Spaces:
Running

Running
Initial commit of the Computer Vision Journey presentation, including main application files, project pages, assets, and configuration. Added .gitignore to exclude unnecessary files and created requirements.txt for dependencies.
Browse files- .gitattributes +24 -0
- .gitignore +8 -0
- .streamlit/config.toml +15 -0
- README.md +88 -0
- app.py +176 -0
- assets/.gitkeep +12 -0
- assets/[Samuel] Fine-tuning Structured OCR.md +350 -0
- assets/activations_diagram.md +71 -0
- assets/black_bee.png +3 -0
- assets/data_diagram.md +88 -0
- assets/database_diagram.md +13 -0
- assets/drone_line_following_video.mp4 +3 -0
- assets/full_diagram.md +694 -0
- assets/generic_eval_all.html +0 -0
- assets/hand_control_arm_video.mp4 +3 -0
- assets/heatmap_accuracy.html +0 -0
- assets/imav_mission_diagram.jpg +3 -0
- assets/layers_diagram.md +152 -0
- assets/linear.png +3 -0
- assets/losses_diagram.md +43 -0
- assets/metrics_diagram.md +53 -0
- assets/model_performance_by_category.html +0 -0
- assets/models_diagram.md +38 -0
- assets/optimizers_diagram.md +164 -0
- assets/profile.jpg +3 -0
- assets/quickdraw_game_video.mp4 +3 -0
- assets/robotic_arm.jpg +3 -0
- assets/rosenbrock2.png +3 -0
- assets/saddle_function2.png +3 -0
- assets/signature_article.md +588 -0
- assets/sine.png +3 -0
- assets/train_diagram.md +83 -0
- pages/1_black_bee_drones.py +337 -0
- pages/2_asimo_foundation.py +286 -0
- pages/3_cafe_dl.py +596 -0
- pages/4_tech4humans.py +695 -0
- pages/5_conclusion.py +266 -0
- requirements.txt +7 -0
- utils/__init__.py +1 -0
- utils/helpers.py +80 -0
.gitattributes
CHANGED
|
@@ -33,3 +33,27 @@ saved_model/**/* filter=lfs diff=lfs merge=lfs -text
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
| 36 |
+
# Video files
|
| 37 |
+
*.mp4 filter=lfs diff=lfs merge=lfs -text
|
| 38 |
+
*.mov filter=lfs diff=lfs merge=lfs -text
|
| 39 |
+
*.avi filter=lfs diff=lfs merge=lfs -text
|
| 40 |
+
*.wmv filter=lfs diff=lfs merge=lfs -text
|
| 41 |
+
*.mkv filter=lfs diff=lfs merge=lfs -text
|
| 42 |
+
*.webm filter=lfs diff=lfs merge=lfs -text
|
| 43 |
+
# Image files
|
| 44 |
+
*.jpg filter=lfs diff=lfs merge=lfs -text
|
| 45 |
+
*.jpeg filter=lfs diff=lfs merge=lfs -text
|
| 46 |
+
*.png filter=lfs diff=lfs merge=lfs -text
|
| 47 |
+
*.gif filter=lfs diff=lfs merge=lfs -text
|
| 48 |
+
*.bmp filter=lfs diff=lfs merge=lfs -text
|
| 49 |
+
*.svg filter=lfs diff=lfs merge=lfs -text
|
| 50 |
+
*.tiff filter=lfs diff=lfs merge=lfs -text
|
| 51 |
+
*.webp filter=lfs diff=lfs merge=lfs -text
|
| 52 |
+
# Specific files in assets directory
|
| 53 |
+
assets/drone_line_following_video.mp4 filter=lfs diff=lfs merge=lfs -text
|
| 54 |
+
assets/hand_control_arm_video.mp4 filter=lfs diff=lfs merge=lfs -text
|
| 55 |
+
assets/quickdraw_game_video.mp4 filter=lfs diff=lfs merge=lfs -text
|
| 56 |
+
assets/*.jpg filter=lfs diff=lfs merge=lfs -text
|
| 57 |
+
assets/*.jpeg filter=lfs diff=lfs merge=lfs -text
|
| 58 |
+
assets/*.png filter=lfs diff=lfs merge=lfs -text
|
| 59 |
+
assets/*.gif filter=lfs diff=lfs merge=lfs -text
|
.gitignore
ADDED
|
@@ -0,0 +1,8 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
.vscode/
|
| 2 |
+
.streamlit/secrets.toml
|
| 3 |
+
__pycache__/
|
| 4 |
+
*.pyc
|
| 5 |
+
*.pyo
|
| 6 |
+
*.pyd
|
| 7 |
+
*.pyw
|
| 8 |
+
*.pyz
|
.streamlit/config.toml
ADDED
|
@@ -0,0 +1,15 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
[theme]
|
| 2 |
+
primaryColor = "#FF4B4B"
|
| 3 |
+
backgroundColor = "#FFFFFF"
|
| 4 |
+
secondaryBackgroundColor = "#F0F2F6"
|
| 5 |
+
textColor = "#262730"
|
| 6 |
+
font = "sans serif"
|
| 7 |
+
|
| 8 |
+
[server]
|
| 9 |
+
enableCORS = true
|
| 10 |
+
enableXsrfProtection = true
|
| 11 |
+
maxUploadSize = 200
|
| 12 |
+
maxMessageSize = 200
|
| 13 |
+
|
| 14 |
+
[browser]
|
| 15 |
+
gatherUsageStats = false
|
README.md
CHANGED
|
@@ -12,3 +12,91 @@ short_description: Computer Vision Hangout
|
|
| 12 |
---
|
| 13 |
|
| 14 |
Check out the configuration reference at https://huggingface.co/docs/hub/spaces-config-reference
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 12 |
---
|
| 13 |
|
| 14 |
Check out the configuration reference at https://huggingface.co/docs/hub/spaces-config-reference
|
| 15 |
+
|
| 16 |
+
# Computer Vision Journey - Interactive Streamlit Presentation
|
| 17 |
+
|
| 18 |
+
An interactive Streamlit presentation showcasing my journey in Computer Vision, from autonomous drones to Vision Language Models.
|
| 19 |
+
|
| 20 |
+
## Overview
|
| 21 |
+
|
| 22 |
+
This application serves as an interactive presentation for a Computer Vision Hangout on Hugging Face. Instead of traditional slides, I've created a modern, interactive Streamlit application that walks through my development in computer vision through various projects I've worked on over the years.
|
| 23 |
+
|
| 24 |
+
### Featured Projects
|
| 25 |
+
|
| 26 |
+
1. **Black Bee Drones** - First autonomous drone team in Latin America
|
| 27 |
+
- Line following algorithms
|
| 28 |
+
- ArUco marker detection
|
| 29 |
+
- Real-time control systems
|
| 30 |
+
|
| 31 |
+
2. **Asimov Foundation** - STEM education through robotics and computer vision
|
| 32 |
+
- Hand gesture recognition for robotic arm control
|
| 33 |
+
- Educational tools for teaching CV concepts
|
| 34 |
+
|
| 35 |
+
3. **CafeDL** - A Java Deep Learning library built from scratch
|
| 36 |
+
- CNN architecture implementation
|
| 37 |
+
- Real-time drawing classification
|
| 38 |
+
- QuickDraw game clone
|
| 39 |
+
|
| 40 |
+
4. **Tech4Humans ML Projects** - Industry applications
|
| 41 |
+
- Signature Detection Model (open-source)
|
| 42 |
+
- Document Information Extraction using VLMs
|
| 43 |
+
|
| 44 |
+
## Live Demos
|
| 45 |
+
|
| 46 |
+
The presentation includes links to several live demos on Hugging Face Spaces:
|
| 47 |
+
|
| 48 |
+
- [OpenCV GUI Demo](https://samuellimabraz-opencv-gui.hf.space)
|
| 49 |
+
- [Line Following PID Demo](https://samuellimabraz-line-follow-pid.hf.space)
|
| 50 |
+
- [Signature Detection Demo](https://tech4humans-signature-detection.hf.space)
|
| 51 |
+
|
| 52 |
+
## Installation and Running
|
| 53 |
+
|
| 54 |
+
### Requirements
|
| 55 |
+
|
| 56 |
+
- Python 3.8+
|
| 57 |
+
- Streamlit 1.33.0+
|
| 58 |
+
- Other dependencies listed in `requirements.txt`
|
| 59 |
+
|
| 60 |
+
### Setup
|
| 61 |
+
|
| 62 |
+
1. Clone this repository:
|
| 63 |
+
```bash
|
| 64 |
+
git clone https://github.com/samuellimabraz/cv-journey-presentation.git
|
| 65 |
+
cd cv-journey-presentation
|
| 66 |
+
```
|
| 67 |
+
|
| 68 |
+
2. Install the required packages:
|
| 69 |
+
```bash
|
| 70 |
+
pip install -r requirements.txt
|
| 71 |
+
```
|
| 72 |
+
|
| 73 |
+
3. Run the Streamlit application:
|
| 74 |
+
```bash
|
| 75 |
+
streamlit run app.py
|
| 76 |
+
```
|
| 77 |
+
|
| 78 |
+
## Project Structure
|
| 79 |
+
|
| 80 |
+
- `app.py` - Main entry point for the Streamlit application
|
| 81 |
+
- `pages/` - Individual page modules for each section of the presentation
|
| 82 |
+
- `assets/` - Images, videos, and other static assets
|
| 83 |
+
- `utils/` - Helper functions and utilities
|
| 84 |
+
|
| 85 |
+
## Contributing
|
| 86 |
+
|
| 87 |
+
This is a personal presentation project, but feedback and suggestions are welcome. Feel free to open an issue or contact me directly.
|
| 88 |
+
|
| 89 |
+
## License
|
| 90 |
+
|
| 91 |
+
This project is licensed under the MIT License - see the LICENSE file for details.
|
| 92 |
+
|
| 93 |
+
## Acknowledgments
|
| 94 |
+
|
| 95 |
+
- Black Bee Drones team at UNIFEI
|
| 96 |
+
- Asimov Foundation
|
| 97 |
+
- Tech4Humans team
|
| 98 |
+
- Hugging Face community for hosting the Computer Vision Hangout
|
| 99 |
+
|
| 100 |
+
## Contact
|
| 101 |
+
|
| 102 |
+
Samuel Lima Braz - [GitHub](https://github.com/samuellimabraz) | [LinkedIn](https://www.linkedin.com/) | [Hugging Face](https://huggingface.co/samuellimabraz)
|
app.py
ADDED
|
@@ -0,0 +1,176 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import streamlit as st
|
| 2 |
+
from streamlit_extras.switch_page_button import switch_page
|
| 3 |
+
import os
|
| 4 |
+
import sys
|
| 5 |
+
|
| 6 |
+
# Add the project root to the path
|
| 7 |
+
sys.path.append(os.path.dirname(os.path.abspath(__file__)))
|
| 8 |
+
|
| 9 |
+
# Set page configuration
|
| 10 |
+
st.set_page_config(
|
| 11 |
+
page_title="Samuel Lima Braz | CV Journey",
|
| 12 |
+
page_icon="🧠",
|
| 13 |
+
layout="wide",
|
| 14 |
+
initial_sidebar_state="expanded",
|
| 15 |
+
)
|
| 16 |
+
|
| 17 |
+
# Custom CSS for better styling
|
| 18 |
+
st.markdown(
|
| 19 |
+
"""
|
| 20 |
+
<style>
|
| 21 |
+
.main .block-container {
|
| 22 |
+
padding-top: 2rem;
|
| 23 |
+
}
|
| 24 |
+
h1, h2, h3 {
|
| 25 |
+
margin-top: 0;
|
| 26 |
+
}
|
| 27 |
+
.stTabs [data-baseweb="tab-list"] {
|
| 28 |
+
gap: 2rem;
|
| 29 |
+
}
|
| 30 |
+
.stTabs [data-baseweb="tab"] {
|
| 31 |
+
height: 4rem;
|
| 32 |
+
white-space: pre-wrap;
|
| 33 |
+
background-color: transparent;
|
| 34 |
+
border-radius: 4px 4px 0 0;
|
| 35 |
+
gap: 1rem;
|
| 36 |
+
padding-top: 1rem;
|
| 37 |
+
padding-bottom: 1rem;
|
| 38 |
+
}
|
| 39 |
+
a {
|
| 40 |
+
text-decoration: none;
|
| 41 |
+
}
|
| 42 |
+
.badge {
|
| 43 |
+
display: inline-block;
|
| 44 |
+
padding: 0.25em 0.4em;
|
| 45 |
+
font-size: 75%;
|
| 46 |
+
font-weight: 700;
|
| 47 |
+
line-height: 1;
|
| 48 |
+
text-align: center;
|
| 49 |
+
white-space: nowrap;
|
| 50 |
+
vertical-align: baseline;
|
| 51 |
+
border-radius: 0.25rem;
|
| 52 |
+
margin-right: 0.5rem;
|
| 53 |
+
margin-bottom: 0.5rem;
|
| 54 |
+
}
|
| 55 |
+
.badge-primary {
|
| 56 |
+
color: #fff;
|
| 57 |
+
background-color: #007bff;
|
| 58 |
+
}
|
| 59 |
+
.badge-secondary {
|
| 60 |
+
color: #fff;
|
| 61 |
+
background-color: #6c757d;
|
| 62 |
+
}
|
| 63 |
+
.badge-success {
|
| 64 |
+
color: #fff;
|
| 65 |
+
background-color: #28a745;
|
| 66 |
+
}
|
| 67 |
+
.badge-info {
|
| 68 |
+
color: #fff;
|
| 69 |
+
background-color: #17a2b8;
|
| 70 |
+
}
|
| 71 |
+
.tech-list {
|
| 72 |
+
list-style-type: none;
|
| 73 |
+
padding-left: 0;
|
| 74 |
+
}
|
| 75 |
+
.tech-list li {
|
| 76 |
+
margin-bottom: 0.5rem;
|
| 77 |
+
}
|
| 78 |
+
.tech-list li::before {
|
| 79 |
+
content: "•";
|
| 80 |
+
color: #ff4b4b;
|
| 81 |
+
font-weight: bold;
|
| 82 |
+
display: inline-block;
|
| 83 |
+
width: 1em;
|
| 84 |
+
margin-left: -1em;
|
| 85 |
+
}
|
| 86 |
+
</style>
|
| 87 |
+
""",
|
| 88 |
+
unsafe_allow_html=True,
|
| 89 |
+
)
|
| 90 |
+
|
| 91 |
+
# Title and introduction
|
| 92 |
+
st.title("My Computer Vision Journey")
|
| 93 |
+
st.subheader("Presented by Samuel Lima Braz")
|
| 94 |
+
|
| 95 |
+
# Profile image - create a column layout
|
| 96 |
+
col1, col2 = st.columns([1, 3])
|
| 97 |
+
|
| 98 |
+
with col1:
|
| 99 |
+
st.image("assets/profile.jpg", width=200)
|
| 100 |
+
|
| 101 |
+
with col2:
|
| 102 |
+
st.markdown(
|
| 103 |
+
"""
|
| 104 |
+
Hi, I'm **Samuel Lima Braz**, a Computer Engineering student at UNIFEI (Universidade Federal de Itajubá)
|
| 105 |
+
and Machine Learning Engineer at Tech4Humans in Brazil.
|
| 106 |
+
|
| 107 |
+
My programming journey began in 2018 with C during my technical course in Industrial Automation.
|
| 108 |
+
I entered the world of Computer Vision in 2023 when I joined Black Bee Drones, the first autonomous
|
| 109 |
+
drone team in Latin America, where I continue to develop cutting-edge solutions for autonomous flight.
|
| 110 |
+
"""
|
| 111 |
+
)
|
| 112 |
+
|
| 113 |
+
st.markdown("---")
|
| 114 |
+
|
| 115 |
+
st.markdown("#### Presentation Goal:")
|
| 116 |
+
st.markdown(
|
| 117 |
+
"""
|
| 118 |
+
This interactive presentation, built entirely with Streamlit, walks you through my key projects in Computer Vision,
|
| 119 |
+
from autonomous drones to fine-tuning Vision Language Models. We'll explore concepts, challenges, and see some live demos along the way!
|
| 120 |
+
"""
|
| 121 |
+
)
|
| 122 |
+
|
| 123 |
+
# Navigation section
|
| 124 |
+
st.markdown("### Navigate Through My Journey")
|
| 125 |
+
|
| 126 |
+
col1, col2, col3 = st.columns(3)
|
| 127 |
+
|
| 128 |
+
with col1:
|
| 129 |
+
black_bee_btn = st.button("🐝 Black Bee Drones", use_container_width=True)
|
| 130 |
+
if black_bee_btn:
|
| 131 |
+
switch_page("black_bee_drones")
|
| 132 |
+
|
| 133 |
+
cafe_dl_btn = st.button("☕ CafeDL Project", use_container_width=True)
|
| 134 |
+
if cafe_dl_btn:
|
| 135 |
+
switch_page("cafe_dl")
|
| 136 |
+
|
| 137 |
+
with col2:
|
| 138 |
+
asimov_btn = st.button("🤖 Asimo Foundation", use_container_width=True)
|
| 139 |
+
if asimov_btn:
|
| 140 |
+
switch_page("asimo_foundation")
|
| 141 |
+
|
| 142 |
+
tech4humans_btn = st.button("💼 Tech4Humans", use_container_width=True)
|
| 143 |
+
if tech4humans_btn:
|
| 144 |
+
switch_page("tech4humans")
|
| 145 |
+
|
| 146 |
+
with col3:
|
| 147 |
+
conclusion_btn = st.button("✅ Conclusion", use_container_width=True)
|
| 148 |
+
if conclusion_btn:
|
| 149 |
+
switch_page("conclusion")
|
| 150 |
+
|
| 151 |
+
|
| 152 |
+
# Add information about this presentation
|
| 153 |
+
st.sidebar.markdown("## About This Presentation")
|
| 154 |
+
st.sidebar.markdown(
|
| 155 |
+
"""
|
| 156 |
+
This interactive presentation was built with Streamlit as an alternative to traditional slides.
|
| 157 |
+
|
| 158 |
+
Navigate through the sections using the buttons above or the pages in the sidebar.
|
| 159 |
+
|
| 160 |
+
Each section includes:
|
| 161 |
+
- Project description
|
| 162 |
+
- Technologies used
|
| 163 |
+
- Interactive demos (where applicable)
|
| 164 |
+
- Code examples & visualizations
|
| 165 |
+
"""
|
| 166 |
+
)
|
| 167 |
+
|
| 168 |
+
# Add contact information in the sidebar
|
| 169 |
+
st.sidebar.markdown("## Connect With Me")
|
| 170 |
+
st.sidebar.markdown(
|
| 171 |
+
"""
|
| 172 |
+
- [GitHub](https://github.com/samuellimabraz)
|
| 173 |
+
- [LinkedIn](https://www.linkedin.com/in/samuel-lima-braz/)
|
| 174 |
+
- [Hugging Face](https://huggingface.co/samuellimabraz)
|
| 175 |
+
"""
|
| 176 |
+
)
|
assets/.gitkeep
ADDED
|
@@ -0,0 +1,12 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# This file ensures that the assets directory is tracked by git even if it is empty.
|
| 2 |
+
# You should place the following files in this directory:
|
| 3 |
+
#
|
| 4 |
+
# - profile.jpg: A profile picture for the intro page
|
| 5 |
+
# - imav_mission_diagram.jpg: A diagram of the IMAV 2023 Indoor Mission
|
| 6 |
+
# - drone_line_following_video.mp4: Video of the drone following a line during IMAV 2023
|
| 7 |
+
# - gesture_control.jpg: Image showing hand gesture detection for drone control
|
| 8 |
+
# - aruco_navigation.jpg: Image showing ArUco marker detection for positioning
|
| 9 |
+
# - robotic_arm.jpg: Image of the robotic arm used in the Asimov Foundation project
|
| 10 |
+
# - hand_control_arm_video.mp4: Demo video of hand gesture controlling a robotic arm
|
| 11 |
+
# - quickdraw_game_video.mp4: Demo video of the QuickDraw game using CafeDL
|
| 12 |
+
# - signature_detection.jpg: Example image of signature detection on a document
|
assets/[Samuel] Fine-tuning Structured OCR.md
ADDED
|
@@ -0,0 +1,350 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Fine-tuning Structured OCR
|
| 2 |
+
|
| 3 |
+
por **Samuel Lima Braz** em **27/02/2025**
|
| 4 |
+
|
| 5 |
+
# Atividades
|
| 6 |
+
|
| 7 |
+
- Refinamento do dataset
|
| 8 |
+
- Avaliação de modelo Open Source com vllm
|
| 9 |
+
- Ajuste Fino
|
| 10 |
+
- Unsloth
|
| 11 |
+
- Swift
|
| 12 |
+
- Avaliação de Generalização de documentos
|
| 13 |
+
|
| 14 |
+
## Introdução
|
| 15 |
+
|
| 16 |
+
Iniciei o desenvolvimento dos experimentos no cenário de fine-tuning de modelos multimodais para a extração de dados. O objetivo não é construir um modelo geral que substitua nossa solução atual, mas sim validar a capacidade de modelos menores nesse campo e nossa competência em treiná-los e implantá-los. Já havia iniciado a preparação do dataset e, agora, refinei os dados, defini métricas e estabeleci métodos para avaliar os modelos open-source de forma eficiente, realizando o fine-tuning de determinados modelos e comparando os resultados entre as versões pré-treinadas e ajustadas.
|
| 17 |
+
|
| 18 |
+
## Dataset
|
| 19 |
+
|
| 20 |
+
Anteriormente, criei um dataset com amostras de CNH, RG e Notas Fiscais a partir de dados públicos, utilizando um processo de estruturação dos dados extraídos por LLM. Contudo, durante o desenvolvimento do processo de avaliação, percebi diversas inconsistências nas anotações, falhas nas associações dos campos, despadronização dos dados extraídos e até algumas imagens invertidas.
|
| 21 |
+
|
| 22 |
+
Para solucionar esses problemas, realizei uma seleção manual de 170 exemplos de CNH e 170 exemplos de RG, refazendo as anotações e revisando as imagens consideradas adequadas para a extração. No caso das Notas Fiscais, as anotações já estavam adequadas, tendo sido feita apenas a seleção das amostras com boa qualidade de imagem.
|
| 23 |
+
|
| 24 |
+
Posteriormente, dividi o dataset em 70% para treino, 15% para teste e 15% para validação, mantendo uma proporção igualitária de cada tipo de documento em cada divisão. Além disso, utilizando a ferramenta de augmentations em imagens do Roboflow, gerei três vezes mais dados de treino aplicando transformações nas imagens.
|
| 25 |
+
|
| 26 |
+
![][image1]
|
| 27 |
+
|
| 28 |
+
[Brazilian Document Extration Multimodal Dataset by tech](https://universe.roboflow.com/tech-ysdkk/brazilian-document-extration)
|
| 29 |
+
|
| 30 |
+
### Pré-Processamento
|
| 31 |
+
|
| 32 |
+
Preparando os dados para a avaliação e treinamento.
|
| 33 |
+
|
| 34 |
+
- Formatação
|
| 35 |
+
|
| 36 |
+
```py
|
| 37 |
+
SYSTEM_MESSAGE = """
|
| 38 |
+
Parse the provided image of a document and extract the relevant information in a well-structured JSON format that the user will provide.
|
| 39 |
+
- If data is not available in OCR, leave the field empty in the JSON.
|
| 40 |
+
- Do not include authorities and type in the final response.
|
| 41 |
+
- Respond only the final JSON. Avoid additional explanations or comments.
|
| 42 |
+
Fill the following json schema:
|
| 43 |
+
"""
|
| 44 |
+
|
| 45 |
+
def format_conversation(
|
| 46 |
+
image: str | bytes | Image.Image, prefix: str, suffix: str | None = None, system_message: str | None = None
|
| 47 |
+
) -> list[dict]:
|
| 48 |
+
messages = []
|
| 49 |
+
|
| 50 |
+
if system_message is not None:
|
| 51 |
+
messages.append(
|
| 52 |
+
{
|
| 53 |
+
"role": "system",
|
| 54 |
+
"content": [{"type": "text", "text": system_message}],
|
| 55 |
+
}
|
| 56 |
+
)
|
| 57 |
+
|
| 58 |
+
messages.append(
|
| 59 |
+
{
|
| 60 |
+
"role": "user",
|
| 61 |
+
"content": [
|
| 62 |
+
{"type": "text", "text": prefix},
|
| 63 |
+
{"type": "image", "image": image},
|
| 64 |
+
],
|
| 65 |
+
}
|
| 66 |
+
)
|
| 67 |
+
|
| 68 |
+
if suffix is not None:
|
| 69 |
+
messages.append(
|
| 70 |
+
{
|
| 71 |
+
"role": "assistant",
|
| 72 |
+
"content": [{"type": "text", "text": suffix}],
|
| 73 |
+
}
|
| 74 |
+
)
|
| 75 |
+
|
| 76 |
+
return { "messages" : messages }
|
| 77 |
+
```
|
| 78 |
+
|
| 79 |
+
Preparei os dados para a avaliação e o treinamento. Após carregar o dataset do Roboflow e transformá-lo em um Dataset do PyTorch, criei um pipeline de transformações semelhante às aplicadas na API de extração de documentos. Neste pipeline, apliquei um resize para um máximo de (640, 640), mantendo o aspect ratio das imagens. Explorei técnicas como auto-orientação, CLAHE, Sharpen, entre outras testadas na avaliação da Mirela, e identifiquei algumas combinações funcionais. Contudo, optei inicialmente por aplicar somente o resize, pois ainda não estava claro como as demais transformações afetariam o desempenho do treinamento, além de alguns modelos (como o deepseek-vl2) não aceitarem entradas em grayscale, o que poderia gerar viés para modelos treinados com conjuntos de imagens em formatos diferentes.
|
| 80 |
+
|
| 81 |
+
## Avaliação
|
| 82 |
+
|
| 83 |
+
### Arquiteturas
|
| 84 |
+
|
| 85 |
+
Primeiro analisei os principais benchmarks de modelos de vision com foco nas métricas de dataset generalistas em extração de dados como OCRBench e OCR-VQA ([https://huggingface.co/spaces/opencompass/open\_vlm\_leaderboard](https://huggingface.co/spaces/opencompass/open_vlm_leaderboard)). Em resumo as principais arquiteturas com tamanhos entre 1B há 10B (uma média de tamanho acessível para uma GPU L4), com as melhores métricas em extração de dados são
|
| 86 |
+
|
| 87 |
+
- Qwen (2, 2.5)-VL
|
| 88 |
+
- InterVL2.5
|
| 89 |
+
- Ovis2
|
| 90 |
+
- MiniCPM-o-2.6
|
| 91 |
+
- deepseek-vl2
|
| 92 |
+
- h20-vl
|
| 93 |
+
- phi-3.5-vision
|
| 94 |
+
- moondream
|
| 95 |
+
- SmolVLM
|
| 96 |
+
- MiniMonkey
|
| 97 |
+
|
| 98 |
+
### vLLM
|
| 99 |
+
|
| 100 |
+
Para facilitar o sistema de inferência entre os diferentes modelos de vision optei por utilizar uma ferramenta de inferência, ao invés de utilizar a lib transformers diretamente, melhorando também o tempo de inferência com as otimizações que elas trazem. Avaliei as ferramentas lmdeploy, ollama, tri, llama.cpp e vllm, e dentre eles o vllm possui o maior nível de suporte a modelos de vision, além de ser simples de utilizar de forma “offline” sem a necessidade de servir o modelo e sim utilizá-lo diretamente na GPU do ambiente do colab.
|
| 101 |
+
|
| 102 |
+
Mas ainda assim fiz uma estrutura que me permitisse usar modelos através do transformers, vllm ou via litellm, mantendo o mesmo padrão para avaliação.
|
| 103 |
+
|
| 104 |
+
Um dos desafios com os modelos de vision são as variações no pré-processamento de como é aplicado o tokenizer e/ou o processor, a compatibilidade entre versões do transformers e a própria classe de modelo. Então quando iniciei o desenvolvimento percebi que teria que escrever e testar códigos diferentes para cada arquitetura, o que é normal e interessante para estudar uma arquitetura, porém deixaria meu desenvolvimento mais lento.
|
| 105 |
+
|
| 106 |
+
Além disso, o vllm fornece a funcionalidade de saída estruturada, por meio das ferramentas [outlines](https://github.com/dottxt-ai/outlines), [lm-format-enforcer](https://github.com/noamgat/lm-format-enforcer), or [xgrammar](https://github.com/mlc-ai/xgrammar). Há um artigo do prórpiro vLLM que é muito bacana e explica como funciona essas ferramentas e uma comparação de desempenho entre elas e como elas estão arquitetadas na versão atual do projeto deles: [Structured Decoding in vLLM: a gentle introduction](https://blog.vllm.ai/2025/01/14/struct-decode-intro.html)
