Pandemonium: The Transformers Story







This article was originally published here

Let us think the unthinkable, let us do the undoable, let us prepare to grapple with the ineffable itself, and see if we may not eff it after all. ~Douglas Adams
Transformer’s “Attention Is All You Need” paper has become a legend. It's likely the only modern AI paper with its own Wikipedia page, and by the time this was written, it had been cited over 160,000 times. It has become such a legend that in 2023, about six years after the latest arXiv version, a new one was put out mainly to add this:
 Figure 01: from https://arxiv.org/abs/1706.03762v7
Figure 01: from https://arxiv.org/abs/1706.03762v7
The story behind the paper and the origins of its ideas are as rich and interesting as the paper itself. It's about a group of people who got together because of one idea, and they became really focused and obsessed with it. It has enough going on that it would be a hit at the box office if someone made it into a film. Adam McKay or David Fincher, if you're reading this: I'm ready to script this instant classic! Guaranteed.
This story has already been covered before, most notably by Wired (my favorite!), The New Yorker, Bloomberg, and Financial Times. While those articles offered valuable overviews for a broad audience, they remained on the surface, technically speaking.
In this article, I aim to tell the story of Transformers as I would have wanted to read it, and hopefully, one that appeals to others interested in the details of this fascinating idea. This narrative draws from video interviews, lectures, articles, tweets/Xs, and some digging into the literature. I have done my best to be accurate, but errors are possible. If you find inaccuracies or have any additions, please do reach out, and I will gladly make the necessary updates.
It all started with Attention…
The Inevitability of Attention
Machine translation was the primary engine driving early progress in Natural Language Processing. Google's investment in Google Translate (Launched in 2006) highlights this, as it became a key project directing substantial resources into specific areas of NLP research.
But machine translation wasn't just about brute-force word swapping. A complex problem quickly emerged: alignment. Languages aren't just word-for-word replacements of each other. To truly translate, you need to understand how phrases, sentence structures, and even cultural context in one language align with their counterparts in another. Simply put, alignment is the process of matching corresponding segments of text between languages during translation.
Besides alignment, another fundamental, but not as complex, hurdle in machine translation stemmed from the very nature of language itself: variable-length input. Unlike, for example, computer vision problems that deal with fixed-size data, language is inherently flexible. Machine translation systems needed to be able to handle this variability while still producing coherent and accurate translations.
 Figure 02: from Sequence to Sequence Learning with Neural Networks, and Learning Phrase Representations using RNN Encoder-Decoder for Statistical Machine Translation
Figure 02: from Sequence to Sequence Learning with Neural Networks, and Learning Phrase Representations using RNN Encoder-Decoder for Statistical Machine Translation
To address variable-length input, the encoder-decoder architecture, introduced in two different papers that came up around the same time, became the standard approach in machine translation. The core idea was to take that messy, variable-length input sentence and compress it into a single, fixed-size vector. A kind of information bottleneck. This fixed-size vector, created by the encoder, was then meant to encapsulate the entire meaning of the input sentence. The decoder would then take this fixed-size representation and use it to generate a translated sentence, word by word.
While this encoder-decoder approach offered a seemingly elegant way to handle variable input, it wasn't a perfect fix. Particularly with very long sentences, squeezing the entire meaning into a single, fixed-size vector inevitably led to information loss and translation quality degradation. Which brings us back to alignment!
Instead of trying to force the encoder to squeeze the meaning of an entire sentence into a single fixed-size vector, why not let it encode the input sentence into a sequence of vectors and let the decoder (search) for the right word from the source sentence during translation?
 Figure 03: from https://github.com/google/seq2seq
Figure 03: from https://github.com/google/seq2seq
In 2014, Dzmitry Bahdanau was an intern at Yoshua Bengio's lab. He was assigned to the machine translation project to work with Kyunghyun Cho and the team. Their team released one of the two papers introducing the encoder-decoder architecture for machine translation (the other one came out of Google from Ilya Sutskever and team). And, like many, he wasn't happy with cramming the meaning of a sentence into a single vector, it just doesn't make sense!
