
"vision_model.encoder.layers.17.ls2": "model-00001-of-00004.safetensors",
|
| 487 |
+
"vision_model.encoder.layers.17.mlp.fc1.bias": "model-00001-of-00004.safetensors",
|
| 488 |
+
"vision_model.encoder.layers.17.mlp.fc1.weight": "model-00001-of-00004.safetensors",
|
| 489 |
+
"vision_model.encoder.layers.17.mlp.fc2.bias": "model-00001-of-00004.safetensors",
|
| 490 |
+
"vision_model.encoder.layers.17.mlp.fc2.weight": "model-00001-of-00004.safetensors",
|
| 491 |
+
"vision_model.encoder.layers.17.norm1.bias": "model-00001-of-00004.safetensors",
|
| 492 |
+
"vision_model.encoder.layers.17.norm1.weight": "model-00001-of-00004.safetensors",
|
| 493 |
+
"vision_model.encoder.layers.17.norm2.bias": "model-00001-of-00004.safetensors",
|
| 494 |
+
"vision_model.encoder.layers.17.norm2.weight": "model-00001-of-00004.safetensors",
|
| 495 |
+
"vision_model.encoder.layers.18.attn.proj.bias": "model-00001-of-00004.safetensors",
|
| 496 |
+
"vision_model.encoder.layers.18.attn.proj.weight": "model-00001-of-00004.safetensors",
|
| 497 |
+
"vision_model.encoder.layers.18.attn.qkv.bias": "model-00001-of-00004.safetensors",
|
| 498 |
+
"vision_model.encoder.layers.18.attn.qkv.weight": "model-00001-of-00004.safetensors",
|
| 499 |
+
"vision_model.encoder.layers.18.ls1": "model-00001-of-00004.safetensors",
|
| 500 |
+
"vision_model.encoder.layers.18.ls2": "model-00001-of-00004.safetensors",
|
| 501 |
+
"vision_model.encoder.layers.18.mlp.fc1.bias": "model-00001-of-00004.safetensors",
|
| 502 |
+
"vision_model.encoder.layers.18.mlp.fc1.weight": "model-00001-of-00004.safetensors",
|
| 503 |
+
"vision_model.encoder.layers.18.mlp.fc2.bias": "model-00001-of-00004.safetensors",
|
| 504 |
+
"vision_model.encoder.layers.18.mlp.fc2.weight": "model-00001-of-00004.safetensors",
|
| 505 |
+
"vision_model.encoder.layers.18.norm1.bias": "model-00001-of-00004.safetensors",
|
| 506 |
+
"vision_model.encoder.layers.18.norm1.weight": "model-00001-of-00004.safetensors",
|
| 507 |
+
"vision_model.encoder.layers.18.norm2.bias": "model-00001-of-00004.safetensors",
|
| 508 |
+
"vision_model.encoder.layers.18.norm2.weight": "model-00001-of-00004.safetensors",
|
| 509 |
+
"vision_model.encoder.layers.19.attn.proj.bias": "model-00001-of-00004.safetensors",
|
| 510 |
+
"vision_model.encoder.layers.19.attn.proj.weight": "model-00001-of-00004.safetensors",
|
| 511 |
+
"vision_model.encoder.layers.19.attn.qkv.bias": "model-00001-of-00004.safetensors",
|
| 512 |
+
"vision_model.encoder.layers.19.attn.qkv.weight": "model-00001-of-00004.safetensors",
|
| 513 |
+
"vision_model.encoder.layers.19.ls1": "model-00001-of-00004.safetensors",
|
| 514 |
+
"vision_model.encoder.layers.19.ls2": "model-00001-of-00004.safetensors",
|
| 515 |
+
"vision_model.encoder.layers.19.mlp.fc1.bias": "model-00001-of-00004.safetensors",
|
| 516 |
+
"vision_model.encoder.layers.19.mlp.fc1.weight": "model-00001-of-00004.safetensors",
|
| 517 |
+
"vision_model.encoder.layers.19.mlp.fc2.bias": "model-00001-of-00004.safetensors",
|
| 518 |
+
"vision_model.encoder.layers.19.mlp.fc2.weight": "model-00001-of-00004.safetensors",
|
| 519 |
+
"vision_model.encoder.layers.19.norm1.bias": "model-00001-of-00004.safetensors",
|
| 520 |
+
"vision_model.encoder.layers.19.norm1.weight": "model-00001-of-00004.safetensors",
|
| 521 |
+
"vision_model.encoder.layers.19.norm2.bias": "model-00001-of-00004.safetensors",
|
| 522 |
+
"vision_model.encoder.layers.19.norm2.weight": "model-00001-of-00004.safetensors",
|
| 523 |
+
"vision_model.encoder.layers.2.attn.proj.bias": "model-00001-of-00004.safetensors",
|
| 524 |
+
"vision_model.encoder.layers.2.attn.proj.weight": "model-00001-of-00004.safetensors",
|
| 525 |
+
"vision_model.encoder.layers.2.attn.qkv.bias": "model-00001-of-00004.safetensors",
|
| 526 |
+
"vision_model.encoder.layers.2.attn.qkv.weight": "model-00001-of-00004.safetensors",
|
| 527 |
+
"vision_model.encoder.layers.2.ls1": "model-00001-of-00004.safetensors",
|
| 528 |
+
"vision_model.encoder.layers.2.ls2": "model-00001-of-00004.safetensors",
|
| 529 |
+
"vision_model.encoder.layers.2.mlp.fc1.bias": "model-00001-of-00004.safetensors",
|
| 530 |
+
"vision_model.encoder.layers.2.mlp.fc1.weight": "model-00001-of-00004.safetensors",
|
| 531 |
+
"vision_model.encoder.layers.2.mlp.fc2.bias": "model-00001-of-00004.safetensors",
|
| 532 |
+
"vision_model.encoder.layers.2.mlp.fc2.weight": "model-00001-of-00004.safetensors",
|
| 533 |
+
"vision_model.encoder.layers.2.norm1.bias": "model-00001-of-00004.safetensors",
|
| 534 |
+
"vision_model.encoder.layers.2.norm1.weight": "model-00001-of-00004.safetensors",
|
| 535 |
+
"vision_model.encoder.layers.2.norm2.bias": "model-00001-of-00004.safetensors",
|
| 536 |
+
"vision_model.encoder.layers.2.norm2.weight": "model-00001-of-00004.safetensors",
|
| 537 |
+
"vision_model.encoder.layers.20.attn.proj.bias": "model-00001-of-00004.safetensors",
|
| 538 |
+
"vision_model.encoder.layers.20.attn.proj.weight": "model-00001-of-00004.safetensors",
|
| 539 |
+
"vision_model.encoder.layers.20.attn.qkv.bias": "model-00001-of-00004.safetensors",
|
| 540 |
+
"vision_model.encoder.layers.20.attn.qkv.weight": "model-00001-of-00004.safetensors",
|
| 541 |
+
"vision_model.encoder.layers.20.ls1": "model-00001-of-00004.safetensors",
|
| 542 |
+
"vision_model.encoder.layers.20.ls2": "model-00001-of-00004.safetensors",
|
| 543 |
+
"vision_model.encoder.layers.20.mlp.fc1.bias": "model-00001-of-00004.safetensors",
|
| 544 |
+
"vision_model.encoder.layers.20.mlp.fc1.weight": "model-00001-of-00004.safetensors",
|
| 545 |
+
"vision_model.encoder.layers.20.mlp.fc2.bias": "model-00001-of-00004.safetensors",
|
| 546 |
+
"vision_model.encoder.layers.20.mlp.fc2.weight": "model-00001-of-00004.safetensors",
|
| 547 |
+
"vision_model.encoder.layers.20.norm1.bias": "model-00001-of-00004.safetensors",
|
| 548 |
+
"vision_model.encoder.layers.20.norm1.weight": "model-00001-of-00004.safetensors",
|
| 549 |
+
"vision_model.encoder.layers.20.norm2.bias": "model-00001-of-00004.safetensors",
|
| 550 |
+
"vision_model.encoder.layers.20.norm2.weight": "model-00001-of-00004.safetensors",
|
| 551 |
+
"vision_model.encoder.layers.21.attn.proj.bias": "model-00001-of-00004.safetensors",
|
| 552 |
+
"vision_model.encoder.layers.21.attn.proj.weight": "model-00001-of-00004.safetensors",
|
| 553 |
+
"vision_model.encoder.layers.21.attn.qkv.bias": "model-00001-of-00004.safetensors",
|
| 554 |
+
"vision_model.encoder.layers.21.attn.qkv.weight": "model-00001-of-00004.safetensors",
|
| 555 |
+
"vision_model.encoder.layers.21.ls1": "model-00001-of-00004.safetensors",
|
| 556 |
+
"vision_model.encoder.layers.21.ls2": "model-00001-of-00004.safetensors",
|
| 557 |
+
"vision_model.encoder.layers.21.mlp.fc1.bias": "model-00001-of-00004.safetensors",
|
| 558 |
+
"vision_model.encoder.layers.21.mlp.fc1.weight": "model-00001-of-00004.safetensors",
|
| 559 |
+
"vision_model.encoder.layers.21.mlp.fc2.bias": "model-00001-of-00004.safetensors",
|
| 560 |
+
"vision_model.encoder.layers.21.mlp.fc2.weight": "model-00001-of-00004.safetensors",
|
| 561 |
+
"vision_model.encoder.layers.21.norm1.bias": "model-00001-of-00004.safetensors",
|
| 562 |
+
"vision_model.encoder.layers.21.norm1.weight": "model-00001-of-00004.safetensors",
|
| 563 |
+
"vision_model.encoder.layers.21.norm2.bias": "model-00001-of-00004.safetensors",
|
| 564 |
+
"vision_model.encoder.layers.21.norm2.weight": "model-00001-of-00004.safetensors",
|
| 565 |
+
"vision_model.encoder.layers.22.attn.proj.bias": "model-00001-of-00004.safetensors",
|
| 566 |
+
"vision_model.encoder.layers.22.attn.proj.weight": "model-00001-of-00004.safetensors",
|
| 567 |
+
"vision_model.encoder.layers.22.attn.qkv.bias": "model-00001-of-00004.safetensors",
|
| 568 |
+
"vision_model.encoder.layers.22.attn.qkv.weight": "model-00001-of-00004.safetensors",
|
| 569 |
+
"vision_model.encoder.layers.22.ls1": "model-00001-of-00004.safetensors",
|
| 570 |
+
"vision_model.encoder.layers.22.ls2": "model-00001-of-00004.safetensors",
|
| 571 |
+
"vision_model.encoder.layers.22.mlp.fc1.bias": "model-00001-of-00004.safetensors",
|
| 572 |
+
"vision_model.encoder.layers.22.mlp.fc1.weight": "model-00001-of-00004.safetensors",
|
| 573 |
+
"vision_model.encoder.layers.22.mlp.fc2.bias": "model-00001-of-00004.safetensors",
|
| 574 |
+
"vision_model.encoder.layers.22.mlp.fc2.weight": "model-00001-of-00004.safetensors",
|
| 575 |
+
"vision_model.encoder.layers.22.norm1.bias": "model-00001-of-00004.safetensors",
|
| 576 |
+
"vision_model.encoder.layers.22.norm1.weight": "model-00001-of-00004.safetensors",
|
| 577 |
+
"vision_model.encoder.layers.22.norm2.bias": "model-00001-of-00004.safetensors",
|
| 578 |
+
"vision_model.encoder.layers.22.norm2.weight": "model-00001-of-00004.safetensors",
|
| 579 |
+
"vision_model.encoder.layers.23.attn.proj.bias": "model-00001-of-00004.safetensors",
|
| 580 |
+
"vision_model.encoder.layers.23.attn.proj.weight": "model-00001-of-00004.safetensors",
|
| 581 |
+
"vision_model.encoder.layers.23.attn.qkv.bias": "model-00001-of-00004.safetensors",
|
| 582 |
+
"vision_model.encoder.layers.23.attn.qkv.weight": "model-00001-of-00004.safetensors",
|
| 583 |
+
"vision_model.encoder.layers.23.ls1": "model-00001-of-00004.safetensors",
|
| 584 |
+
"vision_model.encoder.layers.23.ls2": "model-00001-of-00004.safetensors",
|
| 585 |
+
"vision_model.encoder.layers.23.mlp.fc1.bias": "model-00001-of-00004.safetensors",
|
| 586 |
+
"vision_model.encoder.layers.23.mlp.fc1.weight": "model-00001-of-00004.safetensors",
|
| 587 |
+
"vision_model.encoder.layers.23.mlp.fc2.bias": "model-00001-of-00004.safetensors",
|
| 588 |
+
"vision_model.encoder.layers.23.mlp.fc2.weight": "model-00001-of-00004.safetensors",
|
| 589 |
+
"vision_model.encoder.layers.23.norm1.bias": "model-00001-of-00004.safetensors",
|
| 590 |
+
"vision_model.encoder.layers.23.norm1.weight": "model-00001-of-00004.safetensors",
|
| 591 |
+
"vision_model.encoder.layers.23.norm2.bias": "model-00001-of-00004.safetensors",
|
| 592 |
+
"vision_model.encoder.layers.23.norm2.weight": "model-00001-of-00004.safetensors",
|
| 593 |
+
"vision_model.encoder.layers.3.attn.proj.bias": "model-00001-of-00004.safetensors",
|
| 594 |
+
"vision_model.encoder.layers.3.attn.proj.weight": "model-00001-of-00004.safetensors",
|
| 595 |
+
