
Update README.md
Browse files
README.md
CHANGED
|
@@ -2,8 +2,70 @@
|
|
| 2 |
library_name: transformers
|
| 3 |
tags:
|
| 4 |
- llama-factory
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 5 |
---
|
| 6 |
|
| 7 |
# DeepSeek-R1-Distill-Qwen-7B-News-Classifier
|
| 8 |
|
| 9 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 2 |
library_name: transformers
|
| 3 |
tags:
|
| 4 |
- llama-factory
|
| 5 |
+
- lora
|
| 6 |
+
- news-classification
|
| 7 |
+
- text-classification
|
| 8 |
+
- chinese
|
| 9 |
+
- deepseek-r1
|
| 10 |
+
- qwen
|
| 11 |
---
|
| 12 |
|
| 13 |
# DeepSeek-R1-Distill-Qwen-7B-News-Classifier
|
| 14 |
|
| 15 |
+
## Model Description
|
| 16 |
+
|
| 17 |
+
DeepSeek-R1-Distill-Qwen-7B-News-Classifier is a fine-tuned version of [DeepSeek-R1-Distill-Qwen-7B](https://huggingface.co/deepseek-ai/DeepSeek-R1-Distill-Qwen-7B), specially optimized for news classification tasks. The base model is a distilled version from DeepSeek-R1 using Qwen2.5-Math-7B as its foundation.
|
| 18 |
+
|
| 19 |
+
## Demo
|
| 20 |
+
|
| 21 |
+
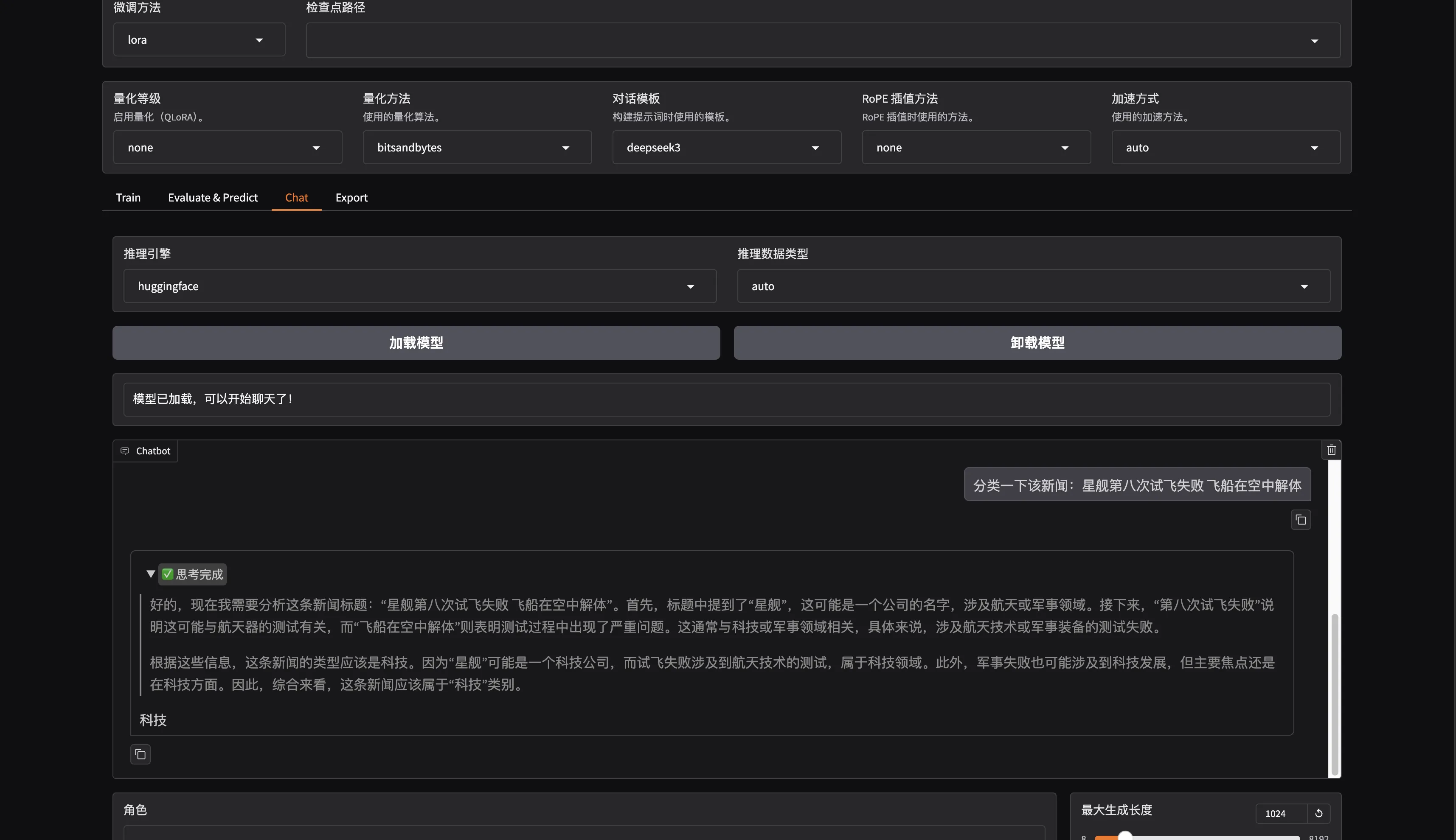
|
| 22 |
+
|
| 23 |
+
## Training Details
|
| 24 |
+
|
| 25 |
+
### Training Data
|
| 26 |
+
|
| 27 |
+
The model was fine-tuned on a custom dataset of 300 news classification examples in ShareGPT format. Each example contains:
|
| 28 |
+
- A news headline with a classification request prefix (e.g., "新闻分类:" or similar)
|
| 29 |
+
- The expected category output with reasoning chain
|
| 30 |
+
|
| 31 |
+
### Training Procedure
|
| 32 |
+
|
| 33 |
+