Inspired by his own translation exercises during middle school, he wondered: Instead of trying to force the encoder to squeeze the meaning of an entire sentence into a single fixed-size vector, why not let it encode the input sentence into a sequence of vectors and let the decoder (search) for the right word from the source sentence during translation, solving both the cramming and alignment problems for good? and the answer to this question was the Neural Machine Translation by Jointly Learning to Align and Translate (AKA attention) paper.
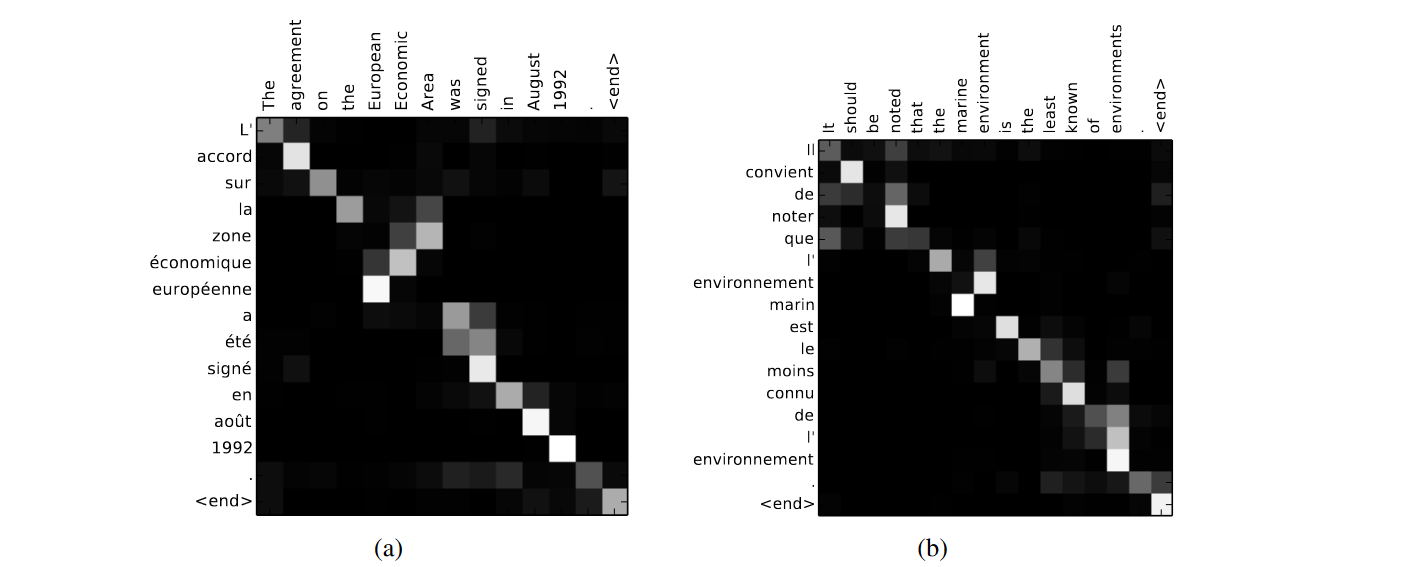 Figure 04: Sample alignments found by RNNsearch-50. from https://arxiv.org/abs/1409.0473
Figure 04: Sample alignments found by RNNsearch-50. from https://arxiv.org/abs/1409.0473
Interestingly, if you read the paper, you will find this mechanism referred to as RNNSearch. It was Yoshua Bengio who came up with the term attention, in a brief paragraph explaining the intuition behind their mechanism.
 Figure 05: from https://arxiv.org/abs/1409.0473
Figure 05: from https://arxiv.org/abs/1409.0473
The story behind the origin and the inspiration behind the attention mechanism was told in a correspondence email between Andrej Karpathy and Dzmitry Bahdanau. And was later shared in this tweet by Andrej on X.