"vision_model.encoder.layers.3.attn.qkv.bias": "model-00001-of-00004.safetensors",
|
| 596 |
+
"vision_model.encoder.layers.3.attn.qkv.weight": "model-00001-of-00004.safetensors",
|
| 597 |
+
"vision_model.encoder.layers.3.ls1": "model-00001-of-00004.safetensors",
|
| 598 |
+
"vision_model.encoder.layers.3.ls2": "model-00001-of-00004.safetensors",
|
| 599 |
+
"vision_model.encoder.layers.3.mlp.fc1.bias": "model-00001-of-00004.safetensors",
|
| 600 |
+
"vision_model.encoder.layers.3.mlp.fc1.weight": "model-00001-of-00004.safetensors",
|
| 601 |
+
"vision_model.encoder.layers.3.mlp.fc2.bias": "model-00001-of-00004.safetensors",
|
| 602 |
+
"vision_model.encoder.layers.3.mlp.fc2.weight": "model-00001-of-00004.safetensors",
|
| 603 |
+
"vision_model.encoder.layers.3.norm1.bias": "model-00001-of-00004.safetensors",
|
| 604 |
+
"vision_model.encoder.layers.3.norm1.weight": "model-00001-of-00004.safetensors",
|
| 605 |
+
"vision_model.encoder.layers.3.norm2.bias": "model-00001-of-00004.safetensors",
|
| 606 |
+
"vision_model.encoder.layers.3.norm2.weight": "model-00001-of-00004.safetensors",
|
| 607 |
+
"vision_model.encoder.layers.4.attn.proj.bias": "model-00001-of-00004.safetensors",
|
| 608 |
+
"vision_model.encoder.layers.4.attn.proj.weight": "model-00001-of-00004.safetensors",
|
| 609 |
+
"vision_model.encoder.layers.4.attn.qkv.bias": "model-00001-of-00004.safetensors",
|
| 610 |
+
"vision_model.encoder.layers.4.attn.qkv.weight": "model-00001-of-00004.safetensors",
|
| 611 |
+
"vision_model.encoder.layers.4.ls1": "model-00001-of-00004.safetensors",
|
| 612 |
+
"vision_model.encoder.layers.4.ls2": "model-00001-of-00004.safetensors",
|
| 613 |
+
"vision_model.encoder.layers.4.mlp.fc1.bias": "model-00001-of-00004.safetensors",
|
| 614 |
+
"vision_model.encoder.layers.4.mlp.fc1.weight": "model-00001-of-00004.safetensors",
|
| 615 |
+
"vision_model.encoder.layers.4.mlp.fc2.bias": "model-00001-of-00004.safetensors",
|
| 616 |
+
"vision_model.encoder.layers.4.mlp.fc2.weight": "model-00001-of-00004.safetensors",
|
| 617 |
+
"vision_model.encoder.layers.4.norm1.bias": "model-00001-of-00004.safetensors",
|
| 618 |
+
"vision_model.encoder.layers.4.norm1.weight": "model-00001-of-00004.safetensors",
|
| 619 |
+
"vision_model.encoder.layers.4.norm2.bias": "model-00001-of-00004.safetensors",
|
| 620 |
+
"vision_model.encoder.layers.4.norm2.weight": "model-00001-of-00004.safetensors",
|
| 621 |
+
"vision_model.encoder.layers.5.attn.proj.bias": "model-00001-of-00004.safetensors",
|
| 622 |
+
"vision_model.encoder.layers.5.attn.proj.weight": "model-00001-of-00004.safetensors",
|
| 623 |
+
"vision_model.encoder.layers.5.attn.qkv.bias": "model-00001-of-00004.safetensors",
|
| 624 |
+
"vision_model.encoder.layers.5.attn.qkv.weight": "model-00001-of-00004.safetensors",
|
| 625 |
+
"vision_model.encoder.layers.5.ls1": "model-00001-of-00004.safetensors",
|
| 626 |
+
"vision_model.encoder.layers.5.ls2": "model-00001-of-00004.safetensors",
|
| 627 |
+
"vision_model.encoder.layers.5.mlp.fc1.bias": "model-00001-of-00004.safetensors",
|
| 628 |
+
"vision_model.encoder.layers.5.mlp.fc1.weight": "model-00001-of-00004.safetensors",
|
| 629 |
+
"vision_model.encoder.layers.5.mlp.fc2.bias": "model-00001-of-00004.safetensors",
|
| 630 |
+
"vision_model.encoder.layers.5.mlp.fc2.weight": "model-00001-of-00004.safetensors",
|
| 631 |
+
"vision_model.encoder.layers.5.norm1.bias": "model-00001-of-00004.safetensors",
|
| 632 |
+
"vision_model.encoder.layers.5.norm1.weight": "model-00001-of-00004.safetensors",
|
| 633 |
+
"vision_model.encoder.layers.5.norm2.bias": "model-00001-of-00004.safetensors",
|
| 634 |
+
"vision_model.encoder.layers.5.norm2.weight": "model-00001-of-00004.safetensors",
|
| 635 |
+
"vision_model.encoder.layers.6.attn.proj.bias": "model-00001-of-00004.safetensors",
|
| 636 |
+
"vision_model.encoder.layers.6.attn.proj.weight": "model-00001-of-00004.safetensors",
|
| 637 |
+
"vision_model.encoder.layers.6.attn.qkv.bias": "model-00001-of-00004.safetensors",
|
| 638 |
+
"vision_model.encoder.layers.6.attn.qkv.weight": "model-00001-of-00004.safetensors",
|
| 639 |
+
"vision_model.encoder.layers.6.ls1": "model-00001-of-00004.safetensors",
|
| 640 |
+
"vision_model.encoder.layers.6.ls2": "model-00001-of-00004.safetensors",
|
| 641 |
+
"vision_model.encoder.layers.6.mlp.fc1.bias": "model-00001-of-00004.safetensors",
|
| 642 |
+
"vision_model.encoder.layers.6.mlp.fc1.weight": "model-00001-of-00004.safetensors",
|
| 643 |
+
"vision_model.encoder.layers.6.mlp.fc2.bias": "model-00001-of-00004.safetensors",
|
| 644 |
+
"vision_model.encoder.layers.6.mlp.fc2.weight": "model-00001-of-00004.safetensors",
|
| 645 |
+
"vision_model.encoder.layers.6.norm1.bias": "model-00001-of-00004.safetensors",
|
| 646 |
+
"vision_model.encoder.layers.6.norm1.weight": "model-00001-of-00004.safetensors",
|
| 647 |
+
"vision_model.encoder.layers.6.norm2.bias": "model-00001-of-00004.safetensors",
|
| 648 |
+
"vision_model.encoder.layers.6.norm2.weight": "model-00001-of-00004.safetensors",
|
| 649 |
+
"vision_model.encoder.layers.7.attn.proj.bias": "model-00001-of-00004.safetensors",
|
| 650 |
+
"vision_model.encoder.layers.7.attn.proj.weight": "model-00001-of-00004.safetensors",
|
| 651 |
+
"vision_model.encoder.layers.7.attn.qkv.bias": "model-00001-of-00004.safetensors",
|
| 652 |
+
"vision_model.encoder.layers.7.attn.qkv.weight": "model-00001-of-00004.safetensors",
|
| 653 |
+
"vision_model.encoder.layers.7.ls1": "model-00001-of-00004.safetensors",
|
| 654 |
+
"vision_model.encoder.layers.7.ls2": "model-00001-of-00004.safetensors",
|
| 655 |
+
"vision_model.encoder.layers.7.mlp.fc1.bias": "model-00001-of-00004.safetensors",
|
| 656 |
+
"vision_model.encoder.layers.7.mlp.fc1.weight": "model-00001-of-00004.safetensors",
|
| 657 |
+
"vision_model.encoder.layers.7.mlp.fc2.bias": "model-00001-of-00004.safetensors",
|
| 658 |
+
"vision_model.encoder.layers.7.mlp.fc2.weight": "model-00001-of-00004.safetensors",
|
| 659 |
+
"vision_model.encoder.layers.7.norm1.bias": "model-00001-of-00004.safetensors",
|
| 660 |
+
"vision_model.encoder.layers.7.norm1.weight": "model-00001-of-00004.safetensors",
|
| 661 |
+
"vision_model.encoder.layers.7.norm2.bias": "model-00001-of-00004.safetensors",
|
| 662 |
+
"vision_model.encoder.layers.7.norm2.weight": "model-00001-of-00004.safetensors",
|
| 663 |
+
"vision_model.encoder.layers.8.attn.proj.bias": "model-00001-of-00004.safetensors",
|
| 664 |
+
"vision_model.encoder.layers.8.attn.proj.weight": "model-00001-of-00004.safetensors",
|
| 665 |
+
"vision_model.encoder.layers.8.attn.qkv.bias": "model-00001-of-00004.safetensors",
|
| 666 |
+
"vision_model.encoder.layers.8.attn.qkv.weight": "model-00001-of-00004.safetensors",
|
| 667 |
+
"vision_model.encoder.layers.8.ls1": "model-00001-of-00004.safetensors",
|
| 668 |
+
"vision_model.encoder.layers.8.ls2": "model-00001-of-00004.safetensors",
|
| 669 |
+
"vision_model.encoder.layers.8.mlp.fc1.bias": "model-00001-of-00004.safetensors",
|
| 670 |
+
"vision_model.encoder.layers.8.mlp.fc1.weight": "model-00001-of-00004.safetensors",
|
| 671 |
+
"vision_model.encoder.layers.8.mlp.fc2.bias": "model-00001-of-00004.safetensors",
|
| 672 |
+
"vision_model.encoder.layers.8.mlp.fc2.weight": "model-00001-of-00004.safetensors",
|
| 673 |
+
"vision_model.encoder.layers.8.norm1.bias": "model-00001-of-00004.safetensors",
|
| 674 |
+
"vision_model.encoder.layers.8.norm1.weight": "model-00001-of-00004.safetensors",
|
| 675 |
+
"vision_model.encoder.layers.8.norm2.bias": "model-00001-of-00004.safetensors",
|
| 676 |
+
"vision_model.encoder.layers.8.norm2.weight": "model-00001-of-00004.safetensors",
|
| 677 |
+
"vision_model.encoder.layers.9.attn.proj.bias": "model-00001-of-00004.safetensors",
|
| 678 |
+
"vision_model.encoder.layers.9.attn.proj.weight": "model-00001-of-00004.safetensors",
|
| 679 |
+
"vision_model.encoder.layers.9.attn.qkv.bias": "model-00001-of-00004.safetensors",
|
| 680 |
+
"vision_model.encoder.layers.9.attn.qkv.weight": "model-00001-of-00004.safetensors",
|
| 681 |
+
"vision_model.encoder.layers.9.ls1": "model-00001-of-00004.safetensors",
|
| 682 |
+
"vision_model.encoder.layers.9.ls2": "model-00001-of-00004.safetensors",
|
| 683 |
+
"vision_model.encoder.layers.9.mlp.fc1.bias": "model-00001-of-00004.safetensors",
|
| 684 |
+
"vision_model.encoder.layers.9.mlp.fc1.weight": "model-00001-of-00004.safetensors",
|
| 685 |
+
"vision_model.encoder.layers.9.mlp.fc2.bias": "model-00001-of-00004.safetensors",
|
| 686 |
+
"vision_model.encoder.layers.9.mlp.fc2.weight": "model-00001-of-00004.safetensors",
|
| 687 |
+
"vision_model.encoder.layers.9.norm1.bias": "model-00001-of-00004.safetensors",
|
| 688 |
+
"vision_model.encoder.layers.9.norm1.weight": "model-00001-of-00004.safetensors",
|
| 689 |
+
"vision_model.encoder.layers.9.norm2.bias": "model-00001-of-00004.safetensors",
|
| 690 |
+
"vision_model.encoder.layers.9.norm2.weight": "model-00001-of-00004.safetensors"
|
| 691 |
+
}
|
| 692 |
+
}
|
modeling_intern_vit.py
ADDED
|
@@ -0,0 +1,431 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# --------------------------------------------------------
|
| 2 |
+
# InternVL
|
| 3 |
+
# Copyright (c) 2024 OpenGVLab
|
| 4 |
+
# Licensed under The MIT License [see LICENSE for details]
|
| 5 |
+
# --------------------------------------------------------
|
| 6 |
+
|
| 7 |
+
from typing import Optional, Tuple, Union
|
| 8 |
+
|
| 9 |
+
import torch
|
| 10 |
+
import torch.nn.functional as F
|
| 11 |
+
import torch.utils.checkpoint
|
| 12 |
+
from einops import rearrange
|
| 13 |
+
from timm.models.layers import DropPath
|
| 14 |
+
from torch import nn
|
| 15 |
+
from transformers.activations import ACT2FN
|
| 16 |
+
from transformers.modeling_outputs import (BaseModelOutput,
|
| 17 |
+
BaseModelOutputWithPooling)
|
| 18 |
+
from transformers.modeling_utils import PreTrainedModel
|
| 19 |
+
from transformers.utils import logging
|
| 20 |
+
|
| 21 |
+
from .configuration_intern_vit import InternVisionConfig
|
| 22 |
+
|
| 23 |
+
try:
|
| 24 |
+
from flash_attn.bert_padding import pad_input, unpad_input
|
| 25 |
+
from flash_attn.flash_attn_interface import \
|
| 26 |
+
flash_attn_varlen_qkvpacked_func
|
| 27 |
+
has_flash_attn = True
|
| 28 |
+
except:
|
| 29 |
+
print('FlashAttention2 is not installed.')