|
| 107 |
+
|
| 108 |
+
* Pretendo trazer uma escrita sobre o tema, porém não tive o devido tempo para isso.
|
| 109 |
+
|
| 110 |
+
### Projeto
|
| 111 |
+
|
| 112 |
+
Esse é o projeto que fiz para realizar inferência via transformers, vllm e litellm seguindo o mesmo padrão de geração
|
| 113 |
+
|
| 114 |
+
![][image2]
|
| 115 |
+
|
| 116 |
+
Link para o diagrama: [https://www.mermaidchart.com/app/projects/54b59dc6-881e-4e56-88a2-e5571cdb40e1/diagrams/acaa69c6-d3e5-4edf-9c88-c4db6a242025/version/v0.1/edit](https://www.mermaidchart.com/app/projects/54b59dc6-881e-4e56-88a2-e5571cdb40e1/diagrams/acaa69c6-d3e5-4edf-9c88-c4db6a242025/version/v0.1/edit)
|
| 117 |
+
|
| 118 |
+
### Métricas
|
| 119 |
+
|
| 120 |
+
Para metrificar o desempenho dos modelos criei uma serie de funções em python para calcular o match ou a similaridade entre campos do json de ground trut, normalizando os valores para que não seja considerado pontuações, espaços, variações de indicações do vazio (ex. “null”, “n/a” …), variações na formatação de data ("%Y-%m-%d", "%d/%m/%Y", "%m-%d-%Y", "%d-%m-%Y"), aproximações de valores numéricos, letras maiúsculas e minúsculas, remoção de caracteres especiais …
|
| 121 |
+
|
| 122 |
+
O processo irá avaliar um match exato, ou então calcular a similaridade entre as strings utilizando da ferramenta rapidfuzz que calcula a similaridade entre duas strings utilizando uma métrica baseada na distância de edição do tipo Indel, que, em essência, é uma variação da distância de Levenshtein que considera inserções e deleções.
|
| 123 |
+
Ela determina o número mínimo de operações necessárias (inserções e deleções) para transformar uma string na outra. Esse número é a "distância" entre as duas strings. Para transformar esse valor em uma medida de similaridade, a distância é normalizada em relação à soma dos comprimentos das duas strings. A fórmula é dada por:
|
| 124 |
+
similaridade \= (1 \- (distância / (len(s1) \+ len(s2)))) \* 100
|
| 125 |
+
Assim, o resultado é um número entre 0 e 100, onde 100 indica que as strings são idênticas e 0 que são completamente diferentes.
|
| 126 |
+
|
| 127 |
+
De forma exemplificada ela atua dessa forma:
|
| 128 |
+
|
| 129 |
+
```py
|
| 130 |
+
predicted = {"date": "2018-07-11", "company": {"name": "Empresa XYZ", "ti": "123"}, "cpf": ""}
|
| 131 |
+
ground_truth = {"date": "11/07/2018", "company": {"name":"epresa xyz", "ti": "12"}, "cpf": ""}
|
| 132 |
+
calculate_metrics(predicted, ground_truth, "nota")
|
| 133 |
+
|
| 134 |
+
{
|
| 135 |
+
'exact_match': 0,
|
| 136 |
+
'field_accuracy': {
|
| 137 |
+
'date': 1.0,
|
| 138 |
+
'company.name': 0.9523809523809522,
|
| 139 |
+
'company.ti': 0.8888888888888888,
|
| 140 |
+
'cpf': 1.0
|
| 141 |
+
},
|
| 142 |
+
'type': 'nota',
|
| 143 |
+
'missing_fields': [],
|
| 144 |
+
'incorrect_fields': [],
|
| 145 |
+
'overall_accuracy': 0.9603174603174602,
|
| 146 |
+
'field_coverage': 1.0
|
| 147 |
+
}
|
| 148 |
+
```
|
| 149 |
+
|
| 150 |
+
|
| 151 |
+
Também desenvolvi uma série de funções para gerar visualizações dos resultados contendo a imagem, label e predição e permitindo salvar isso em arquivo xlsx e também construir alguns relatórios e plots dinâmicos com plotly.
|
| 152 |
+
|
| 153 |
+
### Resultados
|
| 154 |
+
|
| 155 |
+
![][image3]
|
| 156 |
+
|
| 157 |
+
![][image4]
|
| 158 |
+
|
| 159 |
+
#### Desempenho de Acurácia
|
| 160 |
+
|
| 161 |
+
- **InternVL2\_5-1B e InternVL2\_5-1B-MPO (≈0,94B):**
|
| 162 |
+
|
| 163 |
+
- **CNH:** Estes modelos apresentam uma acurácia relativamente melhor na classe CNH, chegando a 61–63%, o que indica uma boa capacidade de extrair dados desse tipo de documento.
|
| 164 |
+
- **Geral e RG:** As acurácias gerais ficam em torno de 54–57%, com desempenho estável, embora não se destaquem nas demais categorias.
|
| 165 |
+
- **NF:** A acurácia na categoria NF é a mais baixa (cerca de 44%), sinalizando maior dificuldade nessa classe.
|
| 166 |
+
|
| 167 |
+
|
| 168 |
+
- **InternVL2\_5-2B-MPO (2,21B):**
|
| 169 |
+
|
| 170 |
+
- Apesar de ser o dobro em termos de parâmetros em relação aos modelos de 1B, observa-se uma queda significativa na acurácia geral (41%) e, especialmente, na categoria NF (apenas 21,85%).
|
| 171 |
+
- Esse comportamento pode indicar que o aumento de parâmetros não necessariamente se traduz em melhor desempenho se outros fatores (como treinamento ou arquitetura específica) não forem otimizados.
|
| 172 |
+
|
| 173 |
+
|
| 174 |
+
- **Qwen2-VL-2B-Instruct (2,21B):**
|
| 175 |
+
|
| 176 |
+
- Apresenta uma acurácia geral um pouco superior (55,23%) e se destaca na categoria RG (66,16%), embora na CNH a performance caia para cerca de 55%.
|
| 177 |
+
- Isso sugere que, para documentos do tipo RG, esse modelo pode ser mais eficaz, mesmo que o ganho não seja uniforme entre todas as classes.
|
| 178 |
+
|
| 179 |
+
|
| 180 |
+
- **h2ovl-mississippi-2b (2,15B):**
|
| 181 |
+
|
| 182 |
+
- Com resultados próximos dos 2B, a acurácia geral (53,43%) e na classe CNH (52,92%) é similar ou um pouco inferior, mas o desempenho em RG (67,54%) indica que pode ser competitivo em categorias específicas.
|
| 183 |
+
- A classe NF fica em torno de 39,81%, também apontando desafios nesse tipo de documento.
|
| 184 |
+
|
| 185 |
+
|
| 186 |
+
- **llava-onevision-qwen2-0.5b-ov-hf (0,89B):**
|
| 187 |
+
|
| 188 |
+
- Entre os modelos menores, este se destaca negativamente, com acurácias baixas em todas as classes (por exemplo, 36,87% no geral e 28,70% em NF), sugerindo que a redução extrema no tamanho pode impactar a capacidade de extração de dados de forma crítica.
|
| 189 |
+
|
| 190 |
+
#### Tempo de Inferência
|
| 191 |
+
|
| 192 |
+
- **Modelos de 1B (InternVL2\_5-1B e InternVL2\_5-1B-MPO):**
|
| 193 |
+
|
| 194 |
+
- Apresentam os tempos de inferência mais rápidos (em média entre 1,33 e 1,54 segundos)
|
| 195 |
+
|
| 196 |
+
|
| 197 |
+
- **Modelos de \~2B (InternVL2\_5-2B-MPO, Qwen2-VL-2B-Instruct e h2ovl-mississippi-2b):**
|
| 198 |
+
|
| 199 |
+
- O InternVL2\_5-2B-MPO tem tempos de inferência um pouco maiores (em torno de 1,96 a 2,19 s), enquanto o Qwen2-VL-2B-Instruct fica entre 2,44 e 2,80 s.
|
| 200 |
+
- O h2ovl-mississippi-2b é ainda mais lento, com médias que chegam a 3,04–3,38 s, indicando um trade-off entre o tamanho e a velocidade.
|
| 201 |
+
|
| 202 |
+
|
| 203 |
+
- **llava-onevision-qwen2-0.5b-ov-hf:**
|
| 204 |
+
|
| 205 |
+
- Apesar de ser o menor em termos de parâmetros, seu tempo de inferência (aproximadamente 1,43–1,49 s) é competitivo, mas esse ganho de velocidade não compensa sua acurácia inferior.
|
| 206 |
+
|
| 207 |
+
|
| 208 |
+
Observamos aqui como uma ferramenta de inferência como o vLLM acelera significativamente a predição. Isso ainda com modelos de vision que demandam alto custo operacional devido ao processamento de imagens.
|
| 209 |
+
No meu primeiro caso da sumarização um dos pontos críticos era que mesmo alcançando boa acurácia com modelo pequenos servir ele parecia ter grandes desvantagens de latência.
|
| 210 |
+
De certa forma era uma comparação injusta, realizando a inferência utilizando puramente transformers na gpu do colab com uma api serveless onde as grandes empresas utilizam servidores com milhares de GPUs em paralelo e otimizadas para uma única tarefa.
|
| 211 |
+
Embora não consigamos alcançar os mesmos custos oferecidos por essas empresas, acredito que nossos modelos podem oferecer desempenhos suficientemente bons para validar a implantação de um modelo generativo próprio.
|
| 212 |
+
|
| 213 |
+
Estou iniciando um estudo mais profundo das otimizações e formas de servir modelos menores com eficiência.
|
| 214 |
+
|
| 215 |
+
### Destaques e Considerações
|
| 216 |
+
|
| 217 |
+
- **Trade-off entre Acurácia e Velocidade:**
|
| 218 |
+
|
| 219 |
+
- Os modelos de \~1B (InternVL2\_5-1B e sua variante MPO) demonstram que é possível obter uma inferência rápida sem perder muito em termos de acurácia, especialmente em CNH.
|
| 220 |
+
- Em contrapartida, os modelos de \~2B, como o Qwen2-VL-2B-Instruct, conseguem melhorar em algumas categorias (como RG), mas isso vem acompanhado de um aumento no tempo de processamento.
|
| 221 |
+
|
| 222 |
+
|
| 223 |
+
- **Impacto do Treinamento e Arquitetura:**
|
| 224 |
+
|
| 225 |
+
- O InternVL2\_5-2B-MPO ilustra que simplesmente aumentar o número de parâmetros não garante melhor desempenho; a metodologia de treinamento (como o uso de MPO) e a arquitetura empregada têm impacto direto nos resultados.
|
| 226 |
+
- Já o desempenho inferior do llava-onevision-qwen2-0.5b-ov-hf reforça que reduções extremas podem prejudicar a capacidade de generalização do modelo.
|
| 227 |
+
|
| 228 |
+
## Ajuste Fino
|
| 229 |
+
|
| 230 |
+
### Unsloth
|
| 231 |
+
|
| 232 |
+
Iniciei o processo de treinamento buscando utilizar a unsloth, que é uma ferramenta de otimização na ‘engine’ de treinamento atuando nos kernels e operações tensoriais, em que eu já havia explorado nas primeiras experimentações e já conhecia as dependências e forma de trabalho.
|
| 233 |
+
|
| 234 |
+
A unsloth iniciou o suporte a modelos de vision no final do ano passado e tem suporte para as arquiteturas llama-vision, qwen2 e qwen2\_5\*, pixtral e llava-v1.6.
|
| 235 |
+
|
| 236 |
+
Iniciei explorando o modelo mas recente qwen2\_5, e obtive bons comportamentos durante o treinamento, onde as perdas de treinamento e avaliação tiveram um decaimento de convergência, sem variações bruscas e a princípio nenhuma indicação de overfitting (“perda de treinamento muito abaixo da de avaliação”), e realizando a inferência utilizando o adaptador LoRA através da unsloth o modelo se comportava bem.
|
| 237 |
+
Porém ao realizar o merge do adaptador com o modelo base e realizar a inferência por meio do vLLM, o modelo gerava respostas completamente diferentes e incorretas.
|
| 238 |
+
|
| 239 |
+
O merge é o processo de juntar os novos pesos do adaptador criado com o modelo base.
|
| 240 |
+
|
| 241 |
+
* Atualmente o vLLM suporta servidores “Multi-Lora”, que é a ideia de ter os adaptadores “in-fly”, e o adaptador a ser utilizado se torna um parâmetro na requisição de inferência, assim é servido apenas um modelo base e múltiplos adaptadores para diferentes tarefas podem atuar na hora da inferência. Isso adiciona um pouco de latência, mas apresenta grandes economias ao implantar um modelo e ganha versatilidade.
|
| 242 |
+
* Atualmente ele só suporta adaptador de backbone de linguagem, ou seja apenas adaptadores que vieram do ajuste das camadas de linguagem, não suportando adaptações na camadas de visão. Nesse caso é preciso realizar o merge
|
| 243 |
+
|
| 244 |
+
|
| 245 |
+
Depois de alguns testes e interações com a comunidade do discord da unsloth e do hugginface, cheguei a conclusão de que a arquitetura 2.5 ainda não está 100% validada na unsloth.
|
| 246 |
+
|
| 247 |
+
No entanto, a arquitetura Qwen2-VL funciona muito bem e consegui fazer o ajuste das versões 2B e 7B.
|
| 248 |
+
|
| 249 |
+
### Swift
|
| 250 |
+
|
| 251 |
+
Visando acelerar o processo de finetuning, decide explorar alguns frameworks de treinamento. Eu havia avaliado alguns na minha primeira experimentação na tech, mas decidi criar o código passo a passo com as libs transformers, peft e trl que são a base da grande maioria dos frameworks para eu entender todo o processo. Agora que eu sou capaz de ler e compreender o código por trás das ferramentas achei ser benéfico utilizar uma ferramenta mais alto nível, principalmente no caso de multimodais que eu não tenho tanta experiência e não faria nenhuma alteração muito específica e assim fazendo basicamente um over engineering e copiando códigos das próprias ferramentas e tutoriais.
|
| 252 |
+
|
| 253 |
+
Analisando frameworks como LlamaFactory, axoltl, auto-train, adapters e ms-swift, me preocupei com as arquiteturas suportadas, métodos de treinamento, otimizações de memória e facilidade de uso. Decidi utilizar a ferramenta do Model Scope denominada [SWIFT](https://github.com/modelscope/ms-swift). Este é um framework recente lançado no final de 2023, desenvolvido pela equipe do [ModelScope](https://github.com/modelscope/modelscope), vinculada ao Alibaba Group. Ela não tem tanta notoriedade por ser um software “chinês”, e sem muita divulgação, porém a estrutura planejada por eles e os níveis de integrações com os diferentes tipos de tarefas e arquiteturas e métodos de ajuste são superiores em relação aos outros frameworks. Há um paper dos desenvolvedores onde explicam a arquitetura planejada e se comparam com essas outras ferramentas: [\[2408.05517\] SWIFT:A Scalable lightWeight Infrastructure for Fine-Tuning](https://arxiv.org/abs/2408.05517)
|
| 254 |
+
|
| 255 |
+
![][image5]
|
| 256 |
+
|
| 257 |
+
### Resultados
|
| 258 |
+
|
| 259 |
+
Não vou me estender aqui a problemas e experimentos de teste, até por terem ocorrido muitos, dessa vez consegui recorrer a ajudas externas nas comunidades e grupos de ML Open Source onde fui resolvendo erros e comportamentos inadequados com cada arquitetura que fui treinar.
|
| 260 |
+
|
| 261 |
+
Em resumo, realizei o ajuste das arquiteturas
|
| 262 |
+
|
| 263 |
+
- Unsloth
|
| 264 |
+
- Qwen2-VL 2B e 7B
|
| 265 |
+
- SWIFT
|
| 266 |
+
- Qwe2.5-VL 3B
|
| 267 |
+
- InternVL-2\_5-MPO 1B e 4B
|
| 268 |
+
- DeepSeek-VL2
|
| 269 |
+
|
| 270 |
+
* *Tabela comparativa entre todos os modelos*
|
| 271 |
+
|
| 272 |
+
![][image6]
|
| 273 |
+
|
| 274 |
+
* Gráfico Scatter Acurácia x Tempo de Inferência x N° Parâmetros
|
| 275 |
+
|
| 276 |
+
![][image7]
|
| 277 |
+
|
| 278 |
+
* Tabela em Heatmap
|
| 279 |
+
|
| 280 |
+
![][image8]
|
| 281 |
+
|
| 282 |
+
Todos os resultados estão registrados nesta planilha: [Doc Extraction Evaluation - Open Models](https://docs.google.com/spreadsheets/d/1RCB5fCGZSwhVCB9YgLWpeEUkzBovz9Ni26HysnX13qY/edit?gid=1949031965#gid=1949031965)
|
| 283 |
+
Contém cada resultado de inferência para cada modelo e uma página que compila todos os resultados.
|
| 284 |
+
|
| 285 |
+
Os registros das experimentações podem ser encontrados no MLFlow: [https://mlflow.tech4.ai/\#/experiments/251?searchFilter=\&orderByKey=attributes.start\_time\&orderByAsc=false\&startTime=ALL\&lifecycleFilter=Active\&modelVersionFilter=All+Runs\&datasetsFilter=W10%3D](https://mlflow.tech4.ai/#/experiments/251?searchFilter=&orderByKey=attributes.start_time&orderByAsc=false&startTime=ALL&lifecycleFilter=Active&modelVersionFilter=All+Runs&datasetsFilter=W10%3D)
|
| 286 |
+
|
| 287 |
+
E também no Weights & Biases: [https://wandb.ai/samuel-lima-tech4humans/ocr-finetuning-v2?nw=nwusersamuellima](https://wandb.ai/samuel-lima-tech4humans/ocr-finetuning-v2?nw=nwusersamuellima)
|
| 288 |
+
|
| 289 |
+
- Realizei os registros também no wandb para o caso de se tornar registros open source, há maneiras de compartilhar relatórios e métricas de forma segura
|
| 290 |
+
|
| 291 |
+
Os modelos com ajuste fino (-tuned) demonstram ganhos expressivos em acurácia e eficiência, mesmo em tamanhos reduzidos. Abaixo, a análise detalhada por faixa de parâmetros:
|
| 292 |
+
|
| 293 |
+
#### Modelos Pequenos (1B–3B)
|
| 294 |
+
|
| 295 |
+
| Modelo | Parâmetros (B) | Δ Acurácia Geral | Acurácia Geral (%) |
|
| 296 |
+
| :---- | :---- | :---- | :---- |
|
| 297 |
+
| **InternVL2\_5-1B-MPO-tuned** | 0.94 | **\+28.24%** | 54.76 → **83.00** |
|
| 298 |
+
| **Qwen2-VL-2B-Instruct-tuned** | 2.21 | **\+22.38%** | 55.23 → **77.61** |
|
| 299 |
+
| **deepseek-vl2-tiny-tuned** | 3.37 | **\+28.34%** | 50.47 → **78.81** |
|
| 300 |
+
|
| 301 |
+
- **M**elhorias acima de **20%** em todos os casos, com destaque para o **InternVL2\_5-1B-MPO-tuned** (83% de acurácia geral), superando modelos base de até **8B** (ex: MiniCPM-8.67B, 58.14%).
|
| 302 |
+
- **Capacidade em Tarefas Complexas**: Acurácia em Nota Fiscal (NF) do InternVL2\_5-1B-MPO-tuned salta de **44,60% → 73,24%**, aproximando-se de modelos grandes não ajustados (ex: Ovis2-4B: 58,70%).
|
| 303 |
+
|
| 304 |
+
#### Modelos Médios (4B+):
|
| 305 |
+
|
| 306 |
+
| Modelo | Parâmetros (B) | Δ Acurácia Geral | Acurácia Geral (%) |
|
| 307 |
+
| :---- | :---- | :---- | :---- |
|
| 308 |
+
| **InternVL2\_5-4B-MPO-tuned** | 3.71 | **\+18.39%** | 68.36 → **86.75** |
|
| 309 |
+
| **Qwen2.5-VL-3B-Instruct-tuned** | 3.75 | **\+17.63%** | 62.04 → **79.67** |
|
| 310 |
+
|
| 311 |
+
- O **InternVL2\_5-4B-MPO-tuned** atinge **93,95% em CNH** e **89,50% em RG**.
|
| 312 |
+
- Supera modelos não ajustados de 7B-8B (ex: Qwen2.5-VL-7B: 68,29%) com **40% menos parâmetros**.
|
| 313 |
+
|
| 314 |
+
#### Modelos Grandes (7B+):
|
| 315 |
+
|
| 316 |
+
| Modelo | Parâmetros (B) | Δ Acurácia Geral | Acurácia Geral (%) | Δ Tempo (s) |
|
| 317 |
+
| :---- | :---- | :---- | :---- | :---- |
|
| 318 |
+
| **Qwen2-VL-7B-Instruct-tuned** | 8.29 | **\+13.74%** | 64.53 → **78.27** | \-0.04 |
|
| 319 |
+
|
| 320 |
+
- Ajuste fino em modelos grandes traz melhorias mais modestas (**\+13,74%**) comparado a modelos menores, sugerindo **diminishing returns**.
|
| 321 |
+
- Acurácia em RG do Qwen2-VL-7B-tuned salta de **65,47% → 82,18%**, útil para casos críticos de precisão.
|
| 322 |
+
|
| 323 |
+
#### Comparativo Geral: Tamanho vs. Eficácia do Ajuste Fino
|
| 324 |
+
|
| 325 |
+
| Categoria | Δ Acurácia Média | Δ Tempo Médio |
|
| 326 |
+
| :---- | :---- | :---- |
|
| 327 |
+
| **Pequenos (1B–3B)** | **\+26,32%** | **\-0,18s** |
|
| 328 |
+
| **Médios (4B–4B)** | **\+18,01%** | **\-0,50s** |
|
| 329 |
+
| **Grandes (7B+)** | **\+13,74%** | **\-0,04s** |
|
| 330 |
+
|
| 331 |
+
- **Quanto menor o modelo, maior o ganho relativo com ajuste fino**.
|
| 332 |
+
- **Tempo de Inferência:** Houve redução no tempo de inferência em todos os modelos ajustados, pois neles eu não utilizei a ferramenta de saída estrutura que guia o modelo ao json schema. Isso foi feito pois percebi que os modelos se saiam melhor sem essa ferramenta.
|
| 333 |
+
- **NF permanece desafio**: Mesmo com tuning, acurácia máxima em NF é **76,79%** (InternVL2\_5-4B-tuned), abaixo de CNH/RG.
|
| 334 |
+
|
| 335 |
+
#### Conclusão
|
| 336 |
+
|
| 337 |
+
O ajuste fino torna modelos menores competitivos com modelos grandes não ajustados. Não foram feitas tantas experimentações com ajuste de hiperparâmetros, pois passei mais tempo tentando realizar o treinamento em si, e surpreendentemente os experimentos básicos utilizando lora ranks pequenos (2 e 4\) e com a estratégia de decaimento rslora foram resultados muito bons.
|
| 338 |
+
|
| 339 |
+
## Avaliação de Generalização
|
| 340 |
+
|
| 341 |
+
Atualmente, estou avaliando o comportamento dos modelos ajustados em documentos e layouts diferentes daqueles vistos durante o treinamento, a fim de identificar eventuais esquecimentos das habilidades básicas do modelo.
|
| 342 |
+
|
| 343 |
+
Não dispomos de um conjunto de dados robusto que já tenha passado pela API de extração de documentos – contamos apenas com algumas certidões e um número maior de comprovantes de pagamento. Realizei uma pesquisa por datasets brasileiros que contivessem, ao menos, imagens capazes de gerar uma saída estruturada, mas não encontrei alternativas satisfatórias.
|
| 344 |
+
|
| 345 |
+
Optei, então, por utilizar um dataset em inglês que segue uma lógica semelhante à aplicação, ou seja, utiliza um esquema JSON de entrada para um tipo de documento e gera o JSON de saída esperado ([getomni-ai/ocr-benchmark · Datasets at Hugging Face](https://huggingface.co/datasets/getomni-ai/ocr-benchmark)).
|
| 346 |
+
|
| 347 |
+
O dataset abrange 18 tipos de documentos com layouts variados e inclui casos complexos com gráficos, tabelas e fotos. Excluí formatos que não contivessem, pelo menos, 5 amostras e, em seguida, ordenei o dataset pelo tamanho do JSON de saída, selecionando 5 amostras de 8 formatos que apresentavam os menores JSONs. Esse procedimento se justifica pelo fato de o dataset conter estruturas bastante complexas, e o objetivo não é avaliar a acurácia absoluta, mas sim a acurácia relativa entre o modelo pré-treinado e sua versão ajustada, a fim de identificar eventuais quedas de desempenho em estruturas não treinadas.
|
| 348 |
+
|
| 349 |
+
Todo o notebook foi preparado e as avaliações estão em execução no momento.
|
| 350 |
+
|
assets/activations_diagram.md
ADDED
|
@@ -0,0 +1,71 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
```mermaid
|
| 2 |
+
classDiagram
|
| 3 |
+
namespace Activations {
|
| 4 |
+
class IActivation {
|
| 5 |
+
<<interface>>
|
| 6 |
+
+forward(INDArray input) INDArray
|
| 7 |
+
+backward(INDArray input) INDArray
|
| 8 |
+
}
|
| 9 |
+
class Activation {
|
| 10 |
+
<<static>>
|
| 11 |
+
-Map<ActivateEnum>, IActivation activationMap
|
| 12 |
+
-Map<String>, ActivateEnum labelMap
|
| 13 |
+
-Activation()
|
| 14 |
+
+static valueOfLabel(String label) ActivateEnum
|
| 15 |
+
+static create(ActivateEnum type) IActivation
|
| 16 |
+
+static create(String type) IActivation
|
| 17 |
+
}
|
| 18 |
+
class ActivateEnum {
|
| 19 |
+
<<enumeration>>
|
| 20 |
+
SIGMOID
|
| 21 |
+
TANH
|
| 22 |
+
RELU
|
| 23 |
+
SOFTMAX
|
| 24 |
+
SILU
|
| 25 |
+
LEAKY_RELU
|
| 26 |
+
LINEAR
|
| 27 |
+
}
|
| 28 |
+
class Sigmoid {
|
| 29 |
+
+forward(INDArray input) INDArray
|
| 30 |
+
+backward(INDArray input) INDArray
|
| 31 |
+
}
|
| 32 |
+
class TanH {
|
| 33 |
+
+forward(INDArray input) INDArray
|
| 34 |
+
+backward(INDArray input) INDArray
|
| 35 |
+
}
|
| 36 |
+
class ReLU {
|
| 37 |
+
+forward(INDArray input) INDArray
|
| 38 |
+
+backward(INDArray input) INDArray
|
| 39 |
+
}
|
| 40 |
+
class LeakyReLU {
|
| 41 |
+
-double alpha
|
| 42 |
+
+forward(INDArray input) INDArray
|
| 43 |
+
+backward(INDArray input) INDArray
|
| 44 |
+
+setAlpha(double alpha) void
|
| 45 |
+
}
|
| 46 |
+
class Linear {
|
| 47 |
+
+forward(INDArray input) INDArray
|
| 48 |
+
+backward(INDArray input) INDArray
|
| 49 |
+
}
|
| 50 |
+
class SiLU {
|
| 51 |
+
-Sigmoid sigmoid
|
| 52 |
+
+forward(INDArray input) INDArray
|
| 53 |
+
+backward(INDArray input) INDArray
|
| 54 |
+
}
|
| 55 |
+
class Softmax {
|
| 56 |
+
+forward(INDArray input) INDArray
|
| 57 |
+
+backward(INDArray input) INDArray
|
| 58 |
+
}
|
| 59 |
+
}
|
| 60 |
+
|
| 61 |
+
IActivation <|.. Sigmoid
|
| 62 |
+
IActivation <|.. TanH
|
| 63 |
+
IActivation <|.. ReLU
|
| 64 |
+
IActivation <|.. LeakyReLU
|
| 65 |
+
IActivation <|.. Linear
|
| 66 |
+
IActivation <|.. SiLU
|
| 67 |
+
IActivation <|.. Softmax
|
| 68 |
+
Activation o--> ActivateEnum
|
| 69 |
+
Activation <|.. IActivation
|
| 70 |
+
SiLU ..> Sigmoid
|
| 71 |
+
```
|
assets/black_bee.png
ADDED