- **Framework:** LLaMA Factory
|
| 34 |
+
- **Fine-tuning Method:** LoRA with LoRA+ optimizer
|
| 35 |
+
- **LoRA Parameters:**
|
| 36 |
+
- LoRA+ learning rate ratio: 16
|
| 37 |
+
- Target modules: all linear layers
|
| 38 |
+
- Base learning rate: 5e-6
|
| 39 |
+
- Gradient accumulation steps: 2
|
| 40 |
+
- Training epochs: 3
|
| 41 |
+
|
| 42 |
+
## Evaluation Results
|
| 43 |
+
|
| 44 |
+
The model was evaluated on a test set and achieved the following metrics:
|
| 45 |
+
|
| 46 |
+
- **BLEU-4:** 29.67
|
| 47 |
+
- **ROUGE-1:** 56.56
|
| 48 |
+
- **ROUGE-2:** 31.31
|
| 49 |
+
- **ROUGE-L:** 39.86
|
| 50 |
+
|
| 51 |
+
These scores indicate strong performance for the news classification task, with good alignment between model outputs and reference classifications.
|
| 52 |
+
|
| 53 |
+
## Citation
|
| 54 |
+
|
| 55 |
+
If you use this model in your research, please cite:
|
| 56 |
+
|
| 57 |
+
```bibtex
|
| 58 |
+
@misc{deepseekai2025deepseekr1incentivizingreasoningcapability,
|
| 59 |
+
title={DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning},
|
| 60 |
+
author={DeepSeek-AI},
|
| 61 |
+
year={2025},
|
| 62 |
+
eprint={2501.12948},
|
| 63 |
+
archivePrefix={arXiv},
|
| 64 |
+
primaryClass={cs.CL},
|
| 65 |
+
url={https://arxiv.org/abs/2501.12948},
|
| 66 |
+
}
|
| 67 |
+
```
|
| 68 |
+
|
| 69 |
+
## Acknowledgements
|
| 70 |
+
|
| 71 |
+
This model was fine-tuned using the [LLaMA Factory](https://github.com/hiyouga/LLaMA-Factory) framework. We appreciate the contributions of the DeepSeek AI team for the original distilled model.
|