|
| 30 |
+
has_flash_attn = False
|
| 31 |
+
|
| 32 |
+
logger = logging.get_logger(__name__)
|
| 33 |
+
|
| 34 |
+
|
| 35 |
+
class FlashAttention(nn.Module):
|
| 36 |
+
"""Implement the scaled dot product attention with softmax.
|
| 37 |
+
Arguments
|
| 38 |
+
---------
|
| 39 |
+
softmax_scale: The temperature to use for the softmax attention.
|
| 40 |
+
(default: 1/sqrt(d_keys) where d_keys is computed at
|
| 41 |
+
runtime)
|
| 42 |
+
attention_dropout: The dropout rate to apply to the attention
|
| 43 |
+
(default: 0.0)
|
| 44 |
+
"""
|
| 45 |
+
|
| 46 |
+
def __init__(self, softmax_scale=None, attention_dropout=0.0, device=None, dtype=None):
|
| 47 |
+
super().__init__()
|
| 48 |
+
self.softmax_scale = softmax_scale
|
| 49 |
+
self.dropout_p = attention_dropout
|
| 50 |
+
|
| 51 |
+
def forward(self, qkv, key_padding_mask=None, causal=False, cu_seqlens=None,
|
| 52 |
+
max_s=None, need_weights=False):
|
| 53 |
+
"""Implements the multihead softmax attention.
|
| 54 |
+
Arguments
|
| 55 |
+
---------
|
| 56 |
+
qkv: The tensor containing the query, key, and value. (B, S, 3, H, D) if key_padding_mask is None
|
| 57 |
+
if unpadded: (nnz, 3, h, d)
|
| 58 |
+
key_padding_mask: a bool tensor of shape (B, S)
|
| 59 |
+
"""
|
| 60 |
+
assert not need_weights
|
| 61 |
+
assert qkv.dtype in [torch.float16, torch.bfloat16]
|
| 62 |
+
assert qkv.is_cuda
|
| 63 |
+
|
| 64 |
+
if cu_seqlens is None:
|
| 65 |
+
batch_size = qkv.shape[0]
|
| 66 |
+
seqlen = qkv.shape[1]
|
| 67 |
+
if key_padding_mask is None:
|
| 68 |
+
qkv = rearrange(qkv, 'b s ... -> (b s) ...')
|
| 69 |
+
max_s = seqlen
|
| 70 |
+
cu_seqlens = torch.arange(0, (batch_size + 1) * seqlen, step=seqlen, dtype=torch.int32,
|
| 71 |
+
device=qkv.device)
|
| 72 |
+
output = flash_attn_varlen_qkvpacked_func(
|
| 73 |
+
qkv, cu_seqlens, max_s, self.dropout_p if self.training else 0.0,
|
| 74 |
+
softmax_scale=self.softmax_scale, causal=causal
|
| 75 |
+
)
|
| 76 |
+
output = rearrange(output, '(b s) ... -> b s ...', b=batch_size)
|
| 77 |
+
else:
|
| 78 |
+
nheads = qkv.shape[-2]
|
| 79 |
+
x = rearrange(qkv, 'b s three h d -> b s (three h d)')
|
| 80 |
+
x_unpad, indices, cu_seqlens, max_s = unpad_input(x, key_padding_mask)
|
| 81 |
+
x_unpad = rearrange(x_unpad, 'nnz (three h d) -> nnz three h d', three=3, h=nheads)
|
| 82 |
+
output_unpad = flash_attn_varlen_qkvpacked_func(
|
| 83 |
+
x_unpad, cu_seqlens, max_s, self.dropout_p if self.training else 0.0,
|
| 84 |
+
softmax_scale=self.softmax_scale, causal=causal
|
| 85 |
+
)
|
| 86 |
+
output = rearrange(pad_input(rearrange(output_unpad, 'nnz h d -> nnz (h d)'),
|
| 87 |
+
indices, batch_size, seqlen),
|
| 88 |
+
'b s (h d) -> b s h d', h=nheads)
|
| 89 |
+
else:
|
| 90 |
+
assert max_s is not None
|
| 91 |
+
output = flash_attn_varlen_qkvpacked_func(
|
| 92 |
+
qkv, cu_seqlens, max_s, self.dropout_p if self.training else 0.0,
|
| 93 |
+
softmax_scale=self.softmax_scale, causal=causal
|
| 94 |
+
)
|
| 95 |
+
|
| 96 |
+
return output, None
|
| 97 |
+
|
| 98 |
+
|
| 99 |
+
class InternRMSNorm(nn.Module):
|
| 100 |
+
def __init__(self, hidden_size, eps=1e-6):
|
| 101 |
+
super().__init__()
|
| 102 |
+
self.weight = nn.Parameter(torch.ones(hidden_size))
|
| 103 |
+
self.variance_epsilon = eps
|
| 104 |
+
|
| 105 |
+
def forward(self, hidden_states):
|
| 106 |
+
input_dtype = hidden_states.dtype
|
| 107 |
+
hidden_states = hidden_states.to(torch.float32)
|
| 108 |
+
variance = hidden_states.pow(2).mean(-1, keepdim=True)
|
| 109 |
+
hidden_states = hidden_states * torch.rsqrt(variance + self.variance_epsilon)
|
| 110 |
+
return self.weight * hidden_states.to(input_dtype)
|
| 111 |
+
|
| 112 |
+
|
| 113 |
+
try:
|
| 114 |
+
from apex.normalization import FusedRMSNorm
|
| 115 |
+
|
| 116 |
+
InternRMSNorm = FusedRMSNorm # noqa
|
| 117 |
+
|
| 118 |
+
logger.info('Discovered apex.normalization.FusedRMSNorm - will use it instead of InternRMSNorm')
|
| 119 |
+
except ImportError:
|
| 120 |
+
# using the normal InternRMSNorm
|
| 121 |
+
pass
|
| 122 |
+
except Exception:
|
| 123 |
+
logger.warning('discovered apex but it failed to load, falling back to InternRMSNorm')
|
| 124 |
+
pass
|
| 125 |
+
|
| 126 |
+
|
| 127 |
+
NORM2FN = {
|
| 128 |
+
'rms_norm': InternRMSNorm,
|
| 129 |
+
'layer_norm': nn.LayerNorm,
|
| 130 |
+
}
|
| 131 |
+
|
| 132 |
+
|
| 133 |
+
class InternVisionEmbeddings(nn.Module):
|
| 134 |
+
def __init__(self, config: InternVisionConfig):
|
| 135 |
+
super().__init__()
|
| 136 |
+
self.config = config
|
| 137 |
+
self.embed_dim = config.hidden_size
|
| 138 |
+
self.image_size = config.image_size
|
| 139 |
+
self.patch_size = config.patch_size
|
| 140 |
+
|
| 141 |
+
self.class_embedding = nn.Parameter(
|
| 142 |
+
torch.randn(1, 1, self.embed_dim),
|
| 143 |
+
)
|
| 144 |
+
|
| 145 |
+
self.patch_embedding = nn.Conv2d(
|
| 146 |
+
in_channels=3, out_channels=self.embed_dim, kernel_size=self.patch_size, stride=self.patch_size
|
| 147 |
+
)
|
| 148 |
+
|
| 149 |
+
self.num_patches = (self.image_size // self.patch_size) ** 2
|
| 150 |
+
self.num_positions = self.num_patches + 1
|
| 151 |
+
|
| 152 |
+
self.position_embedding = nn.Parameter(torch.randn(1, self.num_positions, self.embed_dim))
|
| 153 |
+
|
| 154 |
+
def _get_pos_embed(self, pos_embed, H, W):
|
| 155 |
+
target_dtype = pos_embed.dtype
|
| 156 |
+
pos_embed = pos_embed.float().reshape(
|
| 157 |
+
1, self.image_size // self.patch_size, self.image_size // self.patch_size, -1).permute(0, 3, 1, 2)
|
| 158 |
+
pos_embed = F.interpolate(pos_embed, size=(H, W), mode='bicubic', align_corners=False). \
|
| 159 |
+
reshape(1, -1, H * W).permute(0, 2, 1).to(target_dtype)
|
| 160 |
+
return pos_embed
|
| 161 |
+
|
| 162 |
+
def forward(self, pixel_values: torch.FloatTensor) -> torch.Tensor:
|
| 163 |
+
target_dtype = self.patch_embedding.weight.dtype
|
| 164 |
+
patch_embeds = self.patch_embedding(pixel_values) # shape = [*, channel, width, height]
|
| 165 |
+
batch_size, _, height, width = patch_embeds.shape
|
| 166 |
+
patch_embeds = patch_embeds.flatten(2).transpose(1, 2)
|
| 167 |
+
class_embeds = self.class_embedding.expand(batch_size, 1, -1).to(target_dtype)
|
| 168 |
+
embeddings = torch.cat([class_embeds, patch_embeds], dim=1)
|
| 169 |
+
position_embedding = torch.cat([
|
| 170 |
+
self.position_embedding[:, :1, :],
|
| 171 |
+
self._get_pos_embed(self.position_embedding[:, 1:, :], height, width)
|
| 172 |
+
], dim=1)
|
| 173 |
+
embeddings = embeddings + position_embedding.to(target_dtype)
|
| 174 |
+
return embeddings
|
| 175 |
+
|
| 176 |
+
|
| 177 |
+
class InternAttention(nn.Module):
|
| 178 |
+
"""Multi-headed attention from 'Attention Is All You Need' paper"""
|
| 179 |
+
|
| 180 |
+
def __init__(self, config: InternVisionConfig):
|
| 181 |
+
super().__init__()
|
| 182 |
+
self.config = config
|
| 183 |
+
self.embed_dim = config.hidden_size
|
| 184 |
+
self.num_heads = config.num_attention_heads
|
| 185 |
+
self.use_flash_attn = config.use_flash_attn and has_flash_attn
|
| 186 |
+
if config.use_flash_attn and not has_flash_attn:
|
| 187 |
+
print('Warning: Flash Attention is not available, use_flash_attn is set to False.')
|
| 188 |
+
self.head_dim = self.embed_dim // self.num_heads
|
| 189 |
+
if self.head_dim * self.num_heads != self.embed_dim:
|
| 190 |
+
raise ValueError(
|
| 191 |
+
f'embed_dim must be divisible by num_heads (got `embed_dim`: {self.embed_dim} and `num_heads`:'
|
| 192 |
+
f' {self.num_heads}).'