|
Git LFS Details
|
assets/data_diagram.md
ADDED
|
@@ -0,0 +1,88 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
```mermaid
|
| 2 |
+
classDiagram
|
| 3 |
+
namespace Data {
|
| 4 |
+
class DataLoader {
|
| 5 |
+
-INDArray trainData
|
| 6 |
+
-INDArray testData
|
| 7 |
+
+DataLoader(String trainDataPath, String testDataPath)
|
| 8 |
+
+DataLoader(String trainX, String trainY, String testX, String testY)
|
| 9 |
+
+static INDArray loadCsv(String csvFile)
|
| 10 |
+
+INDArray getAllTrainImages()
|
| 11 |
+
+INDArray getAllTestImages()
|
| 12 |
+
+INDArray getAllTrainLabels()
|
| 13 |
+
+INDArray getAllTestLabels()
|
| 14 |
+
+INDArray getTrainImage(int index)
|
| 15 |
+
+INDArray getTestImage(int index)
|
| 16 |
+
+int getTrainLabel(int index)
|
| 17 |
+
+int getTestLabel(int index)
|
| 18 |
+
+INDArray getTrainData()
|
| 19 |
+
+INDArray getTestData()
|
| 20 |
+
}
|
| 21 |
+
|
| 22 |
+
class Util {
|
| 23 |
+
+static INDArray normalize(INDArray array)
|
| 24 |
+
+static INDArray unnormalize(INDArray array)
|
| 25 |
+
+static INDArray clip(INDArray array, double min, double max)
|
| 26 |
+
+static INDArray[][] trainTestSplit(INDArray x, INDArray y, double trainSize)
|
| 27 |
+
+static void printProgressBar(int current, int total)
|
| 28 |
+
+static INDArray oneHotEncode(INDArray labels, int numClasses)
|
| 29 |
+
+static WritableImage arrayToImage(INDArray imageArray, int WIDTH, int HEIGHT)
|
| 30 |
+
+static WritableImage byteArrayToImage(byte[] byteArray)
|
| 31 |
+
+static INDArray imageToINDArray(WritableImage writableImage, int width, int height)
|
| 32 |
+
+static INDArray bytesToINDArray(byte[] bytes, int width, int height)
|
| 33 |
+
+static INDArray confusionMatrix(INDArray predictions, INDArray labels)
|
| 34 |
+
}
|
| 35 |
+
|
| 36 |
+
class PlotDataPredict {
|
| 37 |
+
+void plot2d(INDArray x, INDArray y, INDArray predict, String title)
|
| 38 |
+
+void plot3dGridandScatter(INDArray x, INDArray y, INDArray predict, String title)
|
| 39 |
+
}
|
| 40 |
+
|
| 41 |
+
class DataProcessor {
|
| 42 |
+
<<abstract>>
|
| 43 |
+
+abstract void fit(INDArray data)
|
| 44 |
+
+abstract INDArray transform(INDArray data)
|
| 45 |
+
+abstract INDArray inverseTransform(INDArray data)
|
| 46 |
+
+INDArray fitTransform(INDArray data)
|
| 47 |
+
}
|
| 48 |
+
|
| 49 |
+
class DataPipeline {
|
| 50 |
+
-List<DataProcessor> processors
|
| 51 |
+
+DataPipeline(List<DataProcessor> processors)
|
| 52 |
+
+DataPipeline()
|
| 53 |
+
+void add(DataProcessor processor)
|
| 54 |
+
+void fit(INDArray data)
|
| 55 |
+
+INDArray transform(INDArray data)
|
| 56 |
+
+INDArray fitTransform(INDArray data)
|
| 57 |
+
+INDArray inverseTransform(INDArray data)
|
| 58 |
+
+List<DataProcessor> getProcessors()
|
| 59 |
+
}
|
| 60 |
+
|
| 61 |
+
class StandardScaler {
|
| 62 |
+
-double mean, std
|
| 63 |
+
-static final double EPSILON
|
| 64 |
+
+void fit(INDArray data)
|
| 65 |
+
+INDArray transform(INDArray data)
|
| 66 |
+
+INDArray inverseTransform(INDArray data)
|
| 67 |
+
+double getMean()
|
| 68 |
+
+double getStd()
|
| 69 |
+
}
|
| 70 |
+
|
| 71 |
+
class MinMaxScaler {
|
| 72 |
+
-INDArray min, max
|
| 73 |
+
-final double minRange
|
| 74 |
+
-final double maxRange
|
| 75 |
+
+MinMaxScaler(double minRange, double maxRange)
|
| 76 |
+
+MinMaxScaler()
|
| 77 |
+
+void fit(INDArray data)
|
| 78 |
+
+INDArray transform(INDArray data)
|
| 79 |
+
+INDArray inverseTransform(INDArray data)
|
| 80 |
+
}
|
| 81 |
+
}
|
| 82 |
+
|
| 83 |
+
%% Relationships within Data namespace
|
| 84 |
+
DataProcessor <|-- StandardScaler
|
| 85 |
+
DataProcessor <|-- MinMaxScaler
|
| 86 |
+
DataProcessor <|-- DataPipeline
|
| 87 |
+
DataPipeline *--> "0..*" DataProcessor: contains
|
| 88 |
+
```
|
assets/database_diagram.md
ADDED
|
@@ -0,0 +1,13 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
```mermaid
|
| 2 |
+
classDiagram
|
| 3 |
+
namespace Database {
|
| 4 |
+
class NeuralNetworkService {
|
| 5 |
+
-final static String MONGODB_URI
|
| 6 |
+
-final Datastore datastore
|
| 7 |
+
+NeuralNetworkService()
|
| 8 |
+
+void saveModel(NeuralNetwork model)
|
| 9 |
+
+NeuralNetwork loadModel(String modelName)
|
| 10 |
+
+List<NeuralNetwork> getAllModels()
|
| 11 |
+
}
|
| 12 |
+
}
|
| 13 |
+
```
|
assets/drone_line_following_video.mp4
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:22c81837e66130a2d5ee60dc30cc544ec61683df62516d4a8a1ea61f3a37d34f
|
| 3 |
+
size 131817886
|
assets/full_diagram.md
ADDED
|
@@ -0,0 +1,694 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
```mermaid
|
| 2 |
+
classDiagram
|
| 3 |
+
%% Removido o namespace Activations e cardinalidade complexa %%
|
| 4 |
+
class IActivation {
|
| 5 |
+
<<interface>>
|
| 6 |
+
+forward(INDArray input) INDArray
|
| 7 |
+
+backward(INDArray input) INDArray
|
| 8 |
+
}
|
| 9 |
+
class Activation {
|
| 10 |
+
<<static>>
|
| 11 |
+
-Map activationMap %% Simplificado %%
|
| 12 |
+
-Map labelMap %% Simplificado %%
|
| 13 |
+
-Activation()
|
| 14 |
+
+static valueOfLabel(String label) ActivateEnum
|
| 15 |
+
+static create(ActivateEnum type) IActivation
|
| 16 |
+
+static create(String type) IActivation
|
| 17 |
+
}
|
| 18 |
+
class ActivateEnum {
|
| 19 |
+
<<enumeration>>
|
| 20 |
+
SIGMOID
|
| 21 |
+
TANH
|
| 22 |
+
RELU
|
| 23 |
+
SOFTMAX
|
| 24 |
+
SILU
|
| 25 |
+
LEAKY_RELU
|
| 26 |
+
LINEAR
|
| 27 |
+
}
|
| 28 |
+
class Sigmoid {
|
| 29 |
+
+forward(INDArray input) INDArray
|
| 30 |
+
+backward(INDArray input) INDArray
|
| 31 |
+
}
|
| 32 |
+
class TanH {
|
| 33 |
+
+forward(INDArray input) INDArray
|
| 34 |
+
+backward(INDArray input) INDArray
|
| 35 |
+
}
|
| 36 |
+
class ReLU {
|
| 37 |
+
+forward(INDArray input) INDArray
|
| 38 |
+
+backward(INDArray input) INDArray
|
| 39 |
+
}
|
| 40 |
+
class LeakyReLU {
|
| 41 |
+
-double alpha
|
| 42 |
+
+forward(INDArray input) INDArray
|
| 43 |
+
+backward(INDArray input) INDArray
|
| 44 |
+
+setAlpha(double alpha) void
|
| 45 |
+
}
|
| 46 |
+
class Linear {
|
| 47 |
+
+forward(INDArray input) INDArray
|
| 48 |
+
+backward(INDArray input) INDArray
|
| 49 |
+
}
|
| 50 |
+
class SiLU {
|
| 51 |
+
-Sigmoid sigmoid
|
| 52 |
+
+forward(INDArray input) INDArray
|
| 53 |
+
+backward(INDArray input) INDArray
|
| 54 |
+
}
|
| 55 |
+
class Softmax {
|
| 56 |
+
+forward(INDArray input) INDArray
|
| 57 |
+
+backward(INDArray input) INDArray
|
| 58 |
+
}
|
| 59 |
+
|
| 60 |
+
IActivation <|.. Sigmoid
|
| 61 |
+
IActivation <|.. TanH
|
| 62 |
+
IActivation <|.. ReLU
|
| 63 |
+
IActivation <|.. LeakyReLU
|
| 64 |
+
IActivation <|.. Linear
|
| 65 |
+
IActivation <|.. SiLU
|
| 66 |
+
IActivation <|.. Softmax
|
| 67 |
+
Activation o--> ActivateEnum
|
| 68 |
+
Activation <|.. IActivation
|
| 69 |
+
SiLU ..> Sigmoid
|
| 70 |
+
|
| 71 |
+
Dense *--> IActivation
|
| 72 |
+
Conv2D *--> IActivation
|
| 73 |
+
|
| 74 |
+
%% Removido o namespace models %%
|
| 75 |
+
class ModelBuilder {
|
| 76 |
+
+layers: List %% Simplificado %%
|
| 77 |
+
+add(layer:Layer): ModelBuilder
|
| 78 |
+
+build(): NeuralNetwork
|
| 79 |
+
}
|
| 80 |
+
class NeuralNetwork {
|
| 81 |
+
+id: ObjectId
|
| 82 |
+
+name: String
|
| 83 |
+
#layers: List %% Simplificado %%
|
| 84 |
+
-trainableLayers: List %% Simplificado %%
|
| 85 |
+
-output: INDArray
|
| 86 |
+
+NeuralNetwork(modelBuilder:ModelBuilder)
|
| 87 |
+
#NeuralNetwork()
|
| 88 |
+
+initTrainableLayers()
|
| 89 |
+
+getId(): ObjectId
|
| 90 |
+
+setName(name:String): void
|
| 91 |
+
+getName(): String
|
| 92 |
+
+predict(x:INDArray): INDArray
|
| 93 |
+
+backPropagation(gradout:INDArray): void
|
| 94 |
+
+getLayers(): List %% Simplificado %%
|
| 95 |
+
+getTrainableLayers(): List %% Simplificado %%
|
| 96 |
+
-setLayers(layers:List): void %% Simplificado %%
|
| 97 |
+
+setTrainable(trainable:boolean): void
|
| 98 |
+
+setInference(inference:boolean): void
|
| 99 |
+
+saveModel(String filePath): void
|
| 100 |
+
+static loadModel(String filePath): NeuralNetwork
|
| 101 |
+
}
|
| 102 |
+
|
| 103 |
+
ModelBuilder --> NeuralNetwork: builds
|
| 104 |
+
ModelBuilder *--> Layer: contains %% Cardinalidade simplificada %%
|
| 105 |
+
NeuralNetwork *--> Layer: contains %% Cardinalidade simplificada %%
|
| 106 |
+
NeuralNetwork *--> TrainableLayer: contains %% Cardinalidade simplificada %%
|
| 107 |
+
Optimizer o--> NeuralNetwork: manages
|
| 108 |
+
NeuralNetwork ..> LayerLoader: uses
|
| 109 |
+
|
| 110 |
+
%% Removido o namespace Layers %%
|
| 111 |
+
class Layer {
|
| 112 |
+
<<abstract>>
|
| 113 |
+
#INDArray input
|
| 114 |
+
#INDArray output
|
| 115 |
+
#boolean inference
|
| 116 |
+
+INDArray forward(INDArray inputs)*
|
| 117 |
+
+INDArray backward(INDArray gradout)*
|
| 118 |
+
+Layer load(DataInputStream dis)
|
| 119 |
+
+void save(DataOutputStream dos)
|
| 120 |
+
+void saveAdditional(DataOutputStream dos)*
|
| 121 |
+
+Layer loadAdditional(DataInputStream dis)*
|
| 122 |
+
+void setInput(INDArray input)
|
| 123 |
+
+INDArray getInput()
|
| 124 |
+
+void setOutput(INDArray output)
|
| 125 |
+
+INDArray getOutput()
|
| 126 |
+
+void setInference(boolean inference)
|
| 127 |
+
+void save(Datastore datastore)
|
| 128 |
+
}
|
| 129 |
+
class Flatten {
|
| 130 |
+
+Flatten()
|
| 131 |
+
+INDArray forward(INDArray inputs)
|
| 132 |
+
+INDArray backward(INDArray gradout)
|
| 133 |
+
+String toString()
|
| 134 |
+
+Flatten loadAdditional(DataInputStream dis)
|
| 135 |
+
+void saveAdditional(DataOutputStream dos)
|
| 136 |
+
}
|
| 137 |
+
class Dropout {
|
| 138 |
+
-double dropoutRate
|
| 139 |
+
-INDArray mask
|
| 140 |
+
+Dropout(double dropoutRate)
|
| 141 |
+
+Dropout()
|
| 142 |
+
+INDArray forward(INDArray inputs)
|
| 143 |
+
+INDArray backward(INDArray gradout)
|
| 144 |
+
+String toString()
|
| 145 |
+
+double getDropoutRate()
|
| 146 |
+
+void setDropoutRate(double dropoutRate)
|
| 147 |
+
+INDArray getMask()
|
| 148 |
+
+void setMask(INDArray mask)
|
| 149 |
+
+void saveAdditional(DataOutputStream dos)
|
| 150 |
+
+Dropout loadAdditional(DataInputStream dis)
|
| 151 |
+
}
|
| 152 |
+
class ZeroPadding2D {
|
| 153 |
+
#int padding
|
| 154 |
+
+ZeroPadding2D(int padding)
|
| 155 |
+
+ZeroPadding2D()
|
| 156 |
+
+INDArray forward(INDArray inputs)
|
| 157 |
+
+INDArray backward(INDArray gradout)
|
| 158 |
+
+ZeroPadding2D loadAdditional(DataInputStream dis)
|
| 159 |
+
+void saveAdditional(DataOutputStream dos)
|
| 160 |
+
+String toString()
|
| 161 |
+
}
|
| 162 |
+
class MaxPooling2D {
|
| 163 |
+
-int poolSize
|
| 164 |
+
-int stride
|
| 165 |
+
+MaxPooling2D(int poolSize, int stride)
|
| 166 |
+
+MaxPooling2D()
|
| 167 |
+
+INDArray forward(INDArray inputs)
|
| 168 |
+
+INDArray backward(INDArray gradout)
|
| 169 |
+
+String toString()
|
| 170 |
+
+MaxPooling2D loadAdditional(DataInputStream dis)
|
| 171 |
+
+void saveAdditional(DataOutputStream dos)
|
| 172 |
+
}
|
| 173 |
+
class TrainableLayer {
|
| 174 |
+
<<abstract>>
|
| 175 |
+
#INDArray params
|
| 176 |
+
#INDArray grads
|
| 177 |
+
#boolean trainable
|
| 178 |
+
#byte[] paramsData
|
| 179 |
+
#byte[] gradsData
|
| 180 |
+
+void setup(INDArray input)
|
| 181 |
+
+INDArray getParams()
|
| 182 |
+
+void setParams(INDArray params)
|
| 183 |
+
+INDArray getGrads()
|
| 184 |
+
+void setGrads(INDArray grads)
|
| 185 |
+
+void setTrainable(boolean trainable)
|
| 186 |
+
+boolean isTrainable()
|
| 187 |
+
+void saveAdditional(DataOutputStream dos)
|
| 188 |
+
+TrainableLayer loadAdditional(DataInputStream dis)
|
| 189 |
+
}
|
| 190 |
+
class Dense {
|
| 191 |
+
-IActivation activation
|
| 192 |
+
-String activationType
|
| 193 |
+
-int units
|
| 194 |
+
-boolean isInitialized
|
| 195 |
+
-String kernelInitializer
|
| 196 |
+
-double lambda
|
| 197 |
+
+Dense(int units, IActivation activation, String kernelInitializer, double lambda)
|
| 198 |
+
+Dense(int units, IActivation activation, String kernelInitializer)
|
| 199 |
+
+Dense(int units, IActivation activation)
|
| 200 |
+
+Dense(int units)
|
| 201 |
+
+Dense()
|
| 202 |
+
+INDArray getWeights()
|
| 203 |
+
+INDArray getGradientWeights()
|
| 204 |
+
+INDArray getBias()
|
| 205 |
+
+INDArray getGradientBias()
|
| 206 |
+
+void setup(INDArray inputs)
|
| 207 |
+
+INDArray forward(INDArray inputs)
|
| 208 |
+
+INDArray backward(INDArray gradout)
|
| 209 |
+
+IActivation getActivation()
|
| 210 |
+
+int getUnits()
|
| 211 |
+
+String getKernelInitializer()
|
| 212 |
+
}
|
| 213 |
+
class Conv2D {
|
| 214 |
+
#int filters
|
| 215 |
+
#int kernelSize
|
| 216 |
+
#List strides %% Simplificado %%
|
| 217 |
+
#String padding
|
| 218 |
+
#IActivation activation
|
| 219 |
+
#String activationType
|
| 220 |
+
#String kernelInitializer
|
| 221 |
+
#int pad
|
| 222 |
+
#Layer zeroPadding2D %% Simplificado %%
|
| 223 |
+
#int m, nHInput, nWInput, nCInput
|
| 224 |
+
#int nHOutput, nWOutput, nCOutput
|
| 225 |
+
#boolean isInitialized
|
| 226 |
+
#INDArray paddedInputs
|
| 227 |
+
#INDArray weightsC, biasesC, aPrev, aSlicePrev
|
| 228 |
+
#int[] vert_starts, horiz_starts
|
| 229 |
+
+Conv2D(int filters, int kernelSize, List strides, String padding, IActivation activation, String kernelInitializer) %% Simplificado %%
|
| 230 |
+
+Conv2D(int filters, int kernelSize, String padding, IActivation activation, String kernelInitializer)
|
| 231 |
+
+Conv2D(int filters, int kernelSize, IActivation activation)
|
| 232 |
+
+Conv2D(int filters, int kernelSize)
|
| 233 |
+
+Conv2D()
|
| 234 |
+
+void setup(INDArray inputs)
|
| 235 |
+
+INDArray forward(INDArray inputs)
|
| 236 |
+
+INDArray backward(INDArray gradout)
|
| 237 |
+
+INDArray getWeights()
|
| 238 |
+
+INDArray getBiases()
|
| 239 |
+
+void setWeights(INDArray weights)
|
| 240 |
+
+void setBiases(INDArray biases)
|
| 241 |
+
+INDArray getGradWeights()
|
| 242 |
+
+INDArray getGradBiases()
|
| 243 |
+
}
|
| 244 |
+
class LayerLoader {
|
| 245 |
+
-Map layerLoaders %% Simplificado %%
|
| 246 |
+
+static Layer load(DataInputStream dis)
|
| 247 |
+
}
|
| 248 |
+
|
| 249 |
+
Layer <|-- TrainableLayer : extends
|
| 250 |
+
TrainableLayer <|-- Dense : extends
|
| 251 |
+
TrainableLayer <|-- Conv2D : extends
|
| 252 |
+
Layer <|-- Flatten : extends
|
| 253 |
+
Layer <|-- Dropout : extends
|
| 254 |
+
Layer <|-- MaxPooling2D : extends
|
| 255 |
+
Layer <|-- ZeroPadding2D : extends
|
| 256 |
+
Conv2D *-- ZeroPadding2D : uses
|
| 257 |
+
LayerLoader --> Layer : creates
|
| 258 |
+
|
| 259 |
+
%% Removido o namespace Optimizers %%
|
| 260 |
+
class Optimizer {
|
| 261 |
+
<<abstract>>
|
| 262 |
+
#NeuralNetwork neuralNetwork
|
| 263 |
+
#LearningRateDecayStrategy learningRateDecayStrategy
|
| 264 |
+
#double learningRate
|
| 265 |
+
#Map auxParams %% Simplificado %%
|
| 266 |
+
#List trainableLayers %% Simplificado %%
|
| 267 |
+
-boolean initialized
|
| 268 |
+
|
| 269 |
+
+Optimizer()
|
| 270 |
+
#Optimizer(double learningRate)
|
| 271 |
+
+Optimizer(LearningRateDecayStrategy learningRateDecayStrategy)
|
| 272 |
+
+Optimizer(NeuralNetwork neuralNetwork)
|
| 273 |
+
+setNeuralNetwork(NeuralNetwork neuralNetwork)
|
| 274 |
+
#init()
|
| 275 |
+
+update()
|
| 276 |
+
+updateEpoch()
|
| 277 |
+
#abstract List createAuxParams(INDArray params) %% Simplificado %%
|
| 278 |
+
#abstract void updateRule(INDArray params, INDArray grads, List auxParams) %% Simplificado %%
|
| 279 |
+
}
|
| 280 |
+
|
| 281 |
+
class LearningRateDecayStrategy {
|
| 282 |
+
<<abstract>>
|
| 283 |
+
#double decayPerEpoch
|
| 284 |
+
#double learningRate
|
| 285 |
+
|
| 286 |
+
+LearningRateDecayStrategy(double initialRate, double finalRate, int epochs)
|
| 287 |
+
#abstract double calculateDecayPerEpoch(double initialRate, double finalRate, int epochs)
|
| 288 |
+
+abstract double updateLearningRate()
|
| 289 |
+
}
|
| 290 |
+
|
| 291 |
+
class ExponentialDecayStrategy {
|
| 292 |
+
+ExponentialDecayStrategy(double initialRate, double finalRate, int epochs)
|
| 293 |
+
#double calculateDecayPerEpoch(double initialRate, double finalRate, int epochs)
|
| 294 |
+
+double updateLearningRate()
|
| 295 |
+
}
|
| 296 |
+
|
| 297 |
+
class LinearDecayStrategy {
|
| 298 |
+
+LinearDecayStrategy(double initialRate, double finalRate, int epochs)
|
| 299 |
+
#double calculateDecayPerEpoch(double initialRate, double finalRate, int epochs)
|
| 300 |
+
+double updateLearningRate()