 Figure 06: Attention’s origin story. from Andrej Karpathy's tweet
Figure 06: Attention’s origin story. from Andrej Karpathy's tweet
While Dzmitry's paper is frequently credited with the popularization of the attention mechanism (they came up with a great name after all!), the underlying concept had been explored in many other concurrent works. In particular, I appreciate the section where Dzmitry discusses how the attention idea was, in his view, inevitable, merely awaiting the right moment for its emergence.
But I don't think that this idea would wait for any more time before being discovered. Even if myself, Alex Graves and other characters in this story did not do deep learning at that time, attention is just the natural way to do flexible spatial connectivity in deep learning. It is a nearly obvious idea that was waiting for GPUs to be fast enough to make people motivated and take deep learning research seriously. ~ Dzmitry Bahdanau
Attention was inevitable!
The Seed of A Heresy: Self-attention
We propose a new simple network architecture, the Transformer, based solely on attention mechanisms, dispensing with recurrence and convolutions entirely. ~ Attention Is All You Need
By 2016, attention had become established in the field, and Google announced that Google Translate, a decade after its 2006 launch, would transition to a neural machine translation engine: Google Neural Machine Translation (GNMT). The details and architecture of GNMT were outlined in a comprehensive technical report.
 Figure 07: from https://arxiv.org/abs/1609.08144
Figure 07: from https://arxiv.org/abs/1609.08144
The report had many big names on it, like Jeff Dean, Oriol Vinyals, Greg Corrado, Quoc Le, and Lukasz Kaiser, a co-author of Attention is All You Need. GNMT aimed to leverage the capabilities of neural machine translation systems while mitigating their weaknesses such as, being computationally expensive and lack of robustness. The proposed system was an 8-layer LSTM (RNN) encoder-decoder with attention, and other improvements such as residual connections between layers, wordpiece tokenization, and quantization.
They even experimented with reinforcement learning to (refine) the model, but it only pumped up the BLEU score without an increase in quality that is noticeable by humans. The paper is interesting and has many insights, I encourage you to read it.
 Figure 08: from https://arxiv.org/abs/1609.08144
Figure 08: from https://arxiv.org/abs/1609.08144
Let's quickly look at where we are now. We've got the encoder-decoder architecture that can handle tasks like machine translation from start to finish. And thanks to attention, we don't have to cram the whole sentence's meaning into one tiny vector anymore. Plus, we've got a production-grade system out there, using and optimizing this very technology. Problem solved, or is there more to it?
 Figure 09: from https://arxiv.org/abs/1601.06733
Figure 09: from https://arxiv.org/abs/1601.06733
There is still one more bottleneck.
 Figure 10: from https://arxiv.org/abs/1601.06733
Figure 10: from https://arxiv.org/abs/1601.06733
In the same year, researchers from the University of Edinburgh presented Long Short-Term Memory-Networks (LSTMN). Inspired by how humans process language and by Memory Networks that were introduced in 2014, LSTMN aims to enable LSTM to reason about relations between tokens with attention by storing the representation of each input token in a unique memory slot instead of compressing them in a fixed-size memory.
 Figure 11: from https://arxiv.org/abs/1601.06733
Figure 11: from https://arxiv.org/abs/1601.06733
What's interesting is that we can now plug LSTMN into an encoder-decoder setup, and that gives us two types of attention: “inter-attention” which looks between the encoder and the decoder, and “intra-attention” which looks at the relationships between words (tokens) within the same sequence as we can see in the figure.
The Elephant In The Room
O you who know what we suffer here, do not forget us in your prayers. ~ Manual of Muad'Dib by the Princess Irulan
So, here's where things get interesting, and where our story starts. We've almost gathered all the key ingredients needed to conjure a transformer:
The encoder-decoder architecture.
Two different types of attention: inter-attention (between encoder and decoder) and intra-attention (within a sequence).
Residual connections.
Now, the question is: what vital component is still missing from our recipe? Or perhaps more accurately, which (seemingly) essential piece can we actually (be happy to) do without?
The answer, you might already suspect, is the Recurrent Neural Network (RNN).