|
| 193 |
+
)
|
| 194 |
+
|
| 195 |
+
self.scale = self.head_dim ** -0.5
|
| 196 |
+
self.qkv = nn.Linear(self.embed_dim, 3 * self.embed_dim, bias=config.qkv_bias)
|
| 197 |
+
self.attn_drop = nn.Dropout(config.attention_dropout)
|
| 198 |
+
self.proj_drop = nn.Dropout(config.dropout)
|
| 199 |
+
|
| 200 |
+
self.qk_normalization = config.qk_normalization
|
| 201 |
+
|
| 202 |
+
if self.qk_normalization:
|
| 203 |
+
self.q_norm = InternRMSNorm(self.embed_dim, eps=config.layer_norm_eps)
|
| 204 |
+
self.k_norm = InternRMSNorm(self.embed_dim, eps=config.layer_norm_eps)
|
| 205 |
+
|
| 206 |
+
if self.use_flash_attn:
|
| 207 |
+
self.inner_attn = FlashAttention(attention_dropout=config.attention_dropout)
|
| 208 |
+
self.proj = nn.Linear(self.embed_dim, self.embed_dim)
|
| 209 |
+
|
| 210 |
+
def _naive_attn(self, x):
|
| 211 |
+
B, N, C = x.shape
|
| 212 |
+
qkv = self.qkv(x).reshape(B, N, 3, self.num_heads, C // self.num_heads).permute(2, 0, 3, 1, 4)
|
| 213 |
+
q, k, v = qkv.unbind(0) # make torchscript happy (cannot use tensor as tuple)
|
| 214 |
+
|
| 215 |
+
if self.qk_normalization:
|
| 216 |
+
B_, H_, N_, D_ = q.shape
|
| 217 |
+
q = self.q_norm(q.transpose(1, 2).flatten(-2, -1)).view(B_, N_, H_, D_).transpose(1, 2)
|
| 218 |
+
k = self.k_norm(k.transpose(1, 2).flatten(-2, -1)).view(B_, N_, H_, D_).transpose(1, 2)
|
| 219 |
+
|
| 220 |
+
attn = ((q * self.scale) @ k.transpose(-2, -1))
|
| 221 |
+
attn = attn.softmax(dim=-1)
|
| 222 |
+
attn = self.attn_drop(attn)
|
| 223 |
+
|
| 224 |
+
x = (attn @ v).transpose(1, 2).reshape(B, N, C)
|
| 225 |
+
x = self.proj(x)
|
| 226 |
+
x = self.proj_drop(x)
|
| 227 |
+
return x
|
| 228 |
+
|
| 229 |
+
def _flash_attn(self, x, key_padding_mask=None, need_weights=False):
|
| 230 |
+
qkv = self.qkv(x)
|
| 231 |
+
qkv = rearrange(qkv, 'b s (three h d) -> b s three h d', three=3, h=self.num_heads)
|
| 232 |
+
|
| 233 |
+
if self.qk_normalization:
|
| 234 |
+
q, k, v = qkv.unbind(2)
|
| 235 |
+
q = self.q_norm(q.flatten(-2, -1)).view(q.shape)
|
| 236 |
+
k = self.k_norm(k.flatten(-2, -1)).view(k.shape)
|
| 237 |
+
qkv = torch.stack([q, k, v], dim=2)
|
| 238 |
+
|
| 239 |
+
context, _ = self.inner_attn(
|
| 240 |
+
qkv, key_padding_mask=key_padding_mask, need_weights=need_weights, causal=False
|
| 241 |
+
)
|
| 242 |
+
outs = self.proj(rearrange(context, 'b s h d -> b s (h d)'))
|
| 243 |
+
outs = self.proj_drop(outs)
|
| 244 |
+
return outs
|
| 245 |
+
|
| 246 |
+
def forward(self, hidden_states: torch.Tensor) -> torch.Tensor:
|
| 247 |
+
x = self._naive_attn(hidden_states) if not self.use_flash_attn else self._flash_attn(hidden_states)
|
| 248 |
+
return x
|
| 249 |
+
|
| 250 |
+
|
| 251 |
+
class InternMLP(nn.Module):
|
| 252 |
+
def __init__(self, config: InternVisionConfig):
|
| 253 |
+
super().__init__()
|
| 254 |
+
self.config = config
|
| 255 |
+
self.act = ACT2FN[config.hidden_act]
|
| 256 |
+
self.fc1 = nn.Linear(config.hidden_size, config.intermediate_size)
|
| 257 |
+
self.fc2 = nn.Linear(config.intermediate_size, config.hidden_size)
|
| 258 |
+
|
| 259 |
+
def forward(self, hidden_states: torch.Tensor) -> torch.Tensor:
|
| 260 |
+
hidden_states = self.fc1(hidden_states)
|
| 261 |
+
hidden_states = self.act(hidden_states)
|
| 262 |
+
hidden_states = self.fc2(hidden_states)
|
| 263 |
+
return hidden_states
|
| 264 |
+
|
| 265 |
+
|
| 266 |
+
class InternVisionEncoderLayer(nn.Module):
|
| 267 |
+
def __init__(self, config: InternVisionConfig, drop_path_rate: float):
|
| 268 |
+
super().__init__()
|
| 269 |
+
self.embed_dim = config.hidden_size
|
| 270 |
+
self.intermediate_size = config.intermediate_size
|
| 271 |
+
self.norm_type = config.norm_type
|
| 272 |
+
|
| 273 |
+
self.attn = InternAttention(config)
|
| 274 |
+
self.mlp = InternMLP(config)
|
| 275 |
+
self.norm1 = NORM2FN[self.norm_type](self.embed_dim, eps=config.layer_norm_eps)
|
| 276 |
+
self.norm2 = NORM2FN[self.norm_type](self.embed_dim, eps=config.layer_norm_eps)
|
| 277 |
+
|
| 278 |
+
self.ls1 = nn.Parameter(config.initializer_factor * torch.ones(self.embed_dim))
|
| 279 |
+
self.ls2 = nn.Parameter(config.initializer_factor * torch.ones(self.embed_dim))
|
| 280 |
+
self.drop_path1 = DropPath(drop_path_rate) if drop_path_rate > 0. else nn.Identity()
|
| 281 |
+
self.drop_path2 = DropPath(drop_path_rate) if drop_path_rate > 0. else nn.Identity()
|
| 282 |
+
|
| 283 |
+
def forward(
|
| 284 |
+
self,
|
| 285 |
+
hidden_states: torch.Tensor,
|
| 286 |
+
) -> Tuple[torch.FloatTensor, Optional[torch.FloatTensor], Optional[Tuple[torch.FloatTensor]]]:
|
| 287 |
+
"""
|
| 288 |
+
Args:
|
| 289 |
+
hidden_states (`Tuple[torch.FloatTensor, Optional[torch.FloatTensor]]`): input to the layer of shape `(batch, seq_len, embed_dim)`
|
| 290 |
+
"""
|
| 291 |
+
hidden_states = hidden_states + self.drop_path1(self.attn(self.norm1(hidden_states).to(hidden_states.dtype)) * self.ls1)
|
| 292 |
+
|
| 293 |
+
hidden_states = hidden_states + self.drop_path2(self.mlp(self.norm2(hidden_states).to(hidden_states.dtype)) * self.ls2)
|
| 294 |
+
|
| 295 |
+
return hidden_states
|
| 296 |
+
|
| 297 |
+
|
| 298 |
+
class InternVisionEncoder(nn.Module):
|
| 299 |
+
"""
|
| 300 |
+
Transformer encoder consisting of `config.num_hidden_layers` self attention layers. Each layer is a
|
| 301 |
+
[`InternEncoderLayer`].
|
| 302 |
+
|
| 303 |
+
Args:
|
| 304 |
+
config (`InternConfig`):
|
| 305 |
+
The corresponding vision configuration for the `InternEncoder`.
|
| 306 |
+
"""
|
| 307 |
+
|
| 308 |
+
def __init__(self, config: InternVisionConfig):
|
| 309 |
+
super().__init__()
|
| 310 |
+
self.config = config
|
| 311 |
+
# stochastic depth decay rule
|
| 312 |
+
dpr = [x.item() for x in torch.linspace(0, config.drop_path_rate, config.num_hidden_layers)]
|
| 313 |
+
self.layers = nn.ModuleList([
|
| 314 |
+
InternVisionEncoderLayer(config, dpr[idx]) for idx in range(config.num_hidden_layers)])
|
| 315 |
+
self.gradient_checkpointing = True
|
| 316 |
+
|
| 317 |
+
def forward(
|
| 318 |
+
self,
|
| 319 |
+
inputs_embeds,
|
| 320 |
+
output_hidden_states: Optional[bool] = None,
|
| 321 |
+
return_dict: Optional[bool] = None,
|
| 322 |
+
) -> Union[Tuple, BaseModelOutput]:
|
| 323 |
+
r"""
|
| 324 |
+
Args:
|
| 325 |
+
inputs_embeds (`torch.FloatTensor` of shape `(batch_size, sequence_length, hidden_size)`):
|
| 326 |
+
Embedded representation of the inputs. Should be float, not int tokens.
|
| 327 |
+
output_hidden_states (`bool`, *optional*):
|
| 328 |
+
Whether or not to return the hidden states of all layers. See `hidden_states` under returned tensors
|
| 329 |
+
for more detail.
|
| 330 |
+
return_dict (`bool`, *optional*):
|
| 331 |
+
Whether or not to return a [`~utils.ModelOutput`] instead of a plain tuple.
|
| 332 |
+
"""
|
| 333 |
+
output_hidden_states = (
|
| 334 |
+
output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
|
| 335 |
+
)
|
| 336 |
+
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
|
| 337 |
+
|
| 338 |
+
encoder_states = () if output_hidden_states else None
|
| 339 |
+
hidden_states = inputs_embeds
|
| 340 |
+
|
| 341 |
+
for idx, encoder_layer in enumerate(self.layers):
|
| 342 |
+
if output_hidden_states:
|
| 343 |
+
encoder_states = encoder_states + (hidden_states,)
|
| 344 |
+
if self.gradient_checkpointing and self.training:
|
| 345 |
+
layer_outputs = torch.utils.checkpoint.checkpoint(
|
| 346 |
+
encoder_layer,
|
| 347 |
+
hidden_states)
|
| 348 |
+
else:
|
| 349 |
+
layer_outputs = encoder_layer(
|
| 350 |
+
hidden_states,
|
| 351 |
+
)
|
| 352 |
+
hidden_states = layer_outputs
|
| 353 |
+
|
| 354 |
+
if output_hidden_states:
|
| 355 |
+
encoder_states = encoder_states + (hidden_states,)
|
| 356 |
+
|
| 357 |
+
if not return_dict:
|
| 358 |
+
return tuple(v for v in [hidden_states, encoder_states] if v is not None)
|
| 359 |
+
return BaseModelOutput(
|
| 360 |
+
last_hidden_state=hidden_states, hidden_states=encoder_states
|
| 361 |
+
)
|
| 362 |
+
|
| 363 |
+
|
| 364 |
+
class InternVisionModel(PreTrainedModel):
|
| 365 |
+
main_input_name = 'pixel_values'
|
| 366 |
+
_supports_flash_attn_2 = True
|
| 367 |
+
supports_gradient_checkpointing = True
|
| 368 |
+
config_class = InternVisionConfig
|
| 369 |
+
_no_split_modules = ['InternVisionEncoderLayer']
|
| 370 |
+
|
| 371 |
+
def __init__(self, config: InternVisionConfig):
|
| 372 |
+
super().__init__(config)
|
| 373 |
+
self.config = config
|
| 374 |
+
|
| 375 |
+
self.embeddings = InternVisionEmbeddings(config)
|
| 376 |
+
self.encoder = InternVisionEncoder(config)
|
| 377 |
+
|
| 378 |
+
def resize_pos_embeddings(self, old_size, new_size, patch_size):
|
| 379 |
+
pos_emb = self.embeddings.position_embedding
|
| 380 |
+
_, num_positions, embed_dim = pos_emb.shape
|
| 381 |
+
cls_emb = pos_emb[:, :1, :]
|
| 382 |
+
pos_emb = pos_emb[:, 1:, :].reshape(1, old_size // patch_size, old_size // patch_size, -1).permute(0, 3, 1, 2)
|
| 383 |
+
pos_emb = F.interpolate(pos_emb.float(), size=new_size // patch_size, mode='bicubic', align_corners=False)
|
| 384 |
+
pos_emb = pos_emb.to(cls_emb.dtype).reshape(1, embed_dim, -1).permute(0, 2, 1)
|
| 385 |
+
pos_emb = torch.cat([cls_emb, pos_emb], dim=1)
|
| 386 |
+
self.embeddings.position_embedding = nn.Parameter(pos_emb)
|
| 387 |
+
self.embeddings.image_size = new_size
|
| 388 |
+
logger.info('Resized position embeddings from {} to {}'.format(old_size, new_size))
|
| 389 |
+
|
| 390 |
+
def get_input_embeddings(self):
|
| 391 |
+
return self.embeddings
|
| 392 |
+
|
| 393 |
+
def forward(
|
| 394 |
+
self,
|
| 395 |
+
pixel_values: Optional[torch.FloatTensor] = None,
|
| 396 |
+
output_hidden_states: Optional[bool] = None,
|
| 397 |
+
return_dict: Optional[bool] = None,
|
| 398 |
+
pixel_embeds: Optional[torch.FloatTensor] = None,
|
| 399 |
+
) -> Union[Tuple, BaseModelOutputWithPooling]:
|
| 400 |
+
output_hidden_states = (
|
| 401 |
+
output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
|
| 402 |
+
)