|
| 301 |
+
}
|
| 302 |
+
|
| 303 |
+
class SGD {
|
| 304 |
+
+SGD(double learningRate)
|
| 305 |
+
+SGD(LearningRateDecayStrategy learningRateDecayStrategy)
|
| 306 |
+
+SGD()
|
| 307 |
+
#List createAuxParams(INDArray params) %% Simplificado %%
|
| 308 |
+
#void updateRule(INDArray params, INDArray grads, List auxParams) %% Simplificado %%
|
| 309 |
+
}
|
| 310 |
+
|
| 311 |
+
class SGDMomentum {
|
| 312 |
+
-double momentum
|
| 313 |
+
-INDArray velocities
|
| 314 |
+
|
| 315 |
+
+SGDMomentum(double learningRate, double momentum)
|
| 316 |
+
+SGDMomentum(double learningRate)
|
| 317 |
+
+SGDMomentum(LearningRateDecayStrategy learningRateDecayStrategy, double momentum)
|
| 318 |
+
+SGDMomentum(LearningRateDecayStrategy learningRateDecayStrategy)
|
| 319 |
+
#List createAuxParams(INDArray params) %% Simplificado %%
|
| 320 |
+
#void updateRule(INDArray params, INDArray grads, List auxParams) %% Simplificado %%
|
| 321 |
+
}
|
| 322 |
+
|
| 323 |
+
class SGDNesterov {
|
| 324 |
+
-double momentum
|
| 325 |
+
-INDArray velocities
|
| 326 |
+
|
| 327 |
+
+SGDNesterov(double learningRate, double momentum)
|
| 328 |
+
+SGDNesterov(double learningRate)
|
| 329 |
+
+SGDNesterov(LearningRateDecayStrategy learningRateDecayStrategy, double momentum)
|
| 330 |
+
+SGDNesterov(LearningRateDecayStrategy learningRateDecayStrategy)
|
| 331 |
+
#List createAuxParams(INDArray params) %% Simplificado %%
|
| 332 |
+
#void updateRule(INDArray params, INDArray grads, List auxParams) %% Simplificado %%
|
| 333 |
+
}
|
| 334 |
+
|
| 335 |
+
class RegularizedSGD {
|
| 336 |
+
-double alpha
|
| 337 |
+
|
| 338 |
+
+RegularizedSGD(double learningRate, double alpha)
|
| 339 |
+
+RegularizedSGD()
|
| 340 |
+
+RegularizedSGD(double learningRate)
|
| 341 |
+
+RegularizedSGD(LearningRateDecayStrategy learningRateDecayStrategy)
|
| 342 |
+
+RegularizedSGD(LearningRateDecayStrategy learningRateDecayStrategy, double alpha)
|
| 343 |
+
#List createAuxParams(INDArray params) %% Simplificado %%
|
| 344 |
+
#void updateRule(INDArray params, INDArray grads, List auxParams) %% Simplificado %%
|
| 345 |
+
}
|
| 346 |
+
|
| 347 |
+
class AdaGrad {
|
| 348 |
+
-double eps
|
| 349 |
+
-INDArray sumSquares
|
| 350 |
+
|
| 351 |
+
+AdaGrad(double lr)
|
| 352 |
+
+AdaGrad()
|
| 353 |
+
+AdaGrad(LearningRateDecayStrategy learningRateDecayStrategy)
|
| 354 |
+
#List createAuxParams(INDArray params) %% Simplificado %%
|
| 355 |
+
#void updateRule(INDArray params, INDArray grads, List auxParams) %% Simplificado %%
|
| 356 |
+
}
|
| 357 |
+
|
| 358 |
+
class RMSProp {
|
| 359 |
+
-double decayRate
|
| 360 |
+
-double epsilon
|
| 361 |
+
-INDArray accumulator
|
| 362 |
+
|
| 363 |
+
+RMSProp(double learningRate, double decayRate, double epsilon)
|
| 364 |
+
+RMSProp(LearningRateDecayStrategy learningRateDecayStrategy, double decayRate, double epsilon)
|
| 365 |
+
+RMSProp(LearningRateDecayStrategy learningRateDecayStrategy)
|
| 366 |
+
+RMSProp()
|
| 367 |
+
+RMSProp(double learningRate, double decayRate)
|
| 368 |
+
+RMSProp(double learningRate)
|
| 369 |
+
#List createAuxParams(INDArray params) %% Simplificado %%
|
| 370 |
+
#void updateRule(INDArray params, INDArray grads, List auxParams) %% Simplificado %%
|
| 371 |
+
}
|
| 372 |
+
|
| 373 |
+
class Adam {
|
| 374 |
+
-double beta1
|
| 375 |
+
-double beta2
|
| 376 |
+
-double epsilon
|
| 377 |
+
-INDArray m
|
| 378 |
+
-INDArray v
|
| 379 |
+
-int t
|
| 380 |
+
|
| 381 |
+
+Adam(double learningRate, double beta1, double beta2, double epsilon)
|
| 382 |
+
+Adam(double learningRate)
|
| 383 |
+
+Adam()
|
| 384 |
+
+Adam(LearningRateDecayStrategy learningRateDecayStrategy, double beta1, double beta2, double epsilon)
|
| 385 |
+
+Adam(LearningRateDecayStrategy learningRateDecayStrategy)
|
| 386 |
+
#List createAuxParams(INDArray params) %% Simplificado %%
|
| 387 |
+
#void updateRule(INDArray params, INDArray grads, List auxParams) %% Simplificado %%
|
| 388 |
+
}
|
| 389 |
+
|
| 390 |
+
class AdaDelta {
|
| 391 |
+
-double decayRate
|
| 392 |
+
-double epsilon
|
| 393 |
+
-INDArray accumulator
|
| 394 |
+
-INDArray delta
|
| 395 |
+
|
| 396 |
+
+AdaDelta(double decayRate, double epsilon)
|
| 397 |
+
+AdaDelta(double decayRate)
|
| 398 |
+
+AdaDelta()
|
| 399 |
+
#List createAuxParams(INDArray params) %% Simplificado %%
|
| 400 |
+
#void updateRule(INDArray params, INDArray grads, List auxParams) %% Simplificado %%
|
| 401 |
+
}
|
| 402 |
+
|
| 403 |
+
Optimizer <|-- SGD
|
| 404 |
+
Optimizer <|-- SGDMomentum
|
| 405 |
+
Optimizer <|-- SGDNesterov
|
| 406 |
+
Optimizer <|-- RegularizedSGD
|
| 407 |
+
Optimizer <|-- AdaGrad
|
| 408 |
+
Optimizer <|-- RMSProp
|
| 409 |
+
Optimizer <|-- Adam
|
| 410 |
+
Optimizer <|-- AdaDelta
|
| 411 |
+
|
| 412 |
+
LearningRateDecayStrategy <|-- LinearDecayStrategy
|
| 413 |
+
LearningRateDecayStrategy <|-- ExponentialDecayStrategy
|
| 414 |
+
|
| 415 |
+
Optimizer o-- LearningRateDecayStrategy
|
| 416 |
+
|
| 417 |
+
TrainableLayer <--o Optimizer: trainableLayers %% Cardinalidade simplificada %%
|
| 418 |
+
|
| 419 |
+
%% Removido o namespace Losses %%
|
| 420 |
+
class ILossFunction {
|
| 421 |
+
<<interface>>
|
| 422 |
+
+INDArray forward(INDArray predicted, INDArray real)
|
| 423 |
+
+INDArray backward(INDArray predicted, INDArray real)
|
| 424 |
+
}
|
| 425 |
+
|
| 426 |
+
class MeanSquaredError {
|
| 427 |
+
+INDArray forward(INDArray predictions, INDArray labels)
|
| 428 |
+
+INDArray backward(INDArray predictions, INDArray labels)
|
| 429 |
+
}
|
| 430 |
+
|
| 431 |
+
class BinaryCrossEntropy {
|
| 432 |
+
+INDArray forward(INDArray predictions, INDArray labels)
|
| 433 |
+
+INDArray backward(INDArray predictions, INDArray labels)
|
| 434 |
+
}
|
| 435 |
+
|
| 436 |
+
class CategoricalCrossEntropy {
|
| 437 |
+
-double eps
|
| 438 |
+
+INDArray forward(INDArray predicted, INDArray real)
|
| 439 |
+
+INDArray backward(INDArray predicted, INDArray real)
|
| 440 |
+
}
|
| 441 |
+
|
| 442 |
+
class SoftmaxCrossEntropy {
|
| 443 |
+
-double eps
|
| 444 |
+
-boolean singleClass
|
| 445 |
+
-INDArray softmaxPreds
|
| 446 |
+
-Softmax softmax
|
| 447 |
+
+SoftmaxCrossEntropy()
|
| 448 |
+
+SoftmaxCrossEntropy(double eps)
|
| 449 |
+
+INDArray forward(INDArray predicted, INDArray real)
|
| 450 |
+
+INDArray backward(INDArray predicted, INDArray real)
|
| 451 |
+
}
|
| 452 |
+
|
| 453 |
+
ILossFunction <|.. MeanSquaredError
|
| 454 |
+
ILossFunction <|.. BinaryCrossEntropy
|
| 455 |
+
ILossFunction <|.. CategoricalCrossEntropy
|
| 456 |
+
ILossFunction <|.. SoftmaxCrossEntropy
|
| 457 |
+
|
| 458 |
+
%% Removido o namespace Metrics %%
|
| 459 |
+
class IMetric {
|
| 460 |
+
<<interface>>
|
| 461 |
+
+double evaluate(INDArray yTrue, INDArray yPred)
|
| 462 |
+
}
|
| 463 |
+
|
| 464 |
+
class MSE {
|
| 465 |
+
+double evaluate(INDArray yTrue, INDArray yPred)
|
| 466 |
+
}
|
| 467 |
+
|
| 468 |
+
class RMSE {
|
| 469 |
+
+double evaluate(INDArray yTrue, INDArray yPred)
|
| 470 |
+
}
|
| 471 |
+
|
| 472 |
+
class MAE {
|
| 473 |
+
+double evaluate(INDArray yTrue, INDArray yPred)
|
| 474 |
+
}
|
| 475 |
+
|
| 476 |
+
class R2 {
|
| 477 |
+
+double evaluate(INDArray yTrue, INDArray yPred)
|
| 478 |
+
}
|
| 479 |
+
|
| 480 |
+
class Accuracy {
|
| 481 |
+
+double evaluate(INDArray yTrue, INDArray yPred)
|
| 482 |
+
}
|
| 483 |
+
|
| 484 |
+
class Precision {
|
| 485 |
+
+double evaluate(INDArray yTrue, INDArray yPred)
|
| 486 |
+
}
|
| 487 |
+
|
| 488 |
+
class Recall {
|
| 489 |
+
+double evaluate(INDArray yTrue, INDArray yPred)
|
| 490 |
+
}
|
| 491 |
+
|
| 492 |
+
class F1Score {
|
| 493 |
+
+double evaluate(INDArray yTrue, INDArray yPred)
|
| 494 |
+
}
|
| 495 |
+
|
| 496 |
+
IMetric <|.. MSE
|
| 497 |
+
IMetric <|.. RMSE
|
| 498 |
+
IMetric <|.. MAE
|
| 499 |
+
IMetric <|.. R2
|
| 500 |
+
IMetric <|.. Accuracy
|
| 501 |
+
IMetric <|.. Precision
|
| 502 |
+
IMetric <|.. Recall
|
| 503 |
+
IMetric <|.. F1Score
|
| 504 |
+
|
| 505 |
+
F1Score ..> Precision
|
| 506 |
+
F1Score ..> Recall
|
| 507 |
+
|
| 508 |
+
%% Removido o namespace Train %%
|
| 509 |
+
class TrainerBuilder {
|
| 510 |
+
+batch: INDArray[2]
|
| 511 |
+
+trainInputs: INDArray
|
| 512 |
+
+trainTargets: INDArray
|
| 513 |
+
+testInputs: INDArray
|
| 514 |
+
+testTargets: INDArray
|
| 515 |
+
+epochs: int = 100
|
| 516 |
+
+batchSize: int = 32
|
| 517 |
+
+earlyStopping: boolean = false
|
| 518 |
+
+verbose: boolean = true
|
| 519 |
+
+patience: int = 20
|
| 520 |
+
+evalEvery: int = 10
|
| 521 |
+
+trainRatio: double = 0.8
|
| 522 |
+
|
| 523 |
+
+TrainerBuilder(model:NeuralNetwork, trainInputs:INDArray, trainTargets:INDArray, lossFunction:ILossFunction)
|
| 524 |
+
+TrainerBuilder(model:NeuralNetwork, trainInputs:INDArray, trainTargets:INDArray, testInputs:INDArray, testTargets:INDArray, lossFunction:ILossFunction)
|
| 525 |
+
+setOptimizer(optimizer:Optimizer): TrainerBuilder
|
| 526 |
+
+setEpochs(epochs:int): TrainerBuilder
|
| 527 |
+
+setBatchSize(batchSize:int): TrainerBuilder
|
| 528 |
+
+setEarlyStopping(earlyStopping:boolean): TrainerBuilder
|
| 529 |
+
+setPatience(patience:int): TrainerBuilder
|
| 530 |
+
+setTrainRatio(trainRatio:double): TrainerBuilder
|
| 531 |
+
+setEvalEvery(evalEvery:int): TrainerBuilder
|
| 532 |
+
+setVerbose(verbose:boolean): TrainerBuilder
|
| 533 |
+
+setMetric(metric:IMetric): TrainerBuilder
|
| 534 |
+
+build(): Trainer
|
| 535 |
+
}
|
| 536 |
+
|
| 537 |
+
class Trainer {
|
| 538 |
+
-model: NeuralNetwork
|
| 539 |
+
-optimizer: Optimizer
|
| 540 |
+
-lossFunction: ILossFunction
|
| 541 |
+
-metric: IMetric
|
| 542 |
+
-trainInputs: INDArray
|
| 543 |
+
-trainTargets: INDArray
|
| 544 |
+
-testInputs: INDArray
|
| 545 |
+
-testTargets: INDArray
|
| 546 |
+
-batch: INDArray[2]
|
| 547 |
+
-epochs: int
|
| 548 |
+
-batchSize: int
|
| 549 |
+
-currentIndex: int
|
| 550 |
+
-patience: int
|
| 551 |
+
-evalEvery: int
|
| 552 |
+
-earlyStopping: boolean
|
| 553 |
+
-verbose: boolean
|
| 554 |
+
-bestLoss: double
|
| 555 |
+
-wait: int
|
| 556 |
+
-threshold: double
|
| 557 |
+
-trainLoss: double
|
| 558 |
+
-valLoss: double
|
| 559 |
+
-trainMetricValue: double
|
| 560 |
+
-valMetricValue: double
|
| 561 |
+
|
| 562 |
+
+Trainer(TrainerBuilder)
|
| 563 |
+
+fit(): void
|
| 564 |
+
+evaluate(): void
|
| 565 |
+
-earlyStopping(): boolean
|
| 566 |
+
-hasNextBatch(): boolean
|
| 567 |
+
-getNextBatch(): void
|
| 568 |
+
+splitData(inputs:INDArray, targets:INDArray, trainRatio:double): void
|
| 569 |
+
+printDataInfo(): void
|
| 570 |
+
+getTrainInputs(): INDArray
|
| 571 |
+
+getTrainTargets(): INDArray
|
| 572 |
+
+getTestInputs(): INDArray
|
| 573 |
+
+getTestTargets(): INDArray
|
| 574 |
+
}
|
| 575 |
+
|
| 576 |
+
TrainerBuilder --> Trainer: builds
|
| 577 |
+
TrainerBuilder o--> NeuralNetwork: model
|
| 578 |
+
TrainerBuilder o--> ILossFunction: lossFunction
|
| 579 |
+
TrainerBuilder o--> IMetric: metric
|
| 580 |
+
TrainerBuilder o--> Optimizer: optimizer
|
| 581 |
+
|
| 582 |
+
Trainer *--> NeuralNetwork: model
|
| 583 |
+
Trainer *--> Optimizer: optimizer
|
| 584 |
+
Trainer *--> ILossFunction: lossFunction
|
| 585 |
+
Trainer *--> IMetric: metric
|
| 586 |
+
|
| 587 |
+
%% Removido o namespace Data %%
|
| 588 |
+
class DataLoader {
|
| 589 |
+
-INDArray trainData
|
| 590 |
+
-INDArray testData
|
| 591 |
+
+DataLoader(String trainDataPath, String testDataPath)
|
| 592 |
+
+DataLoader(String trainX, String trainY, String testX, String testY)
|
| 593 |
+
+static INDArray loadCsv(String csvFile)
|
| 594 |
+
+INDArray getAllTrainImages()
|
| 595 |
+
+INDArray getAllTestImages()
|
| 596 |
+
+INDArray getAllTrainLabels()
|
| 597 |
+
+INDArray getAllTestLabels()
|
| 598 |
+
+INDArray getTrainImage(int index)
|
| 599 |
+
+INDArray getTestImage(int index)
|
| 600 |
+
+int getTrainLabel(int index)
|
| 601 |
+
+int getTestLabel(int index)
|
| 602 |
+
+INDArray getTrainData()
|
| 603 |
+
+INDArray getTestData()
|
| 604 |
+
}
|
| 605 |
+
|
| 606 |
+
class Util {
|
| 607 |
+
+static INDArray normalize(INDArray array)
|
| 608 |
+
+static INDArray unnormalize(INDArray array)
|
| 609 |
+
+static INDArray clip(INDArray array, double min, double max)
|
| 610 |
+
+static INDArray[][] trainTestSplit(INDArray x, INDArray y, double trainSize)
|
| 611 |
+
+static void printProgressBar(int current, int total)
|
| 612 |
+
+static INDArray oneHotEncode(INDArray labels, int numClasses)
|
| 613 |
+
+static WritableImage arrayToImage(INDArray imageArray, int WIDTH, int HEIGHT)
|
| 614 |
+
+static WritableImage byteArrayToImage(byte[] byteArray)
|
| 615 |
+
+static INDArray imageToINDArray(WritableImage writableImage, int width, int height)
|
| 616 |
+
+static INDArray bytesToINDArray(byte[] bytes, int width, int height)
|
| 617 |
+
+static INDArray confusionMatrix(INDArray predictions, INDArray labels)
|
| 618 |
+
}
|
| 619 |
+
|
| 620 |
+
class PlotDataPredict {
|
| 621 |
+
+void plot2d(INDArray x, INDArray y, INDArray predict, String title)
|
| 622 |
+
+void plot3dGridandScatter(INDArray x, INDArray y, INDArray predict, String title)
|
| 623 |
+
}
|
| 624 |
+
|
| 625 |
+
class DataProcessor {
|
| 626 |
+
<<abstract>>
|
| 627 |
+
+abstract void fit(INDArray data)
|
| 628 |
+
+abstract INDArray transform(INDArray data)
|
| 629 |
+
+abstract INDArray inverseTransform(INDArray data)
|
| 630 |
+
+INDArray fitTransform(INDArray data)
|
| 631 |
+
}
|
| 632 |
+
|
| 633 |
+
class DataPipeline {
|
| 634 |
+
-List processors %% Simplificado %%
|
| 635 |
+
+DataPipeline(List processors) %% Simplificado %%
|
| 636 |
+
+DataPipeline()
|
| 637 |
+
+void add(DataProcessor processor)
|
| 638 |
+
+void fit(INDArray data)
|
| 639 |
+
+INDArray transform(INDArray data)
|
| 640 |
+
+INDArray fitTransform(INDArray data)
|
| 641 |
+
+INDArray inverseTransform(INDArray data)
|
| 642 |
+
+List getProcessors() %% Simplificado %%
|
| 643 |
+
}
|
| 644 |
+
|
| 645 |
+
class StandardScaler {
|
| 646 |
+
-double mean, std
|
| 647 |
+
-static final double EPSILON
|
| 648 |
+
+void fit(INDArray data)
|
| 649 |
+
+INDArray transform(INDArray data)
|
| 650 |
+
+INDArray inverseTransform(INDArray data)
|
| 651 |
+
+double getMean()
|
| 652 |
+
+double getStd()
|
| 653 |
+
}
|
| 654 |
+
|
| 655 |
+
class MinMaxScaler {
|
| 656 |
+
-INDArray min, max
|
| 657 |
+
-final double minRange
|
| 658 |
+
-final double maxRange
|
| 659 |
+
+MinMaxScaler(double minRange, double maxRange)
|
| 660 |
+
+MinMaxScaler()
|
| 661 |
+
+void fit(INDArray data)
|
| 662 |
+
+INDArray transform(INDArray data)
|
| 663 |
+
+INDArray inverseTransform(INDArray data)
|
| 664 |
+
}
|
| 665 |
+
|
| 666 |
+
%% Removido o namespace Database %%
|
| 667 |
+
class NeuralNetworkService {
|
| 668 |
+
-final static String MONGODB_URI
|
| 669 |
+
-final Datastore datastore
|
| 670 |
+
+NeuralNetworkService()
|
| 671 |
+
+void saveModel(NeuralNetwork model)
|
| 672 |
+
+NeuralNetwork loadModel(String modelName)
|
| 673 |
+
+List getAllModels() %% Simplificado %%
|
| 674 |
+
}
|
| 675 |
+
|
| 676 |
+
DataProcessor <|-- StandardScaler
|
| 677 |
+
DataProcessor <|-- MinMaxScaler
|
| 678 |
+
DataProcessor <|-- DataPipeline
|
| 679 |
+
DataPipeline *--> DataProcessor: contains %% Cardinalidade simplificada %%
|
| 680 |
+
|
| 681 |
+
Trainer ..> Util: uses
|
| 682 |
+
Trainer ..> DataLoader: uses
|
| 683 |
+
TrainerBuilder ..> DataLoader: uses
|
| 684 |
+
|
| 685 |
+
NeuralNetwork ..> Util: uses
|
| 686 |
+
TrainableLayer ..> Util: uses
|
| 687 |
+
|
| 688 |
+
%% Removida relação models.NeuralNetwork %%
|
| 689 |
+
Trainer *--> DataLoader: loads data
|
| 690 |
+
|
| 691 |
+
NeuralNetwork --o NeuralNetworkService: manages %% Removido namespace Database %%
|
| 692 |
+
Layer ..> NeuralNetworkService: uses for persistence %% Removido namespace Database %%
|
| 693 |
+
NeuralNetworkService ..> Datastore: uses
|
| 694 |
+
```
|
assets/generic_eval_all.html
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
assets/hand_control_arm_video.mp4
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:46180485f0252f79f794fa37e73db029d0c7abe692ed967f417fb1d033a937b0
|
| 3 |
+
size 4119656
|
assets/heatmap_accuracy.html
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
assets/imav_mission_diagram.jpg
ADDED