Without several tricks, RNNs were, and remain, a headache to work with, and scaling them up effectively was an even greater challenge. Their fundamental flaw lies in their sequential processing; it doesn't "make accelerators happy". This begs the question: could we conceive of an alternative architecture that overcomes these limitations?
In 2016, Jakob Uszkoreit, a co-author of the “Attention is All You Need” paper, was part of a research team investigating this very possibility. Their proposed alternative to RNNs was the elimination of recurrence altogether, relying solely on attention mechanisms. Focusing on the natural language inference (NLI) task, the team introduced the Decomposable Attention (DecAtt) model; a simple architecture that only relies on alignment and is "fully computationally decomposable with respect to the input text".
 Figure 12: from https://arxiv.org/abs/1606.01933
Figure 12: from https://arxiv.org/abs/1606.01933
By decomposing the NLI task into independent subproblems (as illustrated in the figure), and using only inter-attention and feed-forward networks, they achieved state-of-the-art results on the SNLI dataset with a parameter count nearly an order of magnitude smaller than that of LSTMN. Additionally, they explored the incorporation of intra-attention (from LSTMN), referred to as intra-sentence attention in the paper, which led to a considerable improvement in performance.
 Figure 13: from https://arxiv.org/abs/1606.01933
Figure 13: from https://arxiv.org/abs/1606.01933
In a follow-up paper, motivated by this promising result, they applied the DecAtt model alongside character n-gram (instead of word) embeddings and pretraining to the task of question paraphrase identification. Notably, this is probably the first paper where the term “self-attention” is used.
 Figure 14: The term “self-attention” being born. from https://arxiv.org/abs/1704.04565
Figure 14: The term “self-attention” being born. from https://arxiv.org/abs/1704.04565
Once again, their proposed model demonstrated exceptional performance, surpassing several more complex architectures on the Quora question paraphrase dataset.
 Figure 15: from https://arxiv.org/abs/1704.04565
Figure 15: from https://arxiv.org/abs/1704.04565
But Jakob wasn't satisfied yet. He wanted to take this idea even further by using much larger amounts of data. However, the rest of the team felt differently. They were really happy with their success and decided to focus on getting the system ready to use in real-world applications instead of trying to push its limits further. Jakob, though, had a different view. He saw self-attention as a better and more natural way for computers to process sequences.
He wasn't merely interested in self-attention; he was consumed by it. This wasn't just an intellectual curiosity; it was a defining focus akin to Geoffrey Hinton's legendary dedication to neural networks, or Alec Radford's intense obsession with language models (a story for another time perhaps). Jakob’s focus on self-attention possessed that same intensity, that same field-altering potential.
Why not use self-attention? ~ Jakob Uszkoreit’s suggestion for a solution to a problem that was facing his colleague Illia Polosukhin.
But just using self-attention wasn't enough to get us to where we are today. To really work, it needed some other pieces. These other pieces came from a new group of people who were strongly committed to the idea. Now, let's talk briefly about how the people who made the Transformer came together.
Coming Together
The team behind "Attention is All You Need" didn't assemble through some formal project directive. Instead, it happened more by chance and in a natural way, like things growing together slowly and smoothly (organically, we might say). The team didn't form all at once; it was more like people joining in waves. What held them together was their strong focus on one ambitious idea.
It all started with Jakob Uszkoreit and Illia Polosukhin, already working closely within Building 1945. Ashish Vaswani was working on machine translation in building 1965, next door to Illia and Jakob's building. It was close enough for whispers of a radical new idea to cross the office park. Intrigued by what he overheard, and drawn to the ambitious potential of the idea, Ashish made the short walk over to Building 1945 and joined them. These three - Jakob, Illia, and Ashish - formed the first wave of members to join the project.
A recurring theme will become noticeable throughout our story: a new member overhearing the group's discussion, becoming excited about their idea, and subsequently joining the team. Indeed, the surrounding environment played a pivotal role in facilitating this natural expansion, as we will see.