|
| 403 |
+
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
|
| 404 |
+
|
| 405 |
+
if pixel_values is None and pixel_embeds is None:
|
| 406 |
+
raise ValueError('You have to specify pixel_values or pixel_embeds')
|
| 407 |
+
|
| 408 |
+
if pixel_embeds is not None:
|
| 409 |
+
hidden_states = pixel_embeds
|
| 410 |
+
else:
|
| 411 |
+
if len(pixel_values.shape) == 4:
|
| 412 |
+
hidden_states = self.embeddings(pixel_values)
|
| 413 |
+
else:
|
| 414 |
+
raise ValueError(f'wrong pixel_values size: {pixel_values.shape}')
|
| 415 |
+
encoder_outputs = self.encoder(
|
| 416 |
+
inputs_embeds=hidden_states,
|
| 417 |
+
output_hidden_states=output_hidden_states,
|
| 418 |
+
return_dict=return_dict,
|
| 419 |
+
)
|
| 420 |
+
last_hidden_state = encoder_outputs.last_hidden_state
|
| 421 |
+
pooled_output = last_hidden_state[:, 0, :]
|
| 422 |
+
|
| 423 |
+
if not return_dict:
|
| 424 |
+
return (last_hidden_state, pooled_output) + encoder_outputs[1:]
|
| 425 |
+
|
| 426 |
+
return BaseModelOutputWithPooling(
|
| 427 |
+
last_hidden_state=last_hidden_state,
|
| 428 |
+
pooler_output=pooled_output,
|
| 429 |
+
hidden_states=encoder_outputs.hidden_states,
|
| 430 |
+
attentions=encoder_outputs.attentions,
|
| 431 |
+
)
|
modeling_internvl_chat.py
ADDED
|
@@ -0,0 +1,564 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# --------------------------------------------------------
|
| 2 |
+
# InternVL
|
| 3 |
+
# Copyright (c) 2024 OpenGVLab
|
| 4 |
+
# Licensed under The MIT License [see LICENSE for details]
|
| 5 |
+
# --------------------------------------------------------
|
| 6 |
+
|
| 7 |
+
import math
|
| 8 |
+
import warnings
|
| 9 |
+
from typing import List, Optional, Tuple, Union
|
| 10 |
+
|
| 11 |
+
import torch.utils.checkpoint
|
| 12 |
+
import transformers
|
| 13 |
+
from torch import nn
|
| 14 |
+
from torch.nn import CrossEntropyLoss
|
| 15 |
+
from transformers import (AutoModel, GenerationConfig, LlamaForCausalLM,
|
| 16 |
+
Qwen2ForCausalLM)
|
| 17 |
+
from transformers.modeling_outputs import CausalLMOutputWithPast
|
| 18 |
+
from transformers.modeling_utils import PreTrainedModel
|
| 19 |
+
from transformers.utils import ModelOutput, logging
|
| 20 |
+
|
| 21 |
+
from .configuration_internvl_chat import InternVLChatConfig
|
| 22 |
+
from .conversation import get_conv_template
|
| 23 |
+
from .modeling_intern_vit import InternVisionModel, has_flash_attn
|
| 24 |
+
|
| 25 |
+
logger = logging.get_logger(__name__)
|
| 26 |
+
|
| 27 |
+
|
| 28 |
+
def version_cmp(v1, v2, op='eq'):
|
| 29 |
+
import operator
|
| 30 |
+
|
| 31 |
+
from packaging import version
|
| 32 |
+
op_func = getattr(operator, op)
|
| 33 |
+
return op_func(version.parse(v1), version.parse(v2))
|
| 34 |
+
|
| 35 |
+
|
| 36 |
+
class InternVLChatModel(PreTrainedModel):
|
| 37 |
+
config_class = InternVLChatConfig
|
| 38 |
+
main_input_name = 'pixel_values'
|
| 39 |
+
base_model_prefix = 'language_model'
|
| 40 |
+
_supports_flash_attn_2 = True
|
| 41 |
+
supports_gradient_checkpointing = True
|
| 42 |
+
_no_split_modules = ['InternVisionModel', 'LlamaDecoderLayer', 'Qwen2DecoderLayer']
|
| 43 |
+
|
| 44 |
+
def __init__(self, config: InternVLChatConfig, vision_model=None, language_model=None, use_flash_attn=True):
|
| 45 |
+
super().__init__(config)
|
| 46 |
+
|
| 47 |
+
assert version_cmp(transformers.__version__, '4.37.0', 'ge')
|
| 48 |
+
image_size = config.force_image_size or config.vision_config.image_size
|
| 49 |
+
patch_size = config.vision_config.patch_size
|
| 50 |
+
self.patch_size = patch_size
|
| 51 |
+
self.select_layer = config.select_layer
|
| 52 |
+
self.template = config.template
|
| 53 |
+
self.num_image_token = int((image_size // patch_size) ** 2 * (config.downsample_ratio ** 2))
|
| 54 |
+
self.downsample_ratio = config.downsample_ratio
|
| 55 |
+
self.ps_version = config.ps_version
|
| 56 |
+
use_flash_attn = use_flash_attn if has_flash_attn else False
|
| 57 |
+
config.vision_config.use_flash_attn = True if use_flash_attn else False
|
| 58 |
+
config.llm_config._attn_implementation = 'flash_attention_2' if use_flash_attn else 'eager'
|
| 59 |
+
|
| 60 |
+
logger.info(f'num_image_token: {self.num_image_token}')
|
| 61 |
+
logger.info(f'ps_version: {self.ps_version}')
|
| 62 |
+
if vision_model is not None:
|
| 63 |
+
self.vision_model = vision_model
|
| 64 |
+
else:
|
| 65 |
+
self.vision_model = InternVisionModel(config.vision_config)
|
| 66 |
+
if language_model is not None:
|
| 67 |
+
self.language_model = language_model
|
| 68 |
+
else:
|
| 69 |
+
if config.llm_config.architectures[0] == 'LlamaForCausalLM':
|
| 70 |
+
self.language_model = LlamaForCausalLM(config.llm_config)
|
| 71 |
+
elif config.llm_config.architectures[0] == 'Qwen2ForCausalLM':
|
| 72 |
+
self.language_model = Qwen2ForCausalLM(config.llm_config)
|
| 73 |
+
else:
|
| 74 |
+
raise NotImplementedError(f'{config.llm_config.architectures[0]} is not implemented.')
|
| 75 |
+
|
| 76 |
+
vit_hidden_size = config.vision_config.hidden_size
|
| 77 |
+
llm_hidden_size = config.llm_config.hidden_size
|
| 78 |
+
|
| 79 |
+
self.mlp1 = nn.Sequential(
|
| 80 |
+
nn.LayerNorm(vit_hidden_size * int(1 / self.downsample_ratio) ** 2),
|
| 81 |
+
nn.Linear(vit_hidden_size * int(1 / self.downsample_ratio) ** 2, llm_hidden_size),
|
| 82 |
+
nn.GELU(),
|
| 83 |
+
nn.Linear(llm_hidden_size, llm_hidden_size)
|
| 84 |
+
)
|
| 85 |
+
|
| 86 |
+
self.img_context_token_id = None
|
| 87 |
+
self.conv_template = get_conv_template(self.template)
|
| 88 |
+
self.system_message = self.conv_template.system_message
|
| 89 |
+
|
| 90 |
+
def forward(
|
| 91 |
+
self,
|
| 92 |
+
pixel_values: torch.FloatTensor,
|
| 93 |
+
input_ids: torch.LongTensor = None,
|
| 94 |
+
attention_mask: Optional[torch.Tensor] = None,
|
| 95 |
+
position_ids: Optional[torch.LongTensor] = None,
|
| 96 |
+
image_flags: Optional[torch.LongTensor] = None,
|
| 97 |
+
past_key_values: Optional[List[torch.FloatTensor]] = None,
|
| 98 |
+
labels: Optional[torch.LongTensor] = None,
|
| 99 |
+
use_cache: Optional[bool] = None,
|
| 100 |
+
output_attentions: Optional[bool] = None,
|
| 101 |
+
output_hidden_states: Optional[bool] = None,
|
| 102 |
+
return_dict: Optional[bool] = None,
|
| 103 |
+
) -> Union[Tuple, CausalLMOutputWithPast]:
|
| 104 |
+
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
|
| 105 |
+
|
| 106 |
+
image_flags = image_flags.squeeze(-1)
|
| 107 |
+
input_embeds = self.language_model.get_input_embeddings()(input_ids).clone()
|
| 108 |
+
|
| 109 |
+
vit_embeds = self.extract_feature(pixel_values)
|
| 110 |
+
vit_embeds = vit_embeds[image_flags == 1]
|
| 111 |
+
vit_batch_size = pixel_values.shape[0]
|
| 112 |
+
|
| 113 |
+
B, N, C = input_embeds.shape
|
| 114 |
+
input_embeds = input_embeds.reshape(B * N, C)
|
| 115 |
+
|
| 116 |
+
if torch.distributed.is_initialized() and torch.distributed.get_rank() == 0:
|
| 117 |
+
print(f'dynamic ViT batch size: {vit_batch_size}, images per sample: {vit_batch_size / B}, dynamic token length: {N}')
|
| 118 |
+
|
| 119 |
+
input_ids = input_ids.reshape(B * N)
|
| 120 |
+
selected = (input_ids == self.img_context_token_id)
|
| 121 |
+
try:
|
| 122 |
+
input_embeds[selected] = input_embeds[selected] * 0.0 + vit_embeds.reshape(-1, C)
|
| 123 |
+
except Exception as e:
|
| 124 |
+
vit_embeds = vit_embeds.reshape(-1, C)
|
| 125 |
+
print(f'warning: {e}, input_embeds[selected].shape={input_embeds[selected].shape}, '
|
| 126 |
+
f'vit_embeds.shape={vit_embeds.shape}')
|
| 127 |
+
n_token = selected.sum()
|
| 128 |
+
input_embeds[selected] = input_embeds[selected] * 0.0 + vit_embeds[:n_token]
|
| 129 |
+
|
| 130 |
+
input_embeds = input_embeds.reshape(B, N, C)
|
| 131 |
+
|
| 132 |
+
outputs = self.language_model(
|
| 133 |
+
inputs_embeds=input_embeds,
|
| 134 |
+
attention_mask=attention_mask,
|
| 135 |
+
position_ids=position_ids,
|
| 136 |
+
past_key_values=past_key_values,
|
| 137 |
+
use_cache=use_cache,
|
| 138 |
+
output_attentions=output_attentions,
|
| 139 |
+
output_hidden_states=output_hidden_states,
|
| 140 |
+
return_dict=return_dict,
|
| 141 |
+
)
|
| 142 |
+
logits = outputs.logits
|
| 143 |
+
|
| 144 |
+
loss = None
|
| 145 |
+
if labels is not None:
|
| 146 |
+
# Shift so that tokens < n predict n
|
| 147 |
+
shift_logits = logits[..., :-1, :].contiguous()
|
| 148 |
+
shift_labels = labels[..., 1:].contiguous()
|
| 149 |
+
# Flatten the tokens
|
| 150 |
+
loss_fct = CrossEntropyLoss()
|
| 151 |
+
shift_logits = shift_logits.view(-1, self.language_model.config.vocab_size)
|
| 152 |
+
shift_labels = shift_labels.view(-1)
|
| 153 |
+
# Enable model parallelism
|
| 154 |
+
shift_labels = shift_labels.to(shift_logits.device)
|
| 155 |
+
loss = loss_fct(shift_logits, shift_labels)
|
| 156 |
+
|
| 157 |
+
if not return_dict:
|
| 158 |
+
output = (logits,) + outputs[1:]
|
| 159 |
+
return (loss,) + output if loss is not None else output
|
| 160 |
+
|
| 161 |
+
return CausalLMOutputWithPast(
|
| 162 |
+
loss=loss,
|
| 163 |
+
logits=logits,
|
| 164 |
+
past_key_values=outputs.past_key_values,
|
| 165 |
+
hidden_states=outputs.hidden_states,
|
| 166 |
+
attentions=outputs.attentions,
|
| 167 |
+
)
|
| 168 |
+
|
| 169 |
+
def pixel_shuffle(self, x, scale_factor=0.5):
|
| 170 |
+
n, w, h, c = x.size()
|
| 171 |
+
# N, W, H, C --> N, W, H * scale, C // scale
|
| 172 |
+
x = x.view(n, w, int(h * scale_factor), int(c / scale_factor))
|
| 173 |
+
# N, W, H * scale, C // scale --> N, H * scale, W, C // scale
|
| 174 |
+
x = x.permute(0, 2, 1, 3).contiguous()
|
| 175 |
+
# N, H * scale, W, C // scale --> N, H * scale, W * scale, C // (scale ** 2)
|
| 176 |
+
x = x.view(n, int(h * scale_factor), int(w * scale_factor),
|
| 177 |
+
int(c / (scale_factor * scale_factor)))
|
| 178 |
+
if self.ps_version == 'v1':
|
| 179 |
+
warnings.warn("In ps_version 'v1', the height and width have not been swapped back, "
|
| 180 |
+
'which results in a transposed image.')