|
Git LFS Details
|
assets/layers_diagram.md
ADDED
|
@@ -0,0 +1,152 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
```mermaid
|
| 2 |
+
classDiagram
|
| 3 |
+
namespace Layers {
|
| 4 |
+
class Layer {
|
| 5 |
+
<<abstract>>
|
| 6 |
+
#INDArray input
|
| 7 |
+
#INDArray output
|
| 8 |
+
#boolean inference
|
| 9 |
+
+INDArray forward(INDArray inputs)*
|
| 10 |
+
+INDArray backward(INDArray gradout)*
|
| 11 |
+
+Layer load(DataInputStream dis)
|
| 12 |
+
+void save(DataOutputStream dos)
|
| 13 |
+
+void saveAdditional(DataOutputStream dos)*
|
| 14 |
+
+Layer loadAdditional(DataInputStream dis)*
|
| 15 |
+
+void setInput(INDArray input)
|
| 16 |
+
+INDArray getInput()
|
| 17 |
+
+void setOutput(INDArray output)
|
| 18 |
+
+INDArray getOutput()
|
| 19 |
+
+void setInference(boolean inference)
|
| 20 |
+
+void save(Datastore datastore)
|
| 21 |
+
}
|
| 22 |
+
class Flatten {
|
| 23 |
+
+Flatten()
|
| 24 |
+
+INDArray forward(INDArray inputs)
|
| 25 |
+
+INDArray backward(INDArray gradout)
|
| 26 |
+
+String toString()
|
| 27 |
+
+Flatten loadAdditional(DataInputStream dis)
|
| 28 |
+
+void saveAdditional(DataOutputStream dos)
|
| 29 |
+
}
|
| 30 |
+
class Dropout {
|
| 31 |
+
-double dropoutRate
|
| 32 |
+
-INDArray mask
|
| 33 |
+
+Dropout(double dropoutRate)
|
| 34 |
+
+Dropout()
|
| 35 |
+
+INDArray forward(INDArray inputs)
|
| 36 |
+
+INDArray backward(INDArray gradout)
|
| 37 |
+
+String toString()
|
| 38 |
+
+double getDropoutRate()
|
| 39 |
+
+void setDropoutRate(double dropoutRate)
|
| 40 |
+
+INDArray getMask()
|
| 41 |
+
+void setMask(INDArray mask)
|
| 42 |
+
+void saveAdditional(DataOutputStream dos)
|
| 43 |
+
+Dropout loadAdditional(DataInputStream dis)
|
| 44 |
+
}
|
| 45 |
+
class ZeroPadding2D {
|
| 46 |
+
#int padding
|
| 47 |
+
+ZeroPadding2D(int padding)
|
| 48 |
+
+ZeroPadding2D()
|
| 49 |
+
+INDArray forward(INDArray inputs)
|
| 50 |
+
+INDArray backward(INDArray gradout)
|
| 51 |
+
+ZeroPadding2D loadAdditional(DataInputStream dis)
|
| 52 |
+
+void saveAdditional(DataOutputStream dos)
|
| 53 |
+
+String toString()
|
| 54 |
+
}
|
| 55 |
+
class MaxPooling2D {
|
| 56 |
+
-int poolSize
|
| 57 |
+
-int stride
|
| 58 |
+
+MaxPooling2D(int poolSize, int stride)
|
| 59 |
+
+MaxPooling2D()
|
| 60 |
+
+INDArray forward(INDArray inputs)
|
| 61 |
+
+INDArray backward(INDArray gradout)
|
| 62 |
+
+String toString()
|
| 63 |
+
+MaxPooling2D loadAdditional(DataInputStream dis)
|
| 64 |
+
+void saveAdditional(DataOutputStream dos)
|
| 65 |
+
}
|
| 66 |
+
class TrainableLayer {
|
| 67 |
+
<<abstract>>
|
| 68 |
+
#INDArray params
|
| 69 |
+
#INDArray grads
|
| 70 |
+
#boolean trainable
|
| 71 |
+
#byte[] paramsData
|
| 72 |
+
#byte[] gradsData
|
| 73 |
+
+void setup(INDArray input)
|
| 74 |
+
+INDArray getParams()
|
| 75 |
+
+void setParams(INDArray params)
|
| 76 |
+
+INDArray getGrads()
|
| 77 |
+
+void setGrads(INDArray grads)
|
| 78 |
+
+void setTrainable(boolean trainable)
|
| 79 |
+
+boolean isTrainable()
|
| 80 |
+
+void saveAdditional(DataOutputStream dos)
|
| 81 |
+
+TrainableLayer loadAdditional(DataInputStream dis)
|
| 82 |
+
}
|
| 83 |
+
class Dense {
|
| 84 |
+
-IActivation activation
|
| 85 |
+
-String activationType
|
| 86 |
+
-int units
|
| 87 |
+
-boolean isInitialized
|
| 88 |
+
-String kernelInitializer
|
| 89 |
+
-double lambda
|
| 90 |
+
+Dense(int units, IActivation activation, String kernelInitializer, double lambda)
|
| 91 |
+
+Dense(int units, IActivation activation, String kernelInitializer)
|
| 92 |
+
+Dense(int units, IActivation activation)
|
| 93 |
+
+Dense(int units)
|
| 94 |
+
+Dense()
|
| 95 |
+
+INDArray getWeights()
|
| 96 |
+
+INDArray getGradientWeights()
|
| 97 |
+
+INDArray getBias()
|
| 98 |
+
+INDArray getGradientBias()
|
| 99 |
+
+void setup(INDArray inputs)
|
| 100 |
+
+INDArray forward(INDArray inputs)
|
| 101 |
+
+INDArray backward(INDArray gradout)
|
| 102 |
+
+IActivation getActivation()
|
| 103 |
+
+int getUnits()
|
| 104 |
+
+String getKernelInitializer()
|
| 105 |
+
}
|
| 106 |
+
class Conv2D {
|
| 107 |
+
#int filters
|
| 108 |
+
#int kernelSize
|
| 109 |
+
#List<Integer> strides
|
| 110 |
+
#String padding
|
| 111 |
+
#IActivation activation
|
| 112 |
+
#String activationType
|
| 113 |
+
#String kernelInitializer
|
| 114 |
+
#int pad
|
| 115 |
+
#Layer<ZeroPadding2D> zeroPadding2D
|
| 116 |
+
#int m, nHInput, nWInput, nCInput
|
| 117 |
+
#int nHOutput, nWOutput, nCOutput
|
| 118 |
+
#boolean isInitialized
|
| 119 |
+
#INDArray paddedInputs
|
| 120 |
+
#INDArray weightsC, biasesC, aPrev, aSlicePrev
|
| 121 |
+
#int[] vert_starts, horiz_starts
|
| 122 |
+
+Conv2D(int filters, int kernelSize, List<Integer> strides, String padding, IActivation activation, String kernelInitializer)
|
| 123 |
+
+Conv2D(int filters, int kernelSize, String padding, IActivation activation, String kernelInitializer)
|
| 124 |
+
+Conv2D(int filters, int kernelSize, IActivation activation)
|
| 125 |
+
+Conv2D(int filters, int kernelSize)
|
| 126 |
+
+Conv2D()
|
| 127 |
+
+void setup(INDArray inputs)
|
| 128 |
+
+INDArray forward(INDArray inputs)
|
| 129 |
+
+INDArray backward(INDArray gradout)
|
| 130 |
+
+INDArray getWeights()
|
| 131 |
+
+INDArray getBiases()
|
| 132 |
+
+void setWeights(INDArray weights)
|
| 133 |
+
+void setBiases(INDArray biases)
|
| 134 |
+
+INDArray getGradWeights()
|
| 135 |
+
+INDArray getGradBiases()
|
| 136 |
+
}
|
| 137 |
+
class LayerLoader {
|
| 138 |
+
-Map<String>, Supplier<Layer> layerLoaders
|
| 139 |
+
+static Layer load(DataInputStream dis)
|
| 140 |
+
}
|
| 141 |
+
}
|
| 142 |
+
|
| 143 |
+
Layer <|-- TrainableLayer : extends
|
| 144 |
+
TrainableLayer <|-- Dense : extends
|
| 145 |
+
TrainableLayer <|-- Conv2D : extends
|
| 146 |
+
Layer <|-- Flatten : extends
|
| 147 |
+
Layer <|-- Dropout : extends
|
| 148 |
+
Layer <|-- MaxPooling2D : extends
|
| 149 |
+
Layer <|-- ZeroPadding2D : extends
|
| 150 |
+
Conv2D *-- ZeroPadding2D : uses
|
| 151 |
+
LayerLoader --> Layer : creates
|
| 152 |
+
```
|
assets/linear.png
ADDED