Niki Parmer and Llion Jones joined the team. Niki learned about the idea through her work with Jakob, and Llion through his association with Illia. Interestingly, despite working with Illia, Llion didn't hear about self-attention directly from him. Instead, he heard about it from another colleague. Intrigued by the concept, Llion then decided to join the team. Their arrival marked the second wave of the team's formation.
Returning to the influence of the environment, let’s note that while most of the team, with the exception of Ashish, had desks in Building 1945, they mostly worked in Building 1965. This was largely due to the presence of a superior espresso machine in its micro-kitchen. This seemingly minor detail played a significant role in the subsequent expansion of the team.
Working in building 1965, their work attracted Lukasz Kaiser and, back then an intern, Aidan Gomez after (again) overhearing the discussion. Both were working on Tensor2Tensor. For those curious about the fate of Tensor2Tensor, it has since developed into Trax, which is one of Google's neural network libraries built on top of JAX.
Lukasz is kind of a master of keeping track of everything that's happening in the field and adopting it. And so, within tensor2tensor there were like these emerging little things that maybe one paper had been written about and people were interested in, like LayerNorm and the warm up in the learning rate schedule, but it hadn't actually taken off yet. All of these little pieces were just on by default. And so, when Noam, Ashish, Niki, and Jakob came over and adopted tensor2tensor, all of these things were just on by default. ~ Aidan Gomez
Similarly, Noam Shazeer heard a conversation about self-attention and a plan to replace RNNs while walking down a corridor in Building 1965 and passing Lukasz’s workspace. He got so excited and immediately decided to join them, marking the final wave of members and the team's completion.
These theoretical or intuitive mechanisms, like self-attention, always require very careful implementation, often by a small number of experienced ‘magicians,’ to even show any signs of life. ~ Jakob Uszkoreit
It’s safe to say that Building 1965’s espresso machine deserves at least an acknowledgment in the paper.
Jailbreaking The Genie
We had gone from no proof of concept to having something that was at least on par with the best alternative approaches to LSTMs by that time. ~ Jakob Uszkoreit
 Figure 16: from Transformer: A Novel Neural Network Architecture for Language Understanding
Figure 16: from Transformer: A Novel Neural Network Architecture for Language Understanding
Big Ambitions
At first, without knowing the full picture, I figured those were just some incredibly smart people tackling machine translation, maybe chasing after a wildly high BLEU score and accidentally hitting upon something huge. But the reality is, their ambition was far greater. They were essentially using machine translation as a trojan horse to sneak their real idea into the world. Their aim was a model that could understand all kinds of inputs: text, images, and video. A multi-modal model. And, more fundamentally, a future for deep learning that relied less on sequential processing.
From Ashish’s words:
We kind of failed at our original ambition. We started this because we wanted to model the evolution of tokens. It wasn't just linear generation, but text, or code evolves. We iterate, we edit, and that allows us to potentially mimic how humans are evolving text, but also have them as a part of the process. Because if you naturally generate it as humans are generating it, they can actually get feedback. ~ Ashish Vaswani
And also from the conclusion of the paper, in which they promise that they will be back:
 Figure 17: from https://arxiv.org/abs/1706.03762
Figure 17: from https://arxiv.org/abs/1706.03762
A promise on which they immediately delivered. In the same month, they followed their groundbreaking “Attention is All You Need” paper with “One Model To Learn Them All”, introducing the MultiModel. This new architecture incorporated building blocks such as convolutions, attention mechanisms, and sparsely-gated mixture-of-experts; to process diverse input and output modalities. Admittedly, the name lacks the same immediate catchiness as “Transformer” and the paper didn’t get enough attention (no pun intended). Nevertheless, I encourage you to have a look at this ahead-of-its-time paper.
 Figure 18: from https://arxiv.org/abs/1706.05137
Figure 18: from https://arxiv.org/abs/1706.05137
Back to “Attention Is All You Need”…
Despite their ambitious goals, they importantly aimed to keep things as simple as possible right from the start. They even had an early proof of concept that already competed with existing alternatives to LSTMs. This is a nice illustration of Gall's Law: “A complex system that works is invariably found to have evolved from a simple system that worked. A complex system designed from scratch never works and cannot be patched up to make it work. You have to start over with a working simple system.”