|
| 181 |
+
else:
|
| 182 |
+
x = x.permute(0, 2, 1, 3).contiguous()
|
| 183 |
+
return x
|
| 184 |
+
|
| 185 |
+
def extract_feature(self, pixel_values):
|
| 186 |
+
if self.select_layer == -1:
|
| 187 |
+
vit_embeds = self.vision_model(
|
| 188 |
+
pixel_values=pixel_values,
|
| 189 |
+
output_hidden_states=False,
|
| 190 |
+
return_dict=True).last_hidden_state
|
| 191 |
+
else:
|
| 192 |
+
vit_embeds = self.vision_model(
|
| 193 |
+
pixel_values=pixel_values,
|
| 194 |
+
output_hidden_states=True,
|
| 195 |
+
return_dict=True).hidden_states[self.select_layer]
|
| 196 |
+
vit_embeds = vit_embeds[:, 1:, :]
|
| 197 |
+
|
| 198 |
+
h = w = int(vit_embeds.shape[1] ** 0.5)
|
| 199 |
+
vit_embeds = vit_embeds.reshape(vit_embeds.shape[0], h, w, -1)
|
| 200 |
+
vit_embeds = self.pixel_shuffle(vit_embeds, scale_factor=self.downsample_ratio)
|
| 201 |
+
vit_embeds = vit_embeds.reshape(vit_embeds.shape[0], -1, vit_embeds.shape[-1])
|
| 202 |
+
vit_embeds = self.mlp1(vit_embeds)
|
| 203 |
+
return vit_embeds
|
| 204 |
+
|
| 205 |
+
def batch_chat(self, tokenizer, pixel_values, questions, generation_config, num_patches_list=None,
|
| 206 |
+
history=None, return_history=False, IMG_START_TOKEN='<img>', IMG_END_TOKEN='</img>',
|
| 207 |
+
IMG_CONTEXT_TOKEN='<IMG_CONTEXT>', verbose=False, image_counts=None):
|
| 208 |
+
if history is not None or return_history:
|
| 209 |
+
print('Now multi-turn chat is not supported in batch_chat.')
|
| 210 |
+
raise NotImplementedError
|
| 211 |
+
|
| 212 |
+
if image_counts is not None:
|
| 213 |
+
num_patches_list = image_counts
|
| 214 |
+
print('Warning: `image_counts` is deprecated. Please use `num_patches_list` instead.')
|
| 215 |
+
|
| 216 |
+
img_context_token_id = tokenizer.convert_tokens_to_ids(IMG_CONTEXT_TOKEN)
|
| 217 |
+
self.img_context_token_id = img_context_token_id
|
| 218 |
+
|
| 219 |
+
if verbose and pixel_values is not None:
|
| 220 |
+
image_bs = pixel_values.shape[0]
|
| 221 |
+
print(f'dynamic ViT batch size: {image_bs}')
|
| 222 |
+
|
| 223 |
+
queries = []
|
| 224 |
+
for idx, num_patches in enumerate(num_patches_list):
|
| 225 |
+
question = questions[idx]
|
| 226 |
+
if pixel_values is not None and '<image>' not in question:
|
| 227 |
+
question = '<image>\n' + question
|
| 228 |
+
template = get_conv_template(self.template)
|
| 229 |
+
template.system_message = self.system_message
|
| 230 |
+
template.append_message(template.roles[0], question)
|
| 231 |
+
template.append_message(template.roles[1], None)
|
| 232 |
+
query = template.get_prompt()
|
| 233 |
+
|
| 234 |
+
image_tokens = IMG_START_TOKEN + IMG_CONTEXT_TOKEN * self.num_image_token * num_patches + IMG_END_TOKEN
|
| 235 |
+
query = query.replace('<image>', image_tokens, 1)
|
| 236 |
+
queries.append(query)
|
| 237 |
+
|
| 238 |
+
tokenizer.padding_side = 'left'
|
| 239 |
+
model_inputs = tokenizer(queries, return_tensors='pt', padding=True)
|
| 240 |
+
input_ids = model_inputs['input_ids'].to(self.device)
|
| 241 |
+
attention_mask = model_inputs['attention_mask'].to(self.device)
|
| 242 |
+
eos_token_id = tokenizer.convert_tokens_to_ids(template.sep.strip())
|
| 243 |
+
generation_config['eos_token_id'] = eos_token_id
|
| 244 |
+
generation_output = self.generate(
|
| 245 |
+
pixel_values=pixel_values,
|
| 246 |
+
input_ids=input_ids,
|
| 247 |
+
attention_mask=attention_mask,
|
| 248 |
+
**generation_config
|
| 249 |
+
)
|
| 250 |
+
responses = tokenizer.batch_decode(generation_output, skip_special_tokens=True)
|
| 251 |
+
responses = [response.split(template.sep.strip())[0].strip() for response in responses]
|
| 252 |
+
return responses
|
| 253 |
+
|
| 254 |
+
def chat(self, tokenizer, pixel_values, question, generation_config, history=None, return_history=False,
|
| 255 |
+
num_patches_list=None, IMG_START_TOKEN='<img>', IMG_END_TOKEN='</img>', IMG_CONTEXT_TOKEN='<IMG_CONTEXT>',
|
| 256 |
+
verbose=False):
|
| 257 |
+
|
| 258 |
+
if history is None and pixel_values is not None and '<image>' not in question:
|
| 259 |
+
question = '<image>\n' + question
|
| 260 |
+
|
| 261 |
+
if num_patches_list is None:
|
| 262 |
+
num_patches_list = [pixel_values.shape[0]] if pixel_values is not None else []
|
| 263 |
+
assert pixel_values is None or len(pixel_values) == sum(num_patches_list)
|
| 264 |
+
|
| 265 |
+
img_context_token_id = tokenizer.convert_tokens_to_ids(IMG_CONTEXT_TOKEN)
|
| 266 |
+
self.img_context_token_id = img_context_token_id
|
| 267 |
+
|
| 268 |
+
template = get_conv_template(self.template)
|
| 269 |
+
template.system_message = self.system_message
|
| 270 |
+
eos_token_id = tokenizer.convert_tokens_to_ids(template.sep.strip())
|
| 271 |
+
|
| 272 |
+
history = [] if history is None else history
|
| 273 |
+
for (old_question, old_answer) in history:
|
| 274 |
+
template.append_message(template.roles[0], old_question)
|
| 275 |
+
template.append_message(template.roles[1], old_answer)
|
| 276 |
+
template.append_message(template.roles[0], question)
|
| 277 |
+
template.append_message(template.roles[1], None)
|
| 278 |
+
query = template.get_prompt()
|
| 279 |
+
|
| 280 |
+
if verbose and pixel_values is not None:
|
| 281 |
+
image_bs = pixel_values.shape[0]
|
| 282 |
+
print(f'dynamic ViT batch size: {image_bs}')
|
| 283 |
+
|
| 284 |
+
for num_patches in num_patches_list:
|
| 285 |
+
image_tokens = IMG_START_TOKEN + IMG_CONTEXT_TOKEN * self.num_image_token * num_patches + IMG_END_TOKEN
|
| 286 |
+
query = query.replace('<image>', image_tokens, 1)
|
| 287 |
+
|
| 288 |
+
model_inputs = tokenizer(query, return_tensors='pt')
|
| 289 |
+
input_ids = model_inputs['input_ids'].to(self.device)
|
| 290 |
+
attention_mask = model_inputs['attention_mask'].to(self.device)
|
| 291 |
+
generation_config['eos_token_id'] = eos_token_id
|
| 292 |
+
generation_output = self.generate(
|
| 293 |
+
pixel_values=pixel_values,
|
| 294 |
+
input_ids=input_ids,
|
| 295 |
+
attention_mask=attention_mask,
|
| 296 |
+
**generation_config
|
| 297 |
+
)
|
| 298 |
+
response = tokenizer.batch_decode(generation_output, skip_special_tokens=True)[0]
|
| 299 |
+
response = response.split(template.sep.strip())[0].strip()
|
| 300 |
+
history.append((question, response))
|
| 301 |
+
if return_history:
|
| 302 |
+
return response, history
|
| 303 |
+
else:
|
| 304 |
+
query_to_print = query.replace(IMG_CONTEXT_TOKEN, '')
|
| 305 |
+
query_to_print = query_to_print.replace(f'{IMG_START_TOKEN}{IMG_END_TOKEN}', '<image>')
|
| 306 |
+
if verbose:
|
| 307 |
+
print(query_to_print, response)
|
| 308 |
+
return response
|
| 309 |
+
|
| 310 |
+
@torch.no_grad()
|
| 311 |
+
def generate(
|
| 312 |
+
self,
|
| 313 |
+
pixel_values: Optional[torch.FloatTensor] = None,
|
| 314 |
+
input_ids: Optional[torch.FloatTensor] = None,
|
| 315 |
+
attention_mask: Optional[torch.LongTensor] = None,
|
| 316 |
+
visual_features: Optional[torch.FloatTensor] = None,
|
| 317 |
+
generation_config: Optional[GenerationConfig] = None,
|
| 318 |
+
output_hidden_states: Optional[bool] = None,
|
| 319 |
+
**generate_kwargs,
|
| 320 |
+
) -> torch.LongTensor:
|
| 321 |
+
|
| 322 |
+
assert self.img_context_token_id is not None
|
| 323 |
+
if pixel_values is not None:
|
| 324 |
+
if visual_features is not None:
|
| 325 |
+
vit_embeds = visual_features
|
| 326 |
+
else:
|
| 327 |
+
vit_embeds = self.extract_feature(pixel_values)
|
| 328 |
+
input_embeds = self.language_model.get_input_embeddings()(input_ids)
|
| 329 |
+
B, N, C = input_embeds.shape
|
| 330 |
+
input_embeds = input_embeds.reshape(B * N, C)
|
| 331 |
+
|
| 332 |
+
input_ids = input_ids.reshape(B * N)
|
| 333 |
+
selected = (input_ids == self.img_context_token_id)
|
| 334 |
+
assert selected.sum() != 0
|
| 335 |
+
input_embeds[selected] = vit_embeds.reshape(-1, C).to(input_embeds.device)
|
| 336 |
+
|
| 337 |
+
input_embeds = input_embeds.reshape(B, N, C)
|
| 338 |
+
else:
|
| 339 |
+
input_embeds = self.language_model.get_input_embeddings()(input_ids)
|
| 340 |
+
|
| 341 |
+
outputs = self.language_model.generate(
|
| 342 |
+
inputs_embeds=input_embeds,
|
| 343 |
+
attention_mask=attention_mask,
|
| 344 |
+
generation_config=generation_config,
|
| 345 |
+
output_hidden_states=output_hidden_states,
|
| 346 |
+
use_cache=True,
|
| 347 |
+
**generate_kwargs,
|
| 348 |
+
)
|
| 349 |
+
|
| 350 |
+
return outputs
|
| 351 |
+
|
| 352 |
+
@property
|
| 353 |
+
def lm_head(self):
|
| 354 |
+
return self.language_model.get_output_embeddings()
|
| 355 |
+
|
| 356 |
+
def get_input_embeddings(self):
|
| 357 |
+
return self.language_model.get_input_embeddings()
|
| 358 |
+
|
| 359 |
+
def get_output_embeddings(self):
|
| 360 |
+
return self.language_model.get_output_embeddings()
|
| 361 |
+
|
| 362 |
+
|
| 363 |
+
class InternVLRewardModel(InternVLChatModel):
|
| 364 |
+
@staticmethod
|
| 365 |
+
def split_response(response, sep='\n\n', max_steps=None):
|
| 366 |
+
steps = response.split(sep)
|
| 367 |
+
|
| 368 |
+
if max_steps is not None:
|
| 369 |
+
step = math.ceil(len(steps) / max_steps)
|
| 370 |
+
new_steps = []
|
| 371 |
+
for i in range(0, len(steps), step):
|
| 372 |
+
new_steps.append(sep.join(steps[i:i+step]))
|
| 373 |
+
return new_steps
|
| 374 |
+
|
| 375 |
+
return steps
|
| 376 |
+
|
| 377 |
+
@staticmethod
|
| 378 |
+
def join_steps(steps, sep='\n\n'):
|
| 379 |
+
return sep.join(steps)
|
| 380 |
+
|
| 381 |
+
def find_placeholder_idx(self, tokenizer, input_ids, PLACEHOLDER):
|
| 382 |
+
# TODO: support batch inference
|
| 383 |
+
input_ids = input_ids[0].tolist()
|
| 384 |
+
template = get_conv_template(self.template)
|
| 385 |
+
|
| 386 |
+
idx = []
|
| 387 |
+