|
Git LFS Details
|
assets/losses_diagram.md
ADDED
|
@@ -0,0 +1,43 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
```mermaid
|
| 2 |
+
classDiagram
|
| 3 |
+
namespace Losses {
|
| 4 |
+
class ILossFunction {
|
| 5 |
+
<<interface>>
|
| 6 |
+
+INDArray forward(INDArray predicted, INDArray real)
|
| 7 |
+
+INDArray backward(INDArray predicted, INDArray real)
|
| 8 |
+
}
|
| 9 |
+
|
| 10 |
+
%% Concrete classes implementing ILossFunction
|
| 11 |
+
class MeanSquaredError {
|
| 12 |
+
+INDArray forward(INDArray predictions, INDArray labels)
|
| 13 |
+
+INDArray backward(INDArray predictions, INDArray labels)
|
| 14 |
+
}
|
| 15 |
+
|
| 16 |
+
class BinaryCrossEntropy {
|
| 17 |
+
+INDArray forward(INDArray predictions, INDArray labels)
|
| 18 |
+
+INDArray backward(INDArray predictions, INDArray labels)
|
| 19 |
+
}
|
| 20 |
+
|
| 21 |
+
class CategoricalCrossEntropy {
|
| 22 |
+
-double eps
|
| 23 |
+
+INDArray forward(INDArray predicted, INDArray real)
|
| 24 |
+
+INDArray backward(INDArray predicted, INDArray real)
|
| 25 |
+
}
|
| 26 |
+
|
| 27 |
+
class SoftmaxCrossEntropy {
|
| 28 |
+
-double eps
|
| 29 |
+
-boolean singleClass
|
| 30 |
+
-INDArray softmaxPreds
|
| 31 |
+
-Softmax softmax
|
| 32 |
+
+SoftmaxCrossEntropy()
|
| 33 |
+
+SoftmaxCrossEntropy(double eps)
|
| 34 |
+
+INDArray forward(INDArray predicted, INDArray real)
|
| 35 |
+
+INDArray backward(INDArray predicted, INDArray real)
|
| 36 |
+
}
|
| 37 |
+
}
|
| 38 |
+
|
| 39 |
+
ILossFunction <|.. MeanSquaredError
|
| 40 |
+
ILossFunction <|.. BinaryCrossEntropy
|
| 41 |
+
ILossFunction <|.. CategoricalCrossEntropy
|
| 42 |
+
ILossFunction <|.. SoftmaxCrossEntropy
|
| 43 |
+
```
|
assets/metrics_diagram.md
ADDED
|
@@ -0,0 +1,53 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
```mermaid
|
| 2 |
+
classDiagram
|
| 3 |
+
namespace Metrics {
|
| 4 |
+
class IMetric {
|
| 5 |
+
<<interface>>
|
| 6 |
+
+double evaluate(INDArray yTrue, INDArray yPred)
|
| 7 |
+
}
|
| 8 |
+
|
| 9 |
+
class MSE {
|
| 10 |
+
+double evaluate(INDArray yTrue, INDArray yPred)
|
| 11 |
+
}
|
| 12 |
+
|
| 13 |
+
class RMSE {
|
| 14 |
+
+double evaluate(INDArray yTrue, INDArray yPred)
|
| 15 |
+
}
|
| 16 |
+
|
| 17 |
+
class MAE {
|
| 18 |
+
+double evaluate(INDArray yTrue, INDArray yPred)
|
| 19 |
+
}
|
| 20 |
+
|
| 21 |
+
class R2 {
|
| 22 |
+
+double evaluate(INDArray yTrue, INDArray yPred)
|
| 23 |
+
}
|
| 24 |
+
|
| 25 |
+
class Accuracy {
|
| 26 |
+
+double evaluate(INDArray yTrue, INDArray yPred)
|
| 27 |
+
}
|
| 28 |
+
|
| 29 |
+
class Precision {
|
| 30 |
+
+double evaluate(INDArray yTrue, INDArray yPred)
|
| 31 |
+
}
|
| 32 |
+
|
| 33 |
+
class Recall {
|
| 34 |
+
+double evaluate(INDArray yTrue, INDArray yPred)
|
| 35 |
+
}
|
| 36 |
+
|
| 37 |
+
class F1Score {
|
| 38 |
+
+double evaluate(INDArray yTrue, INDArray yPred)
|
| 39 |
+
}
|
| 40 |
+
}
|
| 41 |
+
|
| 42 |
+
IMetric <|.. MSE
|
| 43 |
+
IMetric <|.. RMSE
|
| 44 |
+
IMetric <|.. MAE
|
| 45 |
+
IMetric <|.. R2
|
| 46 |
+
IMetric <|.. Accuracy
|
| 47 |
+
IMetric <|.. Precision
|
| 48 |
+
IMetric <|.. Recall
|
| 49 |
+
IMetric <|.. F1Score
|
| 50 |
+
|
| 51 |
+
F1Score ..> Precision
|
| 52 |
+
F1Score ..> Recall
|
| 53 |
+
```
|
assets/model_performance_by_category.html
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
assets/models_diagram.md
ADDED
|
@@ -0,0 +1,38 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
```mermaid
|
| 2 |
+
classDiagram
|
| 3 |
+
namespace models {
|
| 4 |
+
class ModelBuilder {
|
| 5 |
+
+layers: List<Layer>
|
| 6 |
+
+add(layer:Layer): ModelBuilder
|
| 7 |
+
+build(): NeuralNetwork
|
| 8 |
+
}
|
| 9 |
+
class NeuralNetwork {
|
| 10 |
+
+id: ObjectId
|
| 11 |
+
+name: String = "neural_network_" + UUID.randomUUID()
|
| 12 |
+
#layers: List<Layer>
|
| 13 |
+
-trainableLayers: List<TrainableLayer>
|
| 14 |
+
-output: INDArray
|
| 15 |
+
+NeuralNetwork(modelBuilder:ModelBuilder)
|
| 16 |
+
#NeuralNetwork()
|
| 17 |
+
+initTrainableLayers()
|
| 18 |
+
+getId(): ObjectId
|
| 19 |
+
+setName(name:String): void
|
| 20 |
+
+getName(): String
|
| 21 |
+
+predict(x:INDArray): INDArray
|
| 22 |
+
+backPropagation(gradout:INDArray): void
|
| 23 |
+
+getLayers(): List<Layer>
|
| 24 |
+
+getTrainableLayers(): List<TrainableLayer>
|
| 25 |
+
-setLayers(layers:List<Layer>): void
|
| 26 |
+
+setTrainable(trainable:boolean): void
|
| 27 |
+
+setInference(inference:boolean): void
|
| 28 |
+
+saveModel(String filePath): void
|
| 29 |
+
+static loadModel(String filePath): NeuralNetwork
|
| 30 |
+
}
|
| 31 |
+
}
|
| 32 |
+
|
| 33 |
+
%% Relationships for models namespace
|
| 34 |
+
ModelBuilder --> NeuralNetwork: builds >
|
| 35 |
+
ModelBuilder *--> "1..*" Layer: contains >
|
| 36 |
+
NeuralNetwork *--> "1..*" Layer: contains >
|
| 37 |
+
NeuralNetwork *--> "0..*" TrainableLayer: contains >
|
| 38 |
+
```
|
assets/optimizers_diagram.md
ADDED
|
@@ -0,0 +1,164 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
```mermaid
|
| 2 |
+
classDiagram
|
| 3 |
+
namespace Optimizers {
|
| 4 |
+
class Optimizer {
|
| 5 |
+
<<abstract>>
|
| 6 |
+
#NeuralNetwork neuralNetwork
|
| 7 |
+
#LearningRateDecayStrategy learningRateDecayStrategy
|
| 8 |
+
#double learningRate
|
| 9 |
+
#Map<TrainableLayer, List<INDArray> auxParams
|
| 10 |
+
#List<TrainableLayer> trainableLayers
|
| 11 |
+
-boolean initialized
|
| 12 |
+
|
| 13 |
+
+Optimizer()
|
| 14 |
+
#Optimizer(double learningRate)
|
| 15 |
+
+Optimizer(LearningRateDecayStrategy learningRateDecayStrategy)
|
| 16 |
+
+Optimizer(NeuralNetwork neuralNetwork)
|
| 17 |
+
+setNeuralNetwork(NeuralNetwork neuralNetwork)
|
| 18 |
+
#init()
|
| 19 |
+
+update()
|
| 20 |
+
+updateEpoch()
|
| 21 |
+
#abstract List<INDArray> createAuxParams(INDArray params)
|
| 22 |
+
#abstract void updateRule(INDArray params, INDArray grads, List<INDArray> auxParams)
|
| 23 |
+
}
|
| 24 |
+
|
| 25 |
+
%% Learning Rate Decay Strategies
|
| 26 |
+
class LearningRateDecayStrategy {
|
| 27 |
+
<<abstract>>
|
| 28 |
+
#double decayPerEpoch
|
| 29 |
+
#double learningRate
|
| 30 |
+
|
| 31 |
+
+LearningRateDecayStrategy(double initialRate, double finalRate, int epochs)
|
| 32 |
+
#abstract double calculateDecayPerEpoch(double initialRate, double finalRate, int epochs)
|
| 33 |
+
+abstract double updateLearningRate()
|
| 34 |
+
}
|
| 35 |
+
|
| 36 |
+
class ExponentialDecayStrategy {
|
| 37 |
+
+ExponentialDecayStrategy(double initialRate, double finalRate, int epochs)
|
| 38 |
+
#double calculateDecayPerEpoch(double initialRate, double finalRate, int epochs)
|
| 39 |
+
+double updateLearningRate()
|
| 40 |
+
}
|
| 41 |
+
|
| 42 |
+
class LinearDecayStrategy {
|
| 43 |
+
+LinearDecayStrategy(double initialRate, double finalRate, int epochs)
|
| 44 |
+
#double calculateDecayPerEpoch(double initialRate, double finalRate, int epochs)
|
| 45 |
+
+double updateLearningRate()
|
| 46 |
+
}
|
| 47 |
+
|
| 48 |
+
%% SGD Optimizers
|
| 49 |
+
class SGD {
|
| 50 |
+
+SGD(double learningRate)
|
| 51 |
+
+SGD(LearningRateDecayStrategy learningRateDecayStrategy)
|
| 52 |
+
+SGD()
|
| 53 |
+
#List<INDArray< createAuxParams(INDArray params)
|
| 54 |
+
#void updateRule(INDArray params, INDArray grads, List<INDArray> auxParams)
|
| 55 |
+
}
|
| 56 |
+
|
| 57 |
+
class SGDMomentum {
|
| 58 |
+
-double momentum
|
| 59 |
+
-INDArray velocities
|
| 60 |
+
|
| 61 |
+
+SGDMomentum(double learningRate, double momentum)
|
| 62 |
+
+SGDMomentum(double learningRate)
|
| 63 |
+
+SGDMomentum(LearningRateDecayStrategy learningRateDecayStrategy, double momentum)
|
| 64 |
+
+SGDMomentum(LearningRateDecayStrategy learningRateDecayStrategy)
|
| 65 |
+
#List<INDArray> createAuxParams(INDArray params)
|
| 66 |
+
#void updateRule(INDArray params, INDArray grads, List<INDArray> auxParams)
|
| 67 |
+
}
|
| 68 |
+
|
| 69 |
+
class SGDNesterov {
|
| 70 |
+
-double momentum
|
| 71 |
+
-INDArray velocities
|
| 72 |
+
|
| 73 |
+
+SGDNesterov(double learningRate, double momentum)
|
| 74 |
+
+SGDNesterov(double learningRate)
|
| 75 |
+
+SGDNesterov(LearningRateDecayStrategy learningRateDecayStrategy, double momentum)
|
| 76 |
+
+SGDNesterov(LearningRateDecayStrategy learningRateDecayStrategy)
|
| 77 |
+
#List<INDArray> createAuxParams(INDArray params)
|
| 78 |
+
#void updateRule(INDArray params, INDArray grads, List<INDArray> auxParams)
|
| 79 |
+
}
|
| 80 |
+
|
| 81 |
+
class RegularizedSGD {
|
| 82 |
+
-double alpha
|
| 83 |
+
|
| 84 |
+
+RegularizedSGD(double learningRate, double alpha)
|
| 85 |
+
+RegularizedSGD()
|
| 86 |
+
+RegularizedSGD(double learningRate)
|
| 87 |
+
+RegularizedSGD(LearningRateDecayStrategy learningRateDecayStrategy)
|
| 88 |
+
+RegularizedSGD(LearningRateDecayStrategy learningRateDecayStrategy, double alpha)
|
| 89 |
+
#List<INDArray> createAuxParams(INDArray params)
|
| 90 |
+
#void updateRule(INDArray params, INDArray grads, List<INDArray> auxParams)
|
| 91 |
+
}
|
| 92 |
+
|
| 93 |
+
%% Adaptive optimizers
|
| 94 |
+
class AdaGrad {
|
| 95 |
+
-double eps
|
| 96 |
+
-INDArray sumSquares
|
| 97 |
+
|
| 98 |
+
+AdaGrad(double lr)
|
| 99 |
+
+AdaGrad()
|
| 100 |
+
+AdaGrad(LearningRateDecayStrategy learningRateDecayStrategy)
|
| 101 |
+
#List<INDArray> createAuxParams(INDArray params)
|
| 102 |
+
#void updateRule(INDArray params, INDArray grads, List<INDArray> auxParams)
|
| 103 |
+
}
|
| 104 |
+
|
| 105 |
+
class RMSProp {
|
| 106 |
+
-double decayRate
|
| 107 |
+
-double epsilon
|
| 108 |
+
-INDArray accumulator
|
| 109 |
+
|
| 110 |
+
+RMSProp(double learningRate, double decayRate, double epsilon)
|
| 111 |
+
+RMSProp(LearningRateDecayStrategy learningRateDecayStrategy, double decayRate, double epsilon)
|
| 112 |
+
+RMSProp(LearningRateDecayStrategy learningRateDecayStrategy)
|
| 113 |
+
+RMSProp()
|
| 114 |
+
+RMSProp(double learningRate, double decayRate)
|
| 115 |
+
+RMSProp(double learningRate)
|
| 116 |
+
#List<INDArray> createAuxParams(INDArray params)
|
| 117 |
+
#void updateRule(INDArray params, INDArray grads, List<INDArray> auxParams)
|
| 118 |
+
}
|
| 119 |
+
|
| 120 |
+
class Adam {
|
| 121 |
+
-double beta1
|
| 122 |
+
-double beta2
|
| 123 |
+
-double epsilon
|
| 124 |
+
-INDArray m
|
| 125 |
+
-INDArray v
|
| 126 |
+
-int t
|
| 127 |
+
|
| 128 |
+
+Adam(double learningRate, double beta1, double beta2, double epsilon)
|
| 129 |
+
+Adam(double learningRate)
|
| 130 |
+
+Adam()
|
| 131 |
+
+Adam(LearningRateDecayStrategy learningRateDecayStrategy, double beta1, double beta2, double epsilon)
|
| 132 |
+
+Adam(LearningRateDecayStrategy learningRateDecayStrategy)
|
| 133 |
+
#List<INDArray> createAuxParams(INDArray params)
|
| 134 |
+
#void updateRule(INDArray params, INDArray grads, List<INDArray<=> auxParams)
|
| 135 |
+
}
|
| 136 |
+
|
| 137 |
+
class AdaDelta {
|
| 138 |
+
-double decayRate
|
| 139 |
+
-double epsilon
|
| 140 |
+
-INDArray accumulator
|
| 141 |
+
-INDArray delta
|
| 142 |
+
|
| 143 |
+
+AdaDelta(double decayRate, double epsilon)
|
| 144 |
+
+AdaDelta(double decayRate)
|
| 145 |
+
+AdaDelta()
|
| 146 |
+
#List<INDArray> createAuxParams(INDArray params)
|
| 147 |
+
#void updateRule(INDArray params, INDArray grads, List<INDArray> auxParams)
|
| 148 |
+
}
|
| 149 |
+
}
|
| 150 |
+
|
| 151 |
+
Optimizer <|-- SGD
|
| 152 |
+
Optimizer <|-- SGDMomentum
|
| 153 |
+
Optimizer <|-- SGDNesterov
|
| 154 |
+
Optimizer <|-- RegularizedSGD
|
| 155 |
+
Optimizer <|-- AdaGrad
|
| 156 |
+
Optimizer <|-- RMSProp
|
| 157 |
+
Optimizer <|-- Adam
|
| 158 |
+
Optimizer <|-- AdaDelta
|
| 159 |
+
|
| 160 |
+
LearningRateDecayStrategy <|-- LinearDecayStrategy
|
| 161 |
+
LearningRateDecayStrategy <|-- ExponentialDecayStrategy
|
| 162 |
+
|
| 163 |
+
Optimizer o-- LearningRateDecayStrategy
|
| 164 |
+
```
|
assets/profile.jpg
ADDED