Building upon their initial foundation, they began adding and experimenting with various components, a process significantly facilitated by the Tensor2Tensor library. As previously mentioned, Lukasz and Aidan were already working on Tensor2Tensor before becoming part of the team. And it was another ambitious project striving to push the boundaries of auto-regressive and multi-modal learning. The library offered numerous novel and emerging pieces at the time, such as Layer Normalization and the warm-up learning rate schedule.
I always thought it was kind of funny how all of these random additions that Lukasz had just thrown in because he was playing around with them turned out to be crucial. ~ Aidan Gomez
A parallel that comes to mind is the story of Rotary Positional Embeddings (RoPE), which ultimately revolutionized the way neural networks handle positional encoding. The paper introducing RoPE was published in 2021 and gained prominence, probably through its adoption in EleutherAI's GPT-J and later in Meta's Llama (based on GPT-J’s implementation). It does, indeed, pay to keep up with the literature!
Speaking of positional encoding, the parameter-free position representation and the multi-head attention proposed by Noam Shazeer, proved to be among the most critical elements that led to the dethroning of LSTMs and RNNs in general. Around early 2017, Noam (along with Geoffrey Hinton, Jeff Dean, and others), had recently released the Sparsely-Gated Mixture-of-Experts layer (MoE) paper. You could guess that ideas from that paper were floating around in his mind when he came up with multi-head attention.
 Figure 19: Mixture-of-Experts and Multi-head Attention
Figure 19: Mixture-of-Experts and Multi-head Attention
And so, they continued to refine their initial model through constant iteration, adding new components and experimenting with various implementations. Interestingly, their exploration even led them to incorporate convolutions at one stage. But the big questions were: Which of these new additions really made the model better? And were there any parts they could leave out?
Here comes the most fascinating part of the story!
Ablations
What's intriguing about that [Finding out that removing convolutions during ablations improved performance] is we actually kind of started with that barebones thing, right? and then we added stuff. we added convolutions, and I guess later on, we kind of knocked them out. ~ Ashish Vaswani
This is a great example of the crucial role that ablations play in strengthening already robust work. The extensive ablations detailed in the paper significantly shaped the final architecture of the model and even influenced its title, as we will soon see. Interestingly, the ablation results presented in the paper (as shown in the table below) represented only a fraction of the total experiments they conducted.
 Figure 20: from https://arxiv.org/abs/1706.03762
Figure 20: from https://arxiv.org/abs/1706.03762
It's as if they encountered an instance of Gall's Law but with a twist! They began with a simple model, incrementally added several components to enhance performance, and then further improved performance by strategically removing elements.
Fantastic Names And Where To Find Them
We have two memorable names to explore: the architecture itself and the title of the paper. What are the stories behind these names, and how did the creators come up with them? Let's begin with “Transformer”.
“Transformer” was there from day one, and it was even a contender for the paper's title. When Jakob, Illia, and Ashish first collaborated on the project, their initial working title for the paper was “Transformers: Iterative Self-Attention and Processing for Various Tasks”. The term “Transformer” drew inspiration from two key aspects: First, the system's core mechanism of transforming input data to extract meaningful information. While, as many have observed, this could describe almost all machine learning systems, it is still a great name. Second, it was a playful nod to our friends from Cybertron 😃. Here’s a conversation between Jakob and Jensen Huang about “Transformer”:
Jakob: It fits what the model does, right? every step actually transforms the entire signal it operates on, as opposed to having to go, you know, iterate over it step by step.
Jensen: Using that logic, almost all machine learning models are transformers!
Jakob: Before that, nobody thought to use the name.