bos = tokenizer(template.roles[1], add_special_tokens=False).input_ids
|
| 388 |
+
target = tokenizer(template.roles[1] + PLACEHOLDER + template.sep, add_special_tokens=False).input_ids
|
| 389 |
+
for i in range(len(input_ids)):
|
| 390 |
+
if input_ids[i:i+len(target)] == target:
|
| 391 |
+
assert i + len(bos) - 1 >= 0
|
| 392 |
+
idx.append(i + len(bos) - 1)
|
| 393 |
+
|
| 394 |
+
return idx
|
| 395 |
+
|
| 396 |
+
def generate_steps_with_soft_score(
|
| 397 |
+
self,
|
| 398 |
+
tokenizer,
|
| 399 |
+
question,
|
| 400 |
+
response,
|
| 401 |
+
pixel_values,
|
| 402 |
+
num_patches_list=None,
|
| 403 |
+
max_steps=None,
|
| 404 |
+
IMG_START_TOKEN='<img>',
|
| 405 |
+
IMG_END_TOKEN='</img>',
|
| 406 |
+
IMG_CONTEXT_TOKEN='<IMG_CONTEXT>',
|
| 407 |
+
PLACEHOLDER=None,
|
| 408 |
+
str2score=None,
|
| 409 |
+
):
|
| 410 |
+
if str2score is None:
|
| 411 |
+
str2score = {'+': 1, '-': 0}
|
| 412 |
+
|
| 413 |
+
if PLACEHOLDER is None:
|
| 414 |
+
PLACEHOLDER = '+'
|
| 415 |
+
|
| 416 |
+
if pixel_values is not None and '<image>' not in question:
|
| 417 |
+
num_images = 1 if num_patches_list is None else len(num_patches_list)
|
| 418 |
+
question = '<image>\n' * num_images + question
|
| 419 |
+
|
| 420 |
+
if num_patches_list is None:
|
| 421 |
+
num_patches_list = [pixel_values.shape[0]] if pixel_values is not None else []
|
| 422 |
+
|
| 423 |
+
assert pixel_values is None or (len(pixel_values) == sum(num_patches_list) and len(num_patches_list) == question.count('<image>')), f'{len(pixel_values)=}, {sum(num_patches_list)=}, {len(num_patches_list)}, {question=}'
|
| 424 |
+
|
| 425 |
+
image_input = pixel_values is not None
|
| 426 |
+
if pixel_values is None:
|
| 427 |
+
pixel_values = torch.zeros(1, 3, self.config.vision_config.image_size, self.config.vision_config.image_size).to(self.device).to(torch.bfloat16)
|
| 428 |
+
|
| 429 |
+
img_context_token_id = tokenizer.convert_tokens_to_ids(IMG_CONTEXT_TOKEN)
|
| 430 |
+
self.img_context_token_id = img_context_token_id
|
| 431 |
+
|
| 432 |
+
candidate_tokens = []
|
| 433 |
+
candidate_weights = []
|
| 434 |
+
|
| 435 |
+
if isinstance(response, str):
|
| 436 |
+
steps = self.split_response(response, max_steps=max_steps)
|
| 437 |
+
else:
|
| 438 |
+
steps = response
|
| 439 |
+
|
| 440 |
+
# Prepare Query
|
| 441 |
+
for k, v in str2score.items():
|
| 442 |
+
k_id = tokenizer.convert_tokens_to_ids(k)
|
| 443 |
+
assert k_id != tokenizer.unk_token_id
|
| 444 |
+
|
| 445 |
+
candidate_tokens.append(k_id)
|
| 446 |
+
candidate_weights.append(v)
|
| 447 |
+
|
| 448 |
+
template = get_conv_template(self.template)
|
| 449 |
+
template.system_message = self.system_message
|
| 450 |
+
|
| 451 |
+
for step_idx, step in enumerate(steps):
|
| 452 |
+
if step_idx == 0:
|
| 453 |
+
step = f'### Question:\n{question}\n\n### Solution Process:\n{step}'
|
| 454 |
+
template.append_message(template.roles[0], step)
|
| 455 |
+
template.append_message(template.roles[1], PLACEHOLDER)
|
| 456 |
+
query = template.get_prompt()
|
| 457 |
+
|
| 458 |
+
for num_patches in num_patches_list:
|
| 459 |
+
image_tokens = IMG_START_TOKEN + IMG_CONTEXT_TOKEN * self.num_image_token * num_patches + IMG_END_TOKEN
|
| 460 |
+
query = query.replace('<image>', image_tokens, 1)
|
| 461 |
+
|
| 462 |
+
# Prepare inputs
|
| 463 |
+
model_inputs = tokenizer(query, return_tensors='pt')
|
| 464 |
+
# device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
|
| 465 |
+
device = self.device
|
| 466 |
+
input_ids = model_inputs['input_ids'].to(device)
|
| 467 |
+
attention_mask = model_inputs['attention_mask'].to(device)
|
| 468 |
+
image_flags = torch.tensor([image_input] * pixel_values.size(0), dtype=torch.long).to(device)
|
| 469 |
+
|
| 470 |
+
# Forward
|
| 471 |
+
idx = self.find_placeholder_idx(tokenizer, input_ids, PLACEHOLDER=PLACEHOLDER)
|
| 472 |
+
logits = self(
|
| 473 |
+
pixel_values=pixel_values,
|
| 474 |
+
input_ids=input_ids,
|
| 475 |
+
attention_mask=attention_mask,
|
| 476 |
+
image_flags=image_flags,
|
| 477 |
+
).logits
|
| 478 |
+
logits = logits[0][idx, :][:, candidate_tokens]
|
| 479 |
+
soft_scores = logits.softmax(dim=-1).tolist()
|
| 480 |
+
|
| 481 |
+
assert len(soft_scores) == len(steps)
|
| 482 |
+
|
| 483 |
+
# Gather step scores
|
| 484 |
+
steps_with_score = []
|
| 485 |
+
for soft_score, step in zip(soft_scores, steps):
|
| 486 |
+
score = 0
|
| 487 |
+
for s, w in zip(soft_score, candidate_weights):
|
| 488 |
+
score += s * w
|
| 489 |
+
steps_with_score.append({'step': step, 'score': score})
|
| 490 |
+
return steps_with_score
|
| 491 |
+
|
| 492 |
+
def generate_overall_score(self, steps_with_score, func=sum):
|
| 493 |
+
overall_score = []
|
| 494 |
+
for step in steps_with_score:
|
| 495 |
+
curr_score = step['score']
|
| 496 |
+
overall_score.append(curr_score)
|
| 497 |
+
|
| 498 |
+
return func(overall_score)
|
| 499 |
+
|
| 500 |
+
@torch.inference_mode()
|
| 501 |
+
def select_best_response(
|
| 502 |
+
self,
|
| 503 |
+
tokenizer,
|
| 504 |
+
question,
|
| 505 |
+
response_list,
|
| 506 |
+
pixel_values=None,
|
| 507 |
+
num_patches_list=None,
|
| 508 |
+
max_steps=12,
|
| 509 |
+
gather_func=None,
|
| 510 |
+
str2score=None,
|
| 511 |
+
return_scores=False,
|
| 512 |
+
):
|
| 513 |
+
if gather_func is None:
|
| 514 |
+
gather_func = lambda x:sum(x)/len(x)
|
| 515 |
+
|
| 516 |
+
sorted_response_list = []
|
| 517 |
+
|
| 518 |
+
for response in response_list:
|
| 519 |
+
steps_with_score = self.generate_steps_with_soft_score(
|
| 520 |
+
tokenizer=tokenizer,
|
| 521 |
+
question=question,
|
| 522 |
+
response=response,
|
| 523 |
+
pixel_values=pixel_values,
|
| 524 |
+
num_patches_list=num_patches_list,
|
| 525 |
+
max_steps=max_steps,
|
| 526 |
+
str2score=str2score,
|
| 527 |
+
)
|
| 528 |
+
overall_score = self.generate_overall_score(steps_with_score, func=gather_func)
|
| 529 |
+
sorted_response_list.append((response, overall_score))
|
| 530 |
+
|
| 531 |
+
sorted_response_list = sorted(sorted_response_list, key=lambda x:x[1], reverse=True)
|
| 532 |
+
|
| 533 |
+
if return_scores:
|
| 534 |
+
return sorted_response_list
|
| 535 |
+
return [item[0] for item in sorted_response_list]
|
| 536 |
+
|
| 537 |
+
@torch.inference_mode()
|
| 538 |
+
def check_correctness(
|
| 539 |
+
self,
|
| 540 |
+
tokenizer,
|
| 541 |
+
question,
|
| 542 |
+
response_list,
|
| 543 |
+
pixel_values,
|
| 544 |
+
num_patches_list=None,
|
| 545 |
+
max_steps=12,
|
| 546 |
+
threshold=0.8,
|
| 547 |
+
str2score=None,
|
| 548 |
+
):
|
| 549 |
+
correctness_list = []
|
| 550 |
+
|
| 551 |
+
for response in response_list:
|
| 552 |
+
steps_with_score = self.generate_steps_with_soft_score(
|
| 553 |
+
tokenizer=tokenizer,
|
| 554 |
+
question=question,
|
| 555 |
+
response=response,
|
| 556 |
+
pixel_values=pixel_values,
|
| 557 |
+
num_patches_list=num_patches_list,
|
| 558 |
+
max_steps=max_steps,
|
| 559 |
+
str2score=str2score,
|
| 560 |
+
)
|
| 561 |
+
correctness = [1 if step_with_score['score'] > threshold else -1 for step_with_score in steps_with_score]
|
| 562 |
+
correctness_list.append(correctness)
|
| 563 |
+
|
| 564 |
+
return correctness_list
|
preprocessor_config.json
ADDED
|
@@ -0,0 +1,19 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"crop_size": 448,
|
| 3 |
+
"do_center_crop": true,
|
| 4 |
+
"do_normalize": true,
|
| 5 |
+
"do_resize": true,
|
| 6 |
+
"feature_extractor_type": "CLIPFeatureExtractor",
|
| 7 |
+
"image_mean": [
|
| 8 |
+
0.485,
|
| 9 |
+
0.456,
|
| 10 |
+
0.406
|
| 11 |
+
],
|
| 12 |
+
"image_std": [
|
| 13 |
+
0.229,
|
| 14 |
+
0.224,
|
| 15 |
+
0.225
|
| 16 |
+
],
|
| 17 |
+
"resample": 3,
|
| 18 |
+
"size": 448
|
| 19 |
+
}
|
special_tokens_map.json
ADDED
|
@@ -0,0 +1,31 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"additional_special_tokens": [
|
| 3 |
+
"<|im_start|>",
|
| 4 |
+
"<|im_end|>",
|
| 5 |
+
"<|object_ref_start|>",
|
| 6 |
+
"<|object_ref_end|>",
|
| 7 |
+
"<|box_start|>",
|
| 8 |
+
"<|box_end|>",
|
| 9 |
+
"<|quad_start|>",
|
| 10 |
+
"<|quad_end|>",
|
| 11 |
+
"<|vision_start|>",
|
| 12 |
+
"<|vision_end|>",
|
| 13 |
+
"<|vision_pad|>",
|
| 14 |
+
"<|image_pad|>",
|
| 15 |
+
"<|video_pad|>"
|
| 16 |
+
],
|
| 17 |
+
"eos_token": {
|
| 18 |
+
"content": "<|im_end|>",
|
| 19 |
+
"lstrip": false,
|
| 20 |
+
"normalized": false,
|
| 21 |
+
"rstrip": false,
|
| 22 |
+
"single_word": false
|
| 23 |
+
},
|
| 24 |
+
"pad_token": {
|
| 25 |
+
"content": "<|endoftext|>",
|
| 26 |
+
"lstrip": false,
|
| 27 |
+
"normalized": false,
|
| 28 |
+
"rstrip": false,
|
| 29 |
+
"single_word": false
|
| 30 |
+
}
|
| 31 |
+
}
|
tokenizer.json
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
tokenizer_config.json
ADDED
|
@@ -0,0 +1,281 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"add_bos_token": false,
|
| 3 |
+
"add_eos_token": false,
|
| 4 |
+
"add_prefix_space": false,
|
| 5 |
+
"added_tokens_decoder": {
|
| 6 |
+
"151643": {
|
| 7 |
+
"content": "<|endoftext|>",
|
| 8 |
+
"lstrip": false,
|
| 9 |
+
"normalized": false,
|
| 10 |
+
"rstrip": false,
|
| 11 |
+
"single_word": false,
|
| 12 |
+
"special": true
|
| 13 |
+
},
|
| 14 |
+
"151644": {
|
| 15 |
+
"content": "<|im_start|>",
|
| 16 |
+
"lstrip": false,
|
| 17 |
+
"normalized": false,
|
| 18 |
+
"rstrip": false,
|
| 19 |
+
"single_word": false,
|
| 20 |
+
"special": true
|
| 21 |
+
},
|
| 22 |
+
"151645": {
|
| 23 |
+
"content": "<|im_end|>",
|
| 24 |
+
"lstrip": false,
|
| 25 |
+
"normalized": false,
|
| 26 |
+
"rstrip": false,
|
| 27 |
+
"single_word": false,
|
| 28 |
+
"special": true
|
| 29 |
+
},
|
| 30 |
+
"151646": {
|
| 31 |
+
"content": "<|object_ref_start|>",
|
| 32 |
+