|
Git LFS Details
|
assets/quickdraw_game_video.mp4
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:9325d4ad7cfaa771e22c06de3d939922c4fff6f3e88920317ef1bb1488e78d68
|
| 3 |
+
size 18380238
|
assets/robotic_arm.jpg
ADDED

|
Git LFS Details
|
assets/rosenbrock2.png
ADDED

|
Git LFS Details
|
assets/saddle_function2.png
ADDED

|
Git LFS Details
|
assets/signature_article.md
ADDED
|
@@ -0,0 +1,588 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Open-Source Handwritten Signature Detection Model
|
| 2 |
+
|
| 3 |
+
<div style="text-align: justify;">
|
| 4 |
+
|
| 5 |
+
## Abstract
|
| 6 |
+
|
| 7 |
+
<div style="
|
| 8 |
+
display: flex;
|
| 9 |
+
gap: 24px;
|
| 10 |
+
margin: 2em 0;
|
| 11 |
+
line-height: 1.6;
|
| 12 |
+
">
|
| 13 |
+
|
| 14 |
+
<!-- Left Column - Text -->
|
| 15 |
+
<div style="flex: 1; padding-right: 16px;">
|
| 16 |
+
<p style="font-size: 1.1rem; margin-bottom: 1em;">
|
| 17 |
+
This article presents an <strong>open-source project</strong> for automated signature detection in document processing, structured into four key phases:
|
| 18 |
+
</p>
|
| 19 |
+
<ul style="padding-left: 20px; margin-bottom: 1em; font-size: 1rem;">
|
| 20 |
+
<li><strong>Dataset Engineering:</strong> Curation of a hybrid dataset through aggregation of two public collections.</li>
|
| 21 |
+
<li><strong>Architecture Benchmarking:</strong> Systematic evaluation of state-of-the-art object detection architectures (<em>YOLO series, DETR variants, and YOLOS</em>), focusing on accuracy, computational efficiency, and deployment constraints.</li>
|
| 22 |
+
<li><strong>Model Optimization:</strong> Leveraged Optuna for hyperparameter tuning, yielding a 7.94% F1-score improvement over baseline configurations.</li>
|
| 23 |
+
<li><strong>Production Deployment:</strong> Utilized Triton Inference Server for OpenVINO CPU-optimized inference.</li>
|
| 24 |
+
</ul>
|
| 25 |
+
<p style="font-size: 1.1rem; margin-top: 1em;">
|
| 26 |
+
Experimental results demonstrate a robust balance between precision, recall, and inference speed, validating the solution's practicality for real-world applications.
|
| 27 |
+
</p>
|
| 28 |
+
</div>
|
| 29 |
+
|
| 30 |
+
<!-- Right Column - Images -->
|
| 31 |
+
<div style="
|
| 32 |
+
flex: 1;
|
| 33 |
+
display: flex;
|
| 34 |
+
flex-direction: column;
|
| 35 |
+
gap: 12px;
|
| 36 |
+
">
|
| 37 |
+
<img src="https://cdn-uploads.huggingface.co/production/uploads/666b9ef5e6c60b6fc4156675/6AnC1ut7EOLa6EjibXZXY.webp"
|
| 38 |
+
style="max-width: 100%; height: auto; border-radius: 8px; box-shadow: 0 4px 8px rgba(0,0,0,0.1);">
|
| 39 |
+
<div style="display: flex; gap: 12px;">
|
| 40 |
+
<img src="https://cdn-uploads.huggingface.co/production/uploads/666b9ef5e6c60b6fc4156675/jWxcAUZPt8Bzup8kL-bor.webp"
|
| 41 |
+
style="flex: 1; max-width: 50%; height: auto; border-radius: 8px; box-shadow: 0 4px 8px rgba(0,0,0,0.1);">
|
| 42 |
+
<img src="https://cdn-uploads.huggingface.co/production/uploads/666b9ef5e6c60b6fc4156675/tzK0lJz7mI2fazpY9pB1w.webp"
|
| 43 |
+
style="flex: 1; max-width: 50%; height: auto; border-radius: 8px; box-shadow: 0 4px 8px rgba(0,0,0,0.1);">
|
| 44 |
+
</div>
|
| 45 |
+
</div>
|
| 46 |
+
|
| 47 |
+
</div>
|
| 48 |
+
|
| 49 |
+
|
| 50 |
+
|
| 51 |
+
<table style="width: 100%; border-collapse: collapse; margin: 25px 0; font-family: 'Segoe UI', sans-serif; font-size: 0.9em;">
|
| 52 |
+
<caption style="font-size: 1.1em; font-weight: 600; margin-bottom: 15px; caption-side: top;">Table 1: Key Research Features</caption>
|
| 53 |
+
<thead>
|
| 54 |
+
<tr style= border-bottom: 2px solid #dee2e6;">
|
| 55 |
+
<th style="padding: 12px 15px; text-align: left; width: 20%;">Resource</th>
|
| 56 |
+
<th style="padding: 12px 15px; text-align: left; width: 35%;">Links / Badges</th>
|
| 57 |
+
<th style="padding: 12px 15px; text-align: left; width: 45%;">Details</th>
|
| 58 |
+
</tr>
|
| 59 |
+
</thead>
|
| 60 |
+
<tbody>
|
| 61 |
+
<tr style="border-bottom: 1px solid #dee2e6;">
|
| 62 |
+
<td style="padding: 12px 15px; vertical-align: top;"><strong>Model Files</strong></td>
|
| 63 |
+
<td style="padding: 12px 15px; vertical-align: top;">
|
| 64 |
+
<a href="https://huggingface.co/tech4humans/yolov8s-signature-detector" target="_blank">
|
| 65 |
+
<img src="https://huggingface.co/datasets/huggingface/badges/resolve/main/model-on-hf-md.svg" alt="HF Model" style="height:24px; margin-right:8px;">
|
| 66 |
+
</a>
|
| 67 |
+
</td>
|
| 68 |
+
<td style="padding: 12px 15px; vertical-align: top;">
|
| 69 |
+
Different formats of the final models<br>
|
| 70 |
+
<span style="display: inline-flex; gap: 8px; margin-top: 6px;">
|
| 71 |
+
<a href="https://pytorch.org/" target="_blank"><img src="https://img.shields.io/badge/PyTorch-%23EE4C2C.svg?style=flat&logo=PyTorch&logoColor=white" alt="PyTorch"></a>
|
| 72 |
+
<a href="https://onnx.ai/" target="_blank"><img src="https://img.shields.io/badge/ONNX-005CED.svg?style=flat&logo=ONNX&logoColor=white" alt="ONNX"></a>
|
| 73 |
+
<a href="https://developer.nvidia.com/tensorrt" target="_blank"><img src="https://img.shields.io/badge/TensorRT-76B900.svg?style=flat&logo=NVIDIA&logoColor=white" alt="TensorRT"></a>
|
| 74 |
+
</span>
|
| 75 |
+
</td>
|
| 76 |
+
</tr>
|
| 77 |
+
|
| 78 |
+
<tr style="border-bottom: 1px solid #dee2e6;">
|
| 79 |
+
<td style="padding: 12px 15px; vertical-align: top;"><strong>Dataset – Original</strong></td>
|
| 80 |
+
<td style="padding: 12px 15px; vertical-align: top;">
|
| 81 |
+
<a href="https://universe.roboflow.com/tech-ysdkk/signature-detection-hlx8j" target="_blank">
|
| 82 |
+
<img src="https://app.roboflow.com/images/download-dataset-badge.svg" alt="Roboflow" style="height:24px;">
|
| 83 |
+
</a>
|
| 84 |
+
</td>
|
| 85 |
+
<td style="padding: 12px 15px; vertical-align: top;">2,819 document images annotated with signature coordinates</td>
|
| 86 |
+
</tr>
|
| 87 |
+
|
| 88 |
+
<tr style="border-bottom: 1px solid #dee2e6;">
|
| 89 |
+
<td style="padding: 12px 15px; vertical-align: top;"><strong>Dataset – Processed</strong></td>
|
| 90 |
+
<td style="padding: 12px 15px; vertical-align: top;">
|
| 91 |
+
<a href="https://huggingface.co/datasets/tech4humans/signature-detection" target="_blank">
|
| 92 |
+
<img src="https://huggingface.co/datasets/huggingface/badges/resolve/main/dataset-on-hf-md.svg" alt="HF Dataset" style="height:24px;">
|
| 93 |
+
</a>
|
| 94 |
+
</td>
|
| 95 |
+
<td style="padding: 12px 15px; vertical-align: top;">Augmented and pre-processed version (640px) for model training</td>
|
| 96 |
+
</tr>
|
| 97 |
+
|
| 98 |
+
<tr style="border-bottom: 1px solid #dee2e6;">
|
| 99 |
+
<td style="padding: 12px 15px; vertical-align: top;"><strong>Notebooks – Model Experiments</strong></td>
|
| 100 |
+
<td style="padding: 12px 15px; vertical-align: top;">
|
| 101 |
+
<span style="display: inline-flex; gap: 8px;">
|
| 102 |
+
<a href="https://colab.research.google.com/drive/1wSySw_zwyuv6XSaGmkngI4dwbj-hR4ix" target="_blank">
|
| 103 |
+
<img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Colab" style="height:24px;">
|
| 104 |
+
</a>
|
| 105 |
+
<a href="https://api.wandb.ai/links/samuel-lima-tech4humans/30cmrkp8" target="_blank">
|
| 106 |
+
<img src="https://img.shields.io/badge/W%26B_Training-FFBE00?style=flat&logo=WeightsAndBiases&logoColor=white" alt="W&B Training" style="height:24px;">
|
| 107 |
+
</a>
|
| 108 |
+
</span>
|
| 109 |
+
</td>
|
| 110 |
+
<td style="padding: 12px 15px; vertical-align: top;">Complete training and evaluation pipeline with selection among different architectures (yolo, detr, rt-detr, conditional-detr, yolos)</td>
|
| 111 |
+
</tr>
|
| 112 |
+
|
| 113 |
+
<tr style="border-bottom: 1px solid #dee2e6;">
|
| 114 |
+
<td style="padding: 12px 15px; vertical-align: top;"><strong>Notebooks – HP Tuning</strong></td>
|
| 115 |
+
<td style="padding: 12px 15px; vertical-align: top;">
|
| 116 |
+
<span style="display: inline-flex; gap: 8px;">
|
| 117 |
+
<a href="https://colab.research.google.com/drive/1wSySw_zwyuv6XSaGmkngI4dwbj-hR4ix" target="_blank">
|
| 118 |
+
<img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Colab" style="height:24px;">
|
| 119 |
+
</a>
|
| 120 |
+
<a href="https://api.wandb.ai/links/samuel-lima-tech4humans/31a6zhb1" target="_blank">
|
| 121 |
+
<img src="https://img.shields.io/badge/W%26B_HP_Tuning-FFBE00?style=flat&logo=WeightsAndBiases&logoColor=white" alt="W&B HP Tuning" style="height:24px;">
|
| 122 |
+
</a>
|
| 123 |
+
</span>
|
| 124 |
+
</td>
|
| 125 |
+
<td style="padding: 12px 15px; vertical-align: top;">Optuna trials for optimizing the precision/recall balance</td>
|
| 126 |
+
</tr>
|
| 127 |
+
|
| 128 |
+
<tr style="border-bottom: 1px solid #dee2e6;">
|
| 129 |
+
<td style="padding: 12px 15px; vertical-align: top;"><strong>Inference Server</strong></td>
|
| 130 |
+
<td style="padding: 12px 15px; vertical-align: top;">
|
| 131 |
+
<a href="https://github.com/tech4ai/t4ai-signature-detect-server" target="_blank">
|
| 132 |
+
<img src="https://img.shields.io/badge/Deploy-ffffff?style=for-the-badge&logo=github&logoColor=black" alt="GitHub" style="height:24px;">
|
| 133 |
+
</a>
|
| 134 |
+
</td>
|
| 135 |
+
<td style="padding: 12px 15px; vertical-align: top;">
|
| 136 |
+
Complete deployment and inference pipeline with Triton Inference Server<br>
|
| 137 |
+
<span style="display: inline-flex; gap: 8px; margin-top: 6px;">
|
| 138 |
+
<a href="https://docs.openvino.ai/2025/index.html" target="_blank"><img src="https://img.shields.io/badge/OpenVINO-00c7fd?style=flat&logo=intel&logoColor=white" alt="OpenVINO"></a>
|
| 139 |
+
<a href="https://www.docker.com/" target="_blank"><img src="https://img.shields.io/badge/Docker-2496ED?logo=docker&logoColor=fff" alt="Docker"></a>
|
| 140 |
+
<a href="https://developer.nvidia.com/triton-inference-server" target="_blank"><img src="https://img.shields.io/badge/Triton-Inference%20Server-76B900?labelColor=black&logo=nvidia" alt="Triton"></a>
|
| 141 |
+
</span>
|
| 142 |
+
</td>
|
| 143 |
+
</tr>
|
| 144 |
+
|
| 145 |
+
<tr style="border-bottom: 1px solid #dee2e6;">
|
| 146 |
+
<td style="padding: 12px 15px; vertical-align: top;"><strong>Live Demo</strong></td>
|
| 147 |
+
<td style="padding: 12px 15px; vertical-align: top;">
|
| 148 |
+
<a href="https://huggingface.co/spaces/tech4humans/signature-detection" target="_blank">
|
| 149 |
+
<img src="https://huggingface.co/datasets/huggingface/badges/resolve/main/open-in-hf-spaces-md.svg" alt="HF Space" style="height:24px;">
|
| 150 |
+
</a>
|
| 151 |
+
</td>
|
| 152 |
+
<td style="padding: 12px 15px; vertical-align: top;">
|
| 153 |
+
Graphical interface with real-time inference<br>
|
| 154 |
+
<span style="display: inline-flex; gap: 8px; margin-top: 6px;">
|
| 155 |
+
<a href="https://www.gradio.app/" target="_blank"><img src="https://img.shields.io/badge/Gradio-FF5722?style=flat&logo=Gradio&logoColor=white" alt="Gradio"></a>
|
| 156 |
+
<a href="https://plotly.com/python/" target="_blank"><img src="https://img.shields.io/badge/PLotly-000000?style=flat&logo=plotly&logoColor=white" alt="Plotly"></a>
|
| 157 |
+
</span>
|
| 158 |
+
</td>
|
| 159 |
+
</tr>
|
| 160 |
+
</tbody>
|
| 161 |
+
</table>
|
| 162 |
+
|
| 163 |
+
---
|
| 164 |
+
|
| 165 |
+
## 1\. Introduction
|
| 166 |
+
|
| 167 |
+
The application of automation in document processing has received much attention in both industry and academia. In this context, handwritten signature detection presents certain challenges, including orientation, lighting, noise, document layout, cursive letters in the document content, signatures in varying positions, among others. This paper describes the end-to-end development of a model for this task, including architecture selection, dataset creation, hyperparameter optimization, and production deployment.
|
| 168 |
+
|
| 169 |
+
---
|
| 170 |
+
|
| 171 |
+
## 2\. Methodology
|
| 172 |
+
|
| 173 |
+
### 2.1 Object Detection Architectures
|
| 174 |
+
|
| 175 |
+
Object detection in computer vision has improved significantly, balancing speed and precision for use cases such as autonomous driving and surveillance applications.
|
| 176 |
+
|
| 177 |
+
The field has evolved rapidly, with architectures generally falling into certain paradigms:
|
| 178 |
+
|
| 179 |
+
* CNN-based Two-Stage Detectors: Models from the R-CNN family first identify potential object regions before classifying them
|
| 180 |
+
* CNN-based One-Stage Detectors: YOLO family and SSD models that predict bounding boxes and classes in one pass
|
| 181 |
+
* Transformer-based Detectors: DETR-based models applying attention mechanisms for end-to-end detection
|
| 182 |
+
* Hybrid Architectures: Systems that combine CNN efficiency with Transformer contextual understanding
|
| 183 |
+
* Zero-shot Detectors: Capable of recognizing unfamiliar object classes without specific training
|
| 184 |
+
|
| 185 |
+
| Model | Architecture/Design | Latency | Applications | Precision (mAP) – Size Variants | Training Frameworks | License | Parameters (M) |
|
| 186 |
+
|-------|------------------|---------|--------------|--------------------------------|---------------------|---------|----------------|
|
| 187 |
+
| [YOLOv8](https://docs.ultralytics.com/models/yolov8/) | CNN (One-Stage), Yolov5 adapt -> C2f Block, SSPF and decoupled head | Very Low (1.47-14.37) [T4 GPU, TensorRT FP16]| Real-time detection, tracking | 37.4–53.9 [n-x] (COCO) | PyTorch, Ultralytics, KerasCV, TensorFlow | AGPL-3.0 | 3.2–68.2 |
|
| 188 |
+
| [YOLOv9](https://docs.ultralytics.com/models/yolov9/) | CNN, GELAN (Generalized Efficient Layer Aggregation Network), Programmable Gradient Information (PGI), CSP-ELAN blocks | Low (2.3-16.77) [T4 GPU, TensorRT FP16] | Real-time detection | 38.3–55.6 [t-e] (COCO) | PyTorch, Ultralytics | GPL-3.0 | 4.5–71.0 |
|
| 189 |
+
| [YOLOv10](https://docs.ultralytics.com/models/yolov10/) | CNN, Consistent Dual Assignments, Holistic Efficiency-Accuracy Design (Lightweight Head, Decoupled Downsampling, Rank-guided Blocks, Large-kernel Conv, Partial Self-Attention) | Very Low (1.84–10.79 ms) [T4 GPU, TensorRT FP16]| Real-time detection | 38.5–54.4 [n-x] (COCO) | PyTorch, Ultralytics | AGPL-3.0 | 2.3–29.5 |
|
| 190 |
+
| [YOLO11](https://docs.ultralytics.com/models/yolo11/) | CNN + Attention, PSA, Dual Label Assignment, C3K2 block | Very Low (1.5-11.3) [T4 GPU, TensorRT FP16] | Real-time detection | 43.5–58.5 [n-x] (COCO) | PyTorch, Ultralytics | AGPL-3.0 | 5.9–89.7 |
|
| 191 |
+
| [RTMDet](https://github.com/open-mmlab/mmdetection/tree/main/configs/rtmdet) | CNN (One-Stage), CSPDarkNet, CSP-PAFPN neck, soft label dynamic assignment | Low (2.34–18.8 ms) [T4 GPU, TensorRT FP16] | Real-time detection | 41.1–52.8 [tiny-x] (COCO) | PyTorch, MMDetection | Apache-2.0 | 4.8–94.9 |
|
| 192 |
+
| [DETR](https://huggingface.co/docs/transformers/model_doc/detr) | Transformer (Encoder-Decoder), CNN Backbone (ResNet), Bipartite Matching Loss, Set-based Prediction | Moderate (12–28 ms) [T4 GPU, TensorRT FP16] | Object detection | 42.0–44.0 [R50-R101] (COCO) | PyTorch, Hugging Face, PaddlePaddle | Apache-2.0 | 41–60 |
|
| 193 |
+
| [RT-DETR](https://github.com/PaddlePaddle/PaddleDetection/tree/develop/configs/rtdetr) | Transformer (Encoder-Decoder), Efficient Hybrid Encoder, Uncertainty-Minimal Query Selection, CNN Backbone (ResNet) | Very Low 9.3–13.5 ms (108–74 FPS) [T4 GPU, TensorRT FP16] | Real-time detection | 53.1–56.2 AP [R50-R101] (COCO) | PyTorch, Hugging Face, PaddlePaddle, Ultralytics | Apache-2.0 | 20.0–67.0 |
|
| 194 |
+
| [DETA](https://github.com/jozhang97/DETA) | Transformer (Two-Stage), CNN Backbone, IoU-based Label Assignment, NMS for Post-Processing | Moderate ~100 ms [V100 GPU] | High-precision detection | 50.1-62.9 (COCO) | PyTorch, Detectron2, Hugging Face | Apache-2.0 | 48–52 |
|
| 195 |
+
| [GroundingDINO](https://github.com/IDEA-Research/GroundingDINO) | Transformer-based (DINO + grounded pre-training), dual-encoder-single-decoder, Swin-T/Swin-L image backbone, BERT text backbone, feature enhancer, language-guided query selection, cross-modality decoder | ~119 ms (8.37 FPS on T4 GPU)* | Open-set detection | 52.5 AP (COCO zero-shot), 62.6–63.0 AP (COCO fine-tuned) [Swin-T (172M) / Swin-L (341M)] (COCO) | PyTorch, Hugging Face | Apache-2.0 | 172–341 |
|
| 196 |
+
| [YOLOS](https://github.com/hustvl/YOLOS) | Vision Transformer (ViT) with detection tokens, encoder-only, bipartite matching loss, minimal 2D inductive biases | Moderate (11.9–370.4 ms) [1080Ti GPU] | Object detection | 28.7–42.0 [Tiny-Base] (COCO) | PyTorch, Hugging Face | Apache-2.0 | 6.5–127 |
|
| 197 |
+
<div style="text-align: center; font-size: smaller;">
|
| 198 |
+
<strong>Table 2: Main Neural Network Architectures for Object Detection</strong>
|
| 199 |
+
</div>
|
| 200 |
+
|
| 201 |
+
> Check this leaderboard for the latest updates on object detection models: [Object Detection Leaderboard](https://leaderboard.roboflow.com/?ref=blog.roboflow.com).
|
| 202 |
+
|
| 203 |
+
#### Background and Evolution
|
| 204 |
+
Object detection has evolved from the conventional CNN-based models like Faster R-CNN and SSD to more recent transformer-based models like DETR, released in 2020 by Facebook AI. This is targeted at enhancing accuracy through the application of transformer models, which possess a superior capacity for handling global context. Recent models like RT-DETR and YOLOv11 continue to refine this balance, focusing on real-time performance and precision.
|
| 205 |
+
|
| 206 |
+
##### **YOLO Series**
|
| 207 |
+
|
| 208 |
+
**You Only Look Once (YOLO)** was introduced in 2016 by Joseph Redmon, Santosh Divvala, Ross Girshick, and Ali Farhadi, revolutionizing object detection by proposing a *single-stage detector*. While two-stage approaches first create region proposals and then classify and classify them, YOLO predicts *bounding boxes* and object classes in a single pass of the network. This design makes YOLO very fast and ideal for edge devices and real-time computing tasks like security surveillance, traffic monitoring, and industrial inspection.
|
| 209 |
+
|
| 210 |
+

|
| 211 |
+
<div style="text-align: center; font-size: smaller;">
|
| 212 |
+
<strong>Figure 1: YOLO family timeline.<br> Source: <a href="https://blog.roboflow.com/guide-to-yolo-models/">What is YOLO? The Ultimate Guide [2025]</a></strong>
|
| 213 |
+
</div>
|
| 214 |
+
|
| 215 |
+
Year after year, the YOLO family has been improved over and over again. Each version had new methods and advancements to compensate for the others' weaknesses:
|
| 216 |
+
|
| 217 |
+
- **YOLOv1:** First to remove region proposals by scanning the entire image in one forward pass, grabbing both global and local context at once.
|
| 218 |
+
- **YOLOv2 and YOLOv3:** Brought forth major advancements like Feature Pyramid Networks (FPN), multi-scale training, and the application of anchor boxes, improving the model's capability to detect objects of different sizes.
|
| 219 |
+
- **YOLOv4:** Marked a major architectural upgrade by adopting a CSPDarknet53-PANet-SPP backbone and integrating novel techniques like a *bag of specials*, a *bag of freebies*, genetic algorithms, and attention modules to improve both accuracy and speed.
|
| 220 |
+
- **YOLOv5:** While architecturally similar to YOLOv4, its implementation in PyTorch and the streamlined training process within the Ultralytics framework contributed to its widespread adoption.
|
| 221 |
+
- **YOLO-R, YOLO-X, YOLOv6, and YOLOv7:** These versions explored multitask learning (YOLO-R), anchor-free detection, decoupled heads, reparameterization, knowledge distillation, and quantization—allowing improved scaling and optimization of the models.
|
| 222 |
+
- **YOLOv8 and YOLO-NAS:** YOLOv8 builds upon YOLOv5 with minor changes, such as replacing the CSPLayer with the C2f module, and incorporates optimized loss functions for small object detection. YOLO-NAS stands out as a model generated through neural architecture search (NAS), employing quantization-aware blocks to achieve an optimal balance between speed and accuracy.
|
| 223 |
+
|
| 224 |
+
One of the challenges with the YOLO architecture is the large number of different versions, as the name can be used freely, and not all recent versions necessarily bring significant improvements. Indeed, when a new model is released under the YOLO name, it often shows superior metric results, but the differences tend to be minimal.
|
| 225 |
+
|
| 226 |
+

|
| 227 |
+
<div style="text-align: center; font-size: smaller;">
|
| 228 |
+
<strong>Figure 2: The Incremental Pursuit of SOTA in mAP. <br> Source: Take from video <a href="https://youtu.be/wuZtUMEiKWY?si=cXQAJJVOdvrtIF8z&t=50">YOLOv8: How to Train for Object Detection on a Custom Dataset - Roboflow</a></strong>
|
| 229 |
+
</div>
|
| 230 |
+
|
| 231 |
+
Moreover, a model achieving superior metrics on a general evaluation dataset, such as COCO, does not necessarily mean it will perform better in your specific use case. There are also differences in model size, inference and training time, library and hardware compatibility, and differences in the characteristics and quality of your data.
|
| 232 |
+
|
| 233 |
+

|
| 234 |
+
<div style="text-align: center; font-size: smaller;">
|
| 235 |
+
<strong>Figure 3: YOLO Performance Comparison.<br> Source: <a href="https://docs.ultralytics.com/pt/models/yolo11/">Ultralytics YOLO11</a></strong>
|
| 236 |
+
</div>
|
| 237 |
+
|
| 238 |
+
The family is distinguished by its unified and optimized design, making it deployable on low-resource devices and real-time applications. The diversity of YOLO versions presents challenges in choosing the ideal model for a specific use case.
|
| 239 |
+
|
| 240 |
+
#### **DETR**
|
| 241 |
+
|
| 242 |
+
The **DEtection TRansformer (DETR)** introduces an innovative approach by combining convolutional neural networks with transformer architecture, eliminating traditional and complex post-processing steps used in other methods, such as *Non-Maximum Suppression (NMS)*.
|
| 243 |
+
|
| 244 |
+

|
| 245 |
+
<div style="text-align: center; font-size: smaller;">
|
| 246 |
+
<strong>Figure 4: DETR architecture representation.<br> Source: <a href="https://arxiv.org/pdf/2005.12872">End-to-End Object Detection with Transformers</a></strong>
|
| 247 |
+
</div>
|
| 248 |
+
|
| 249 |
+
The DETR architecture can be divided into four main components:
|
| 250 |
+
|
| 251 |
+
1. **Backbone (e.g., ResNet):**
|
| 252 |
+
- **Function:** Extract a feature map rich in semantic and spatial information from the input image.
|
| 253 |
+
- **Output:** A set of two-dimensional vectors (feature map) that serves as input for the transformer module.
|
| 254 |
+
|
| 255 |
+
2. **Transformer Encoder-Decoder:**
|
| 256 |
+
- **Encoder:**
|
| 257 |
+
- **Function:** Process the feature map from the backbone by applying *multi-head self-attention* and feed-forward layers, capturing global and contextual relationships between different regions of the image.
|
| 258 |
+
- **Decoder:**
|
| 259 |
+
- **Function:** Use a fixed set of *object queries* (embeddings representing candidate objects) to iteratively refine bounding box and class label predictions.
|
| 260 |
+
- **Output:** A final set of predictions, where each *query* corresponds to a bounding box and its respective class.
|
| 261 |
+
|
| 262 |
+
3. **Feed-Forward Network (FFN):**
|
| 263 |
+
- **Function:** For each query processed by the decoder, the FFN generates the final predictions, including normalized box coordinates (x, y, width, and height) and classification scores (including a special class for "no object").
|
| 264 |
+
|
| 265 |
+
4. **Joint Reasoning:**
|
| 266 |
+
- **Feature:** DETR processes all objects simultaneously, leveraging *pairwise* relationships between predictions to handle ambiguities such as object overlap, eliminating the need for post-processing techniques like NMS.
|
| 267 |
+
|
| 268 |
+
The original DETR faced challenges such as slow convergence and suboptimal performance on small object detection. To address these limitations, improved variants have emerged:
|
| 269 |
+
|
| 270 |
+
- [**Deformable DETR:**](https://huggingface.co/docs/transformers/model_doc/deformable_detr)
|
| 271 |
+
- **Deformable Attention:** Focuses attention on a fixed number of sampling points near each reference, improving efficiency and enabling the detection of fine details in high-resolution images.
|
| 272 |
+
- **Multiscale Module:** Incorporates feature maps from different backbone layers, enhancing the model's ability to detect objects of varying sizes.
|
| 273 |
+
|
| 274 |
+

|
| 275 |
+
<div style="text-align: center; font-size: smaller;">
|
| 276 |
+
<strong>Figure 5: Deformable DETR mitigates the slow convergence issues and limited feature spatial resolution of the original DETR.<br> Source: <a href="https://arxiv.org/abs/2010.04159">Deformable DETR: Deformable Transformers for End-to-End Object Detection</a></strong></div>
|
| 277 |
+
|
| 278 |
+
|
| 279 |
+
- [**Conditional DETR:**](https://huggingface.co/docs/transformers/model_doc/conditional_detr)
|
| 280 |
+
- **Convergence Improvement:** Introduces conditional cross-attention in the decoder, making the *object queries* more specific to the input image and accelerating training (with reported convergence up to 6.7 times faster).
|
| 281 |
+
|
| 282 |
+

|
| 283 |
+
<div style="text-align: center; font-size: smaller;">
|
| 284 |
+
<strong>Figure 6: Conditional DETR shows faster convergence.<br> Source: <a href="https://arxiv.org/abs/2108.06152">Conditional DETR for Fast Training Convergence</a></strong></div>
|
| 285 |
+
|
| 286 |
+
Thus, DETR and its variants represent a paradigm shift in object detection, harnessing the power of transformers to capture global and contextual relationships in an end-to-end manner while simplifying the detection pipeline by removing manual post-processing steps.
|
| 287 |
+
|
| 288 |
+
#### **RT-DETR**
|
| 289 |
+
|
| 290 |
+
[**RT-DETR (Real-Time DEtection TRansformer)**](https://huggingface.co/docs/transformers/model_doc/rt_detr) is a transformer-based model designed for real-time object detection, extending the foundational DETR architecture with optimizations for speed and efficiency.
|
| 291 |
+
|
| 292 |
+