Although “Transformer” was there from the beginning, it was not the only contender. In a slightly different reality, we might have known this architecture as “CargoNet”. To understand the rationale behind this alternative name, let's hear from Noam Shazeer:
There were lots of names. I mean, like, there was something called CargoNet. I wrote something, one layer was like convolution, one was attention, one I called recognition or something that was like the feed-forward net. And so, convolution, attention, recognition, Google...CargoNet! ~ Noam Shazeer
An interesting anecdote surrounding Transformers and attention, likely popularized by this tweet which generated considerable discussion at the time, suggests an inspiration drawn from the alien language in Denis Villeneuve’s 2016 film Arrival, which itself was based on Ted Chiang’s 1998 novella Story of Your Life. For those unfamiliar with Arrival, the alien language featured in the film has two forms, reflecting distinct perceptions of time. One form presents time as linear and sequential, while the other portrays it as simultaneous and synchronous, with a single circular symbol capable of conveying a wealth of meaning. Yes, the analogy here is quite evident, and it would have been a great story if it were true. But unfortunately, it's not the case…
 Figure 21: Alien Language from Arrival (2016)
Figure 21: Alien Language from Arrival (2016)
The origin of this anecdote can be traced back to an episode of the Hard Fork podcast. During the episode, the host mistakenly interpreted a comparison made by Illia Polosukhin in the Financial Times article, where he likened self-attention to the alien language in Arrival. Illia's comparison, however, did not suggest any actual inspiration. This tweet probably prompted Andrej Karpathy to share his email correspondence with Dzmitry Bahdanau about the origins of attention.
Now, the paper title. It was Llion Jones who came up with “Attention Is All Your Need”. This came about during the period when they were conducting ablation studies and discovering that the attention mechanism, above all other components, was the most critical. It’s also a reference to the Beatles’ iconic song “All You Need Is Love”.
So, I came up with the title, and basically what happened was, at the point where we were looking for a title, we were just doing ablations, and we had very recently started throwing bits of the model away just to see how much worse it would get. And to our surprise, it started getting better, including throwing all the convolutions away. I'm like, "This is working much better!". And that's what was in my mind at the time, and so that's where the title comes from. ~ Llion Jones
And so, on Monday, June 12, 2017, “Attention Is All You Need” was released on arXiv, a date we might well consider as Transformer Day.
 Figure 22: Behold! The Transformer!
Figure 22: Behold! The Transformer!
Finally, the iconic Transformer figure was made using Adobe Illustrator. No more intrigue!
Life After Transformers
Without transformers I don’t think we’d be here now. ~ Geoffrey Hinton
Transformer changed everything, there's no denying that. But how was it received at the time? It's easy to look back now with the benefit of hindsight and see its monumental impact. However, revisiting the NeurIPS 2017 submission reviews reveals a spectrum of opinions, ranging from “This is very exciting!” to “This is ok”. Let’s hear what reviewer 1 has to say:
 Figure 23: Paper’s NeurIPS 2017 Review
Figure 23: Paper’s NeurIPS 2017 Review
But we can't forget about Reviewer #2!
I was also curious about the first context in which the paper was cited. Interestingly, the earliest paper citing the Transformer that I could locate was a revision to a deep reinforcement learning overview. This overview was initially released in early 2017 and then resubmitted on July 15th (about a month after the “Attention Is All You Need” release).
 Figure 24: from https://arxiv.org/abs/1701.07274v3
Figure 24: from https://arxiv.org/abs/1701.07274v3
Building on their initial success, the authors didn't stop at text (as they promised). They immediately began exploring the potential of Transformers in a diverse array of other fields. For example, they developed the Image Transformer to see if attention could revolutionize how computers understand pictures, Music Transformer to explore generating music (obviously!), and Universal Transformers which was an attempt at a generalization of the Transformer model that had a dynamic halting mechanism, allocating different processing time for different tokens based on how difficult they are. And all this was in 2018!
So, life after Transformers? well,…
The arrival of the Transformer architecture heralded the modern AI boom, acting as a powerful catalyst that propelled the field into a new era of rapid progress. To this day, it remains the foundational technology underpinning the remarkable advancements we're witnessing in large language models (LLMs). So, yeah, you could say it was a pretty big deal 😃.