"lstrip": false,
|
| 33 |
+
"normalized": false,
|
| 34 |
+
"rstrip": false,
|
| 35 |
+
"single_word": false,
|
| 36 |
+
"special": true
|
| 37 |
+
},
|
| 38 |
+
"151647": {
|
| 39 |
+
"content": "<|object_ref_end|>",
|
| 40 |
+
"lstrip": false,
|
| 41 |
+
"normalized": false,
|
| 42 |
+
"rstrip": false,
|
| 43 |
+
"single_word": false,
|
| 44 |
+
"special": true
|
| 45 |
+
},
|
| 46 |
+
"151648": {
|
| 47 |
+
"content": "<|box_start|>",
|
| 48 |
+
"lstrip": false,
|
| 49 |
+
"normalized": false,
|
| 50 |
+
"rstrip": false,
|
| 51 |
+
"single_word": false,
|
| 52 |
+
"special": true
|
| 53 |
+
},
|
| 54 |
+
"151649": {
|
| 55 |
+
"content": "<|box_end|>",
|
| 56 |
+
"lstrip": false,
|
| 57 |
+
"normalized": false,
|
| 58 |
+
"rstrip": false,
|
| 59 |
+
"single_word": false,
|
| 60 |
+
"special": true
|
| 61 |
+
},
|
| 62 |
+
"151650": {
|
| 63 |
+
"content": "<|quad_start|>",
|
| 64 |
+
"lstrip": false,
|
| 65 |
+
"normalized": false,
|
| 66 |
+
"rstrip": false,
|
| 67 |
+
"single_word": false,
|
| 68 |
+
"special": true
|
| 69 |
+
},
|
| 70 |
+
"151651": {
|
| 71 |
+
"content": "<|quad_end|>",
|
| 72 |
+
"lstrip": false,
|
| 73 |
+
"normalized": false,
|
| 74 |
+
"rstrip": false,
|
| 75 |
+
"single_word": false,
|
| 76 |
+
"special": true
|
| 77 |
+
},
|
| 78 |
+
"151652": {
|
| 79 |
+
"content": "<|vision_start|>",
|
| 80 |
+
"lstrip": false,
|
| 81 |
+
"normalized": false,
|
| 82 |
+
"rstrip": false,
|
| 83 |
+
"single_word": false,
|
| 84 |
+
"special": true
|
| 85 |
+
},
|
| 86 |
+
"151653": {
|
| 87 |
+
"content": "<|vision_end|>",
|
| 88 |
+
"lstrip": false,
|
| 89 |
+
"normalized": false,
|
| 90 |
+
"rstrip": false,
|
| 91 |
+
"single_word": false,
|
| 92 |
+
"special": true
|
| 93 |
+
},
|
| 94 |
+
"151654": {
|
| 95 |
+
"content": "<|vision_pad|>",
|
| 96 |
+
"lstrip": false,
|
| 97 |
+
"normalized": false,
|
| 98 |
+
"rstrip": false,
|
| 99 |
+
"single_word": false,
|
| 100 |
+
"special": true
|
| 101 |
+
},
|
| 102 |
+
"151655": {
|
| 103 |
+
"content": "<|image_pad|>",
|
| 104 |
+
"lstrip": false,
|
| 105 |
+
"normalized": false,
|
| 106 |
+
"rstrip": false,
|
| 107 |
+
"single_word": false,
|
| 108 |
+
"special": true
|
| 109 |
+
},
|
| 110 |
+
"151656": {
|
| 111 |
+
"content": "<|video_pad|>",
|
| 112 |
+
"lstrip": false,
|
| 113 |
+
"normalized": false,
|
| 114 |
+
"rstrip": false,
|
| 115 |
+
"single_word": false,
|
| 116 |
+
"special": true
|
| 117 |
+
},
|
| 118 |
+
"151657": {
|
| 119 |
+
"content": "<tool_call>",
|
| 120 |
+
"lstrip": false,
|
| 121 |
+
"normalized": false,
|
| 122 |
+
"rstrip": false,
|
| 123 |
+
"single_word": false,
|
| 124 |
+
"special": false
|
| 125 |
+
},
|
| 126 |
+
"151658": {
|
| 127 |
+
"content": "</tool_call>",
|
| 128 |
+
"lstrip": false,
|
| 129 |
+
"normalized": false,
|
| 130 |
+
"rstrip": false,
|
| 131 |
+
"single_word": false,
|
| 132 |
+
"special": false
|
| 133 |
+
},
|
| 134 |
+
"151659": {
|
| 135 |
+
"content": "<|fim_prefix|>",
|
| 136 |
+
"lstrip": false,
|
| 137 |
+
"normalized": false,
|
| 138 |
+
"rstrip": false,
|
| 139 |
+
"single_word": false,
|
| 140 |
+
"special": false
|
| 141 |
+
},
|
| 142 |
+
"151660": {
|
| 143 |
+
"content": "<|fim_middle|>",
|
| 144 |
+
"lstrip": false,
|
| 145 |
+
"normalized": false,
|
| 146 |
+
"rstrip": false,
|
| 147 |
+
"single_word": false,
|
| 148 |
+
"special": false
|
| 149 |
+
},
|
| 150 |
+
"151661": {
|
| 151 |
+
"content": "<|fim_suffix|>",
|
| 152 |
+
"lstrip": false,
|
| 153 |
+
"normalized": false,
|
| 154 |
+
"rstrip": false,
|
| 155 |
+
"single_word": false,
|
| 156 |
+
"special": false
|
| 157 |
+
},
|
| 158 |
+
"151662": {
|
| 159 |
+
"content": "<|fim_pad|>",
|
| 160 |
+
"lstrip": false,
|
| 161 |
+
"normalized": false,
|
| 162 |
+
"rstrip": false,
|
| 163 |
+
"single_word": false,
|
| 164 |
+
"special": false
|
| 165 |
+
},
|
| 166 |
+
"151663": {
|
| 167 |
+
"content": "<|repo_name|>",
|
| 168 |
+
"lstrip": false,
|
| 169 |
+
"normalized": false,
|
| 170 |
+
"rstrip": false,
|
| 171 |
+
"single_word": false,
|
| 172 |
+
"special": false
|
| 173 |
+
},
|
| 174 |
+
"151664": {
|
| 175 |
+
"content": "<|file_sep|>",
|
| 176 |
+
"lstrip": false,
|
| 177 |
+
"normalized": false,
|
| 178 |
+
"rstrip": false,
|
| 179 |
+
"single_word": false,
|
| 180 |
+
"special": false
|
| 181 |
+
},
|
| 182 |
+
"151665": {
|
| 183 |
+
"content": "<img>",
|
| 184 |
+
"lstrip": false,
|
| 185 |
+
"normalized": false,
|
| 186 |
+
"rstrip": false,
|
| 187 |
+
"single_word": false,
|
| 188 |
+
"special": true
|
| 189 |
+
},
|
| 190 |
+
"151666": {
|
| 191 |
+
"content": "</img>",
|
| 192 |
+
"lstrip": false,
|
| 193 |
+
"normalized": false,
|
| 194 |
+
"rstrip": false,
|
| 195 |
+
"single_word": false,
|
| 196 |
+
"special": true
|
| 197 |
+
},
|
| 198 |
+
"151667": {
|
| 199 |
+
"content": "<IMG_CONTEXT>",
|
| 200 |
+
"lstrip": false,
|
| 201 |
+
"normalized": false,
|
| 202 |
+
"rstrip": false,
|
| 203 |
+
"single_word": false,
|
| 204 |
+
"special": true
|
| 205 |
+
},
|
| 206 |
+
"151668": {
|
| 207 |
+
"content": "<quad>",
|
| 208 |
+
"lstrip": false,
|
| 209 |
+
"normalized": false,
|
| 210 |
+
"rstrip": false,
|
| 211 |
+
"single_word": false,
|
| 212 |
+
"special": true
|
| 213 |
+
},
|
| 214 |
+
"151669": {
|
| 215 |
+
"content": "</quad>",
|
| 216 |
+
"lstrip": false,
|
| 217 |
+
"normalized": false,
|
| 218 |
+
"rstrip": false,
|
| 219 |
+
"single_word": false,
|
| 220 |
+
"special": true
|
| 221 |
+
},
|
| 222 |
+
"151670": {
|
| 223 |
+
"content": "<ref>",
|
| 224 |
+
"lstrip": false,
|
| 225 |
+
"normalized": false,
|
| 226 |
+
"rstrip": false,
|
| 227 |
+
"single_word": false,
|
| 228 |
+
"special": true
|
| 229 |
+
},
|
| 230 |
+
"151671": {
|
| 231 |
+
"content": "</ref>",
|
| 232 |
+
"lstrip": false,
|
| 233 |
+
"normalized": false,
|
| 234 |
+
"rstrip": false,
|
| 235 |
+
"single_word": false,
|
| 236 |
+
"special": true
|
| 237 |
+
},
|
| 238 |
+
"151672": {
|
| 239 |
+
"content": "<box>",
|
| 240 |
+
"lstrip": false,
|
| 241 |
+
"normalized": false,
|
| 242 |
+
"rstrip": false,
|
| 243 |
+
"single_word": false,
|
| 244 |
+
"special": true
|
| 245 |
+
},
|
| 246 |
+
"151673": {
|
| 247 |
+
"content": "</box>",
|
| 248 |
+
"lstrip": false,
|
| 249 |
+
"normalized": false,
|
| 250 |
+
"rstrip": false,
|
| 251 |
+
"single_word": false,
|
| 252 |
+
"special": true
|
| 253 |
+
}
|
| 254 |
+
},
|
| 255 |
+
"additional_special_tokens": [
|
| 256 |
+
"<|im_start|>",
|
| 257 |
+
"<|im_end|>",
|
| 258 |
+
"<|object_ref_start|>",
|
| 259 |
+
"<|object_ref_end|>",
|
| 260 |
+
"<|box_start|>",
|
| 261 |
+
"<|box_end|>",
|
| 262 |
+
"<|quad_start|>",
|
| 263 |
+
"<|quad_end|>",
|
| 264 |
+
"<|vision_start|>",
|
| 265 |
+
"<|vision_end|>",
|
| 266 |
+
"<|vision_pad|>",
|
| 267 |
+
"<|image_pad|>",
|
| 268 |
+
"<|video_pad|>"
|
| 269 |
+
],
|
| 270 |
+
"bos_token": null,
|
| 271 |
+
"chat_template": "{%- if tools %}\n {{- '<|im_start|>system\\n' }}\n {%- if messages[0]['role'] == 'system' %}\n {{- messages[0]['content'] }}\n {%- else %}\n {{- 'You are Qwen, created by Alibaba Cloud. You are a helpful assistant.' }}\n {%- endif %}\n {{- \"\\n\\n# Tools\\n\\nYou may call one or more functions to assist with the user query.\\n\\nYou are provided with function signatures within <tools></tools> XML tags:\\n<tools>\" }}\n {%- for tool in tools %}\n {{- \"\\n\" }}\n {{- tool | tojson }}\n {%- endfor %}\n {{- \"\\n</tools>\\n\\nFor each function call, return a json object with function name and arguments within <tool_call></tool_call> XML tags:\\n<tool_call>\\n{\\\"name\\\": <function-name>, \\\"arguments\\\": <args-json-object>}\\n</tool_call><|im_end|>\\n\" }}\n{%- else %}\n {%- if messages[0]['role'] == 'system' %}\n {{- '<|im_start|>system\\n' + messages[0]['content'] + '<|im_end|>\\n' }}\n {%- else %}\n {{- '<|im_start|>system\\nYou are Qwen, created by Alibaba Cloud. You are a helpful assistant.<|im_end|>\\n' }}\n {%- endif %}\n{%- endif %}\n{%- for message in messages %}\n {%- if (message.role == \"user\") or (message.role == \"system\" and not loop.first) or (message.role == \"assistant\" and not message.tool_calls) %}\n {{- '<|im_start|>' + message.role + '\\n' + message.content + '<|im_end|>' + '\\n' }}\n {%- elif message.role == \"assistant\" %}\n {{- '<|im_start|>' + message.role }}\n {%- if message.content %}\n {{- '\\n' + message.content }}\n {%- endif %}\n {%- for tool_call in message.tool_calls %}\n {%- if tool_call.function is defined %}\n {%- set tool_call = tool_call.function %}\n {%- endif %}\n {{- '\\n<tool_call>\\n{\"name\": \"' }}\n {{- tool_call.name }}\n {{- '\", \"arguments\": ' }}\n {{- tool_call.arguments | tojson }}\n {{- '}\\n</tool_call>' }}\n {%- endfor %}\n {{- '<|im_end|>\\n' }}\n {%- elif message.role == \"tool\" %}\n {%- if (loop.index0 == 0) or (messages[loop.index0 - 1].role != \"tool\") %}\n {{- '<|im_start|>user' }}\n {%- endif %}\n {{- '\\n<tool_response>\\n' }}\n {{- message.content }}\n {{- '\\n</tool_response>' }}\n {%- if loop.last or (messages[loop.index0 + 1].role != \"tool\") %}\n {{- '<|im_end|>\\n' }}\n {%- endif %}\n {%- endif %}\n{%- endfor %}\n{%- if add_generation_prompt %}\n {{- '<|im_start|>assistant\\n' }}\n{%- endif %}\n",
|
| 272 |
+
"clean_up_tokenization_spaces": false,
|
| 273 |
+
"eos_token": "<|im_end|>",
|
| 274 |
+
"errors": "replace",
|
| 275 |
+
"extra_special_tokens": {},
|
| 276 |
+
"model_max_length": 16384,
|
| 277 |
+
"pad_token": "<|endoftext|>",
|
| 278 |
+
"split_special_tokens": false,
|
| 279 |
+
"tokenizer_class": "Qwen2Tokenizer",
|
| 280 |
+
"unk_token": null
|
| 281 |
+
}
|
vocab.json
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|