|
| 293 |
+
<div style="text-align: center; font-size: smaller;">
|
| 294 |
+
<strong>Figure 7: RT-DETR performance comparison.<br> Source: <a href="https://arxiv.org/abs/2304.08069">DETRs Beat YOLOs on Real-time Object Detection</a></strong></div>
|
| 295 |
+
|
| 296 |
+
1. **Hybrid Encoder**:
|
| 297 |
+
- RT-DETR employs a hybrid encoder that integrates **intra-scale interaction** and **cross-scale fusion**. This design enables the model to efficiently process features at different scales, capturing both local details and global relationships.
|
| 298 |
+
- This is particularly advantageous for detecting objects of varying sizes in complex scenes, a challenge for earlier transformer models.
|
| 299 |
+
|
| 300 |
+
2. **Elimination of NMS**:
|
| 301 |
+
- Like DETR, RT-DETR eliminates the need for **Non-Maximum Suppression (NMS)** by predicting all objects simultaneously. This end-to-end approach simplifies the detection pipeline and reduces post-processing overhead.
|
| 302 |
+
|
| 303 |
+
3. **Real-time Optimization**:
|
| 304 |
+
- RT-DETR achieves **medium latency (10–200 ms)**, making it suitable for real-time applications such as autonomous driving and video surveillance, while maintaining competitive accuracy.
|
| 305 |
+
|
| 306 |
+
RT-DETR approximates high-speed CNN-based models like YOLO and accuracy-focused transformer models.
|
| 307 |
+
|
| 308 |
+
#### **YOLOS**
|
| 309 |
+
|
| 310 |
+
[**YOLOS (You Only Look at One Sequence)**](https://huggingface.co/docs/transformers/model_doc/yolos) introduces a novel transformer-based approach to object detection, drawing inspiration from the **Vision Transformer (ViT)**. Unlike traditional CNN-based models, YOLOS reimagines object detection by treating images as sequences of patches, leveraging the transformer’s sequence-processing strengths.
|
| 311 |
+
|
| 312 |
+
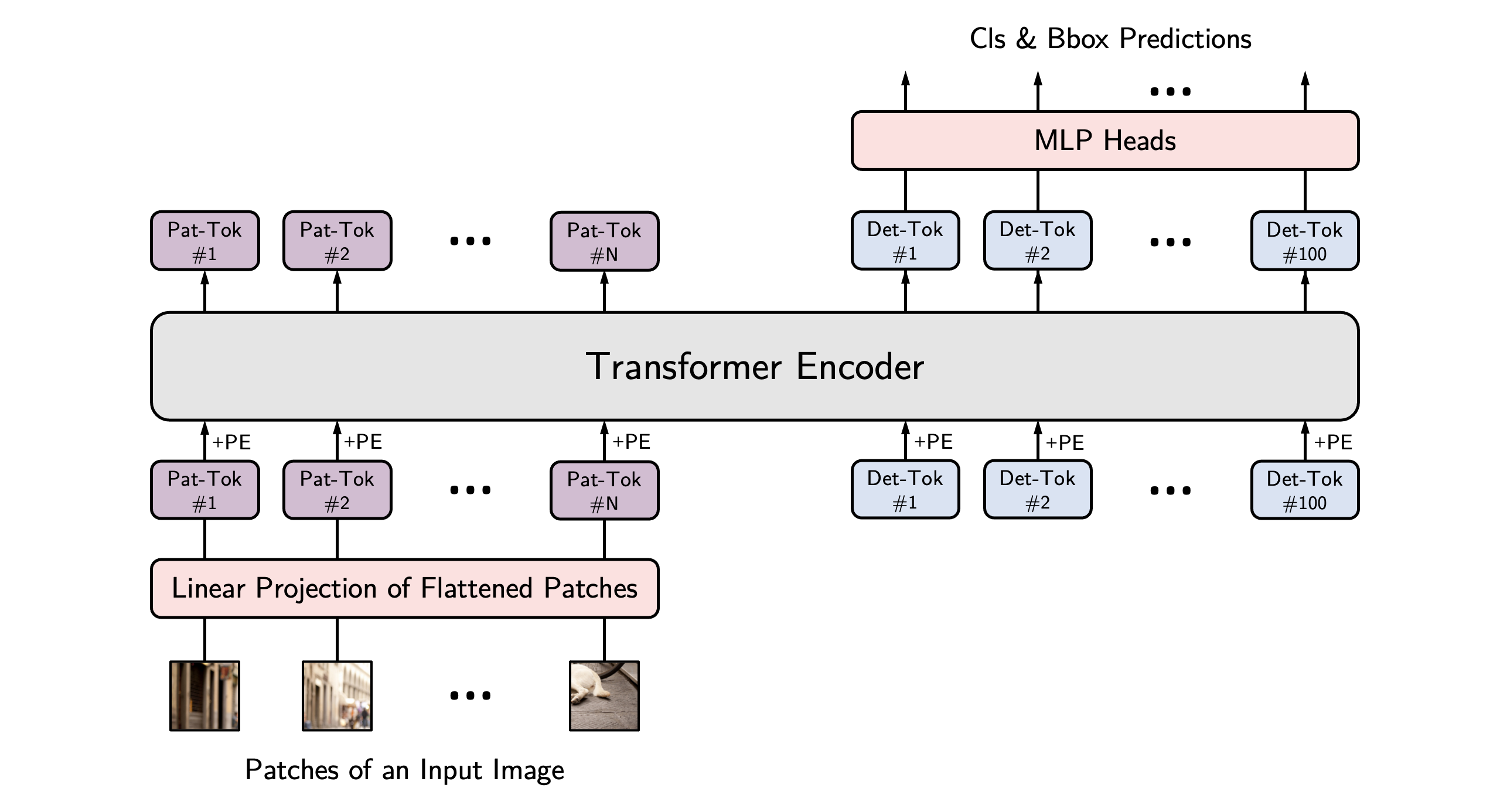
|
| 313 |
+
<div style="text-align: center; font-size: smaller;">
|
| 314 |
+
<strong>Figure 8: YOLOS Architecture representation.<br> Source: <a href="https://arxiv.org/abs/2106.00666">You Only Look at One Sequence: Rethinking Transformer in Vision through Object Detection</a></strong></div>
|
| 315 |
+
|
| 316 |
+
1. **Vision Transformer (ViT) Backbone**:
|
| 317 |
+
- YOLOS uses a ViT backbone, which splits the input image into fixed-size patches (e.g., 16x16 pixels). Each patch is treated as a token, allowing the transformer to process the image as a sequence and capture long-range dependencies.
|
| 318 |
+
|
| 319 |
+
2. **Patch-based Processing**:
|
| 320 |
+
- By converting the image into a sequence of patches, YOLOS efficiently handles high-resolution inputs and detects objects across different scales, making it adaptable to diverse detection tasks.
|
| 321 |
+
|
| 322 |
+
3. **Object Queries**:
|
| 323 |
+
- Similar to DETR, YOLOS employs **object queries** to predict bounding boxes and class labels directly. This eliminates the need for anchor boxes or NMS, aligning with the end-to-end philosophy of transformer-based detection.
|
| 324 |
+
|
| 325 |
+
4. **Efficiency Variants**:
|
| 326 |
+
- YOLOS offers variants such as **yolos-tiny**, **-small**, and **-base**, allowing to balance computational cost and performance based on application needs.
|
| 327 |
+
|
| 328 |
+

|
| 329 |
+
<div style="text-align: center; font-size: smaller;">
|
| 330 |
+
<strong>Figure 9: YOLOS Detection tokens inspect.<br> Source: <a href="https://arxiv.org/abs/2106.00666">You Only Look at One Sequence: Rethinking Transformer in Vision through Object Detection</a></strong></div>
|
| 331 |
+
|
| 332 |
+
I think this figure is very cool. It illustrates the specialization of [DET] tokens to focus on specific sizes of objects and distinct regions of the image. This adaptive behavior highlights the effectiveness in object detection tasks, allowing the model to dynamically allocate its detection capabilities based on the spatial and scale characteristics of the objects.
|
| 333 |
+
|
| 334 |
+
---
|
| 335 |
+
|
| 336 |
+
### 2.2. Dataset Composition and Preprocessing
|
| 337 |
+
|
| 338 |
+
The dataset was constructed by merging two publicly available benchmarks:
|
| 339 |
+
|
| 340 |
+
- [**Tobacco800**](https://paperswithcode.com/dataset/tobacco-800): A subset of the Complex Document Image Processing (CDIP) Test Collection, comprising scanned documents from the tobacco industry. Ground truth annotations include signatures and corporate logos.
|
| 341 |
+
- [**Signatures-XC8UP**](https://universe.roboflow.com/roboflow-100/signatures-xc8up): Part of the [Roboflow 100](https://rf100.org/) benchmark, containing 368 annotated images of handwritten signatures.
|
| 342 |
+
|
| 343 |
+
#### Roboflow
|
| 344 |
+
|
| 345 |
+
The [Roboflow](https://roboflow.com/) platform was employed for dataset management, preprocessing, and annotation. Key workflow components included:
|
| 346 |
+
|
| 347 |
+
- **Dataset Partitioning:**
|
| 348 |
+
- Training: 1,980 images (70%)
|
| 349 |
+
- Validation: 420 images (15%)
|
| 350 |
+
- Testing: 419 images (15%)
|
| 351 |
+
|
| 352 |
+
- **Preprocessing Pipeline:**
|
| 353 |
+
- Auto-orientation and bilinear resampling to 640×640 pixels
|
| 354 |
+
|
| 355 |
+
- **Spatial-Augmentation Strategy:**
|
| 356 |
+
- Rotation (90° fixed and ±10° random)
|
| 357 |
+
- Shear transformations (±4° horizontal, ±3° vertical)
|
| 358 |
+
- Photometric adjustments (±20% brightness/exposure variation)
|
| 359 |
+
- Stochastic blur (σ=1.5) and Gaussian noise (σ=0.05)
|
| 360 |
+
|
| 361 |
+
These techniques enhance model generalization across diverse document acquisition scenarios.
|
| 362 |
+
|
| 363 |
+
**Dataset Availability:**
|
| 364 |
+
- Roboflow Universe:
|
| 365 |
+
[](https://universe.roboflow.com/tech-ysdkk/signature-detection-hlx8j)
|
| 366 |
+
- Hugging Face Datasets Hub:
|
| 367 |
+
[](https://huggingface.co/datasets/tech4humans/signature-detection)
|
| 368 |
+
|
| 369 |
+

|
| 370 |
+
<div style="text-align: center; font-size: smaller;">
|
| 371 |
+
<strong>Figure 10: Annotated document samples demonstrating signature and logo detection tasks.</strong>
|
| 372 |
+
</div>
|
| 373 |
+
|
| 374 |
+
---
|
| 375 |
+
|
| 376 |
+
### 2.3. Training Process and Model Selection
|
| 377 |
+
|
| 378 |
+
Various models were evaluated using experiments conducted over 35 training epochs with consistent batch size and learning rate settings, based on the available computational capacity. The table below summarizes the results obtained for metrics such as CPU inference time, mAP@50, mAP@50-95, and total training time:
|
| 379 |
+
|
| 380 |
+
| Metric | [rtdetr-l](https://github.com/ultralytics/assets/releases/download/v8.2.0/rtdetr-l.pt) | [yolos-base](https://huggingface.co/hustvl/yolos-base) | [yolos-tiny](https://huggingface.co/hustvl/yolos-tiny) | [conditional-detr-resnet-50](https://huggingface.co/microsoft/conditional-detr-resnet-50) | [detr-resnet-50](https://huggingface.co/facebook/detr-resnet-50) | [yolov8x](https://github.com/ultralytics/assets/releases/download/v8.2.0/yolov8x.pt) | [yolov8l](https://github.com/ultralytics/assets/releases/download/v8.2.0/yolov8l.pt) | [yolov8m](https://github.com/ultralytics/assets/releases/download/v8.2.0/yolov8m.pt) | [yolov8s](https://github.com/ultralytics/assets/releases/download/v8.2.0/yolov8s.pt) | [yolov8n](https://github.com/ultralytics/assets/releases/download/v8.2.0/yolov8n.pt) | [yolo11x](https://github.com/ultralytics/assets/releases/download/v8.3.0/yolo11x.pt) | [yolo11l](https://github.com/ultralytics/assets/releases/download/v8.3.0/yolo11l.pt) | [yolo11m](https://github.com/ultralytics/assets/releases/download/v8.3.0/yolo11m.pt) | [yolo11s](https://github.com/ultralytics/assets/releases/download/v8.3.0/yolo11s.pt) | [yolo11n](https://github.com/ultralytics/assets/releases/download/v8.3.0/yolo11n.pt) | [yolov10x](https://github.com/ultralytics/assets/releases/download/v8.2.0/yolov10x.pt) | [yolov10l](https://github.com/ultralytics/assets/releases/download/v8.2.0/yolov10l.pt) | [yolov10b](https://github.com/ultralytics/assets/releases/download/v8.2.0/yolov10b.pt) | [yolov10m](https://github.com/ultralytics/assets/releases/download/v8.2.0/yolov10m.pt) | [yolov10s](https://github.com/ultralytics/assets/releases/download/v8.2.0/yolov10s.pt) | [yolov10n](https://github.com/ultralytics/assets/releases/download/v8.2.0/yolov10n.pt) | [yolo12n](https://github.com/ultralytics/assets/releases/download/v8.3.0/yolo12n.pt) | [yolo12s](https://github.com/ultralytics/assets/releases/download/v8.3.0/yolo12s.pt) | [yolo12m](https://github.com/ultralytics/assets/releases/download/v8.3.0/yolo12m.pt) | [yolo12l](https://github.com/ultralytics/assets/releases/download/v8.3.0/yolo12l.pt) | [yolo12x](https://github.com/ultralytics/assets/releases/download/v8.3.0/yolo12x.pt) |
|
| 381 |
+
| :---- | :---- | :---- | :---- | :---- | :---- | :---- | :---- | :---- | :---- | :---- | :---- | :---- | :---- | :---- | :---- | :---- | :---- | :---- | :---- | :---- | :---- | :---- | :---- | :---- | :---- | :---- |
|
| 382 |
+
| **Inference Time (CPU [ONNX] \- ms)** | 583.608 | 1706.49 | 265.346 | 476.831 | 425.649 | 1259.47 | 871.329 | 401.183 | 216.6 | 110.442 | 1016.68 | 518.147 | 381.652 | 179.792 | 106.656 | 821.183 | 580.767 | 473.109 | 320.12 | 150.076 | **73.8596** | 90.36 | 166.572 | 372.803 | 505.747 | 1022.84 |
|
| 383 |
+
| **mAP@50** | 0.92709 | 0.901154 | 0.869814 | **0.936524** | 0.88885 | 0.794237 | 0.800312 | 0.875322 | 0.874721 | 0.816089 | 0.667074 | 0.707409 | 0.809557 | 0.835605 | 0.813799 | 0.681023 | 0.726802 | 0.789835 | 0.787688 | 0.663877 | 0.734332 | 0.75856 | 0.66663 | 0.61959 | 0.54924 | 0.51162 |
|
| 384 |
+
| **mAP@50-95** | 0.622364 | 0.583569 | 0.469064 | 0.653321 | 0.579428 | 0.552919 | 0.593976 | **0.665495** | 0.65457 | 0.623963 | 0.482289 | 0.499126 | 0.600797 | 0.638849 | 0.617496 | 0.474535 | 0.522654 | 0.578874 | 0.581259 | 0.473857 | 0.55274 | 0.55868 | 0.48538 | 0.45616 | 0.41 | 0.35423 |
|
| 385 |
+
| **Training Time** | 55m 33s | 7h 53m | 1h 42m | 2h 45m | 2h 31m | 1h 30m | 1h | 44m 7s | 29m 1s | 22m 51s | 1h 28m | 55m 30s | 48m 2s | 30m 37s | 27m 33s | 1h 36m | 1h 8m | 1h 1m | 51m 38s | 34m 17s | 29m 2s | **20m 6s** | 36m 53s | 1h 8m | 1h 47m | 3h 1m |
|
| 386 |
+
<div style="text-align: center; font-size: smaller;">
|
| 387 |
+
<strong>Table 3. Training Results.</strong>
|
| 388 |
+
</div>
|
| 389 |
+
|
| 390 |
+
> <strong>Note:</strong> Best values in each category are highlighted. mAP (mean Average Precision) values range from 0-1, with higher values indicating better performance. Inference times measured on CPU using ONNX runtime in milliseconds (ms).
|
| 391 |
+
|
| 392 |
+
|
| 393 |
+

|
| 394 |
+
<div style="text-align: center; font-size: smaller;">
|
| 395 |
+
<strong>Figure 11: Comparison of Inference Time vs. mAP@50</strong>
|
| 396 |
+
</div>
|
| 397 |
+
|
| 398 |
+
**Highlights:**
|
| 399 |
+
|
| 400 |
+
- **Best mAP@50:** `conditional-detr-resnet-50` (93.65%)
|
| 401 |
+
- **Best mAP@50-95:** `yolov8m` (66.55%)
|
| 402 |
+
- **Lowest Inference Time:** `yolov10n` (73.86 ms)
|
| 403 |
+
|
| 404 |
+
The complete experiments are available on [***Weights & Biases***](https://api.wandb.ai/links/samuel-lima-tech4humans/30cmrkp8).
|
| 405 |
+
|
| 406 |
+
Our findings reveal a different behavior from general benchmarks, where larger model versions typically yield incremental improvements. In this experiment, smaller models such as YOLOv8n and YOLOv11s achieved satisfactory and comparable results to their larger counterparts.
|
| 407 |
+
|
| 408 |
+
Furthermore, purely convolutional architectures demonstrated faster inference and training times compared to transformer-based models while maintaining similar levels of accuracy.
|
| 409 |
+
|
| 410 |
+
---
|
| 411 |
+
|
| 412 |
+
### 2.4. Hyperparameter Optimization
|
| 413 |
+
|
| 414 |
+
Due to its strong initial performance and ease of export, the YOLOv8s model was selected for hyperparameter fine-tuning using [Optuna](https://optuna.org/). A total of 20 trials were conducted, with the test set F1-score serving as the objective function. The hyperparameter search space included:
|
| 415 |
+
|
| 416 |
+
```py
|
| 417 |
+
dropout = trial.suggest_float("dropout", 0.0, 0.5, step=0.1)
|
| 418 |
+
lr0 = trial.suggest_float("lr0", 1e-5, 1e-1, log=True)
|
| 419 |
+
box = trial.suggest_float("box", 3.0, 7.0, step=1.0)
|
| 420 |
+
cls = trial.suggest_float("cls", 0.5, 1.5, step=0.2)
|
| 421 |
+
opt = trial.suggest_categorical("optimizer", ["AdamW", "RMSProp"])
|
| 422 |
+
```
|
| 423 |
+
|
| 424 |
+
The results of this hypertuning experiment can be viewed here: [***Hypertuning Experiment***](https://api.wandb.ai/links/samuel-lima-tech4humans/31a6zhb1).
|
| 425 |
+
|
| 426 |
+
The figure below illustrates the correlation between the hyperparameters and the achieved F1-score:
|
| 427 |
+
|
| 428 |
+

|
| 429 |
+
<div style="text-align: center; font-size: smaller;">
|
| 430 |
+
<strong>Figure 12: Correlation between hyperparameters and the F1-score.</strong>
|
| 431 |
+
</div>
|
| 432 |
+
|
| 433 |
+
After tuning, the best trial (#10) exhibited the following improvements compared to the base model:
|
| 434 |
+
|
| 435 |
+
| Metric | Base Model | Best Trial (#10) | Difference |
|
| 436 |
+
|--------------|------------|------------------|------------|
|
| 437 |
+
| mAP@50 | 87.47% | **95.75%** | +8.28% |
|
| 438 |
+
| mAP@50-95 | 65.46% | **66.26%** | +0.81% |
|
| 439 |
+
| Precision | **97.23%** | 95.61% | -1.63% |
|
| 440 |
+
| Recall | 76.16% | **91.21%** | +15.05% |
|
| 441 |
+
| F1-score | 85.42% | **93.36%** | +7.94% |
|
| 442 |
+
<div style="text-align: left; font-size: smaller;">
|
| 443 |
+
<strong>Table 4: Comparison between the fine-tuned model and the pre-trained model.</strong>
|
| 444 |
+
</div>
|
| 445 |
+
|
| 446 |
+
---
|
| 447 |
+
|
| 448 |
+
## 3\. Evaluation and Results
|
| 449 |
+
|
| 450 |
+
The final evaluation of the model was conducted using ONNX format (for CPU inference) and TensorRT (for GPU – T4 inference). The key metrics obtained were:
|
| 451 |
+
|
| 452 |
+
- **Precision:** 94.74%
|
| 453 |
+
- **Recall:** 89.72%
|
| 454 |
+
- **mAP@50:** 94.50%
|
| 455 |
+
- **mAP@50-95:** 67.35%
|
| 456 |
+
|
| 457 |
+
Regarding inference times:
|
| 458 |
+
|
| 459 |
+
- **ONNX Runtime (CPU):** 171.56 ms
|
| 460 |
+
- **TensorRT (GPU – T4):** 7.657 ms
|
| 461 |
+
|
| 462 |
+
Figure 13 presents a graphical comparison of the evaluated metrics:
|
| 463 |
+
|
| 464 |
+

|
| 465 |
+
<div style="text-align: center; font-size: smaller;">
|
| 466 |
+
<strong>Figure 13. Model performance under different training hyperparameter configurations.</strong>
|
| 467 |
+
</div>
|
| 468 |
+
|
| 469 |
+
> The Base Model – Phase 1 (☆) represents the model obtained during the selection phase of training.
|
| 470 |
+
|
| 471 |
+
---
|
| 472 |
+
|
| 473 |
+
## 4\. Deployment and Publication
|
| 474 |
+
|
| 475 |
+
In this section, we describe the deployment process of the handwritten signature detection model using the [**Triton Inference Server**](https://github.com/triton-inference-server/server) and the publication of both the model and dataset on the [**Hugging Face Hub**](https://huggingface.co/). The objective was to create an efficient, cost-effective, and secure solution for making the model available in a production environment, while also providing public access to the work in accordance with open science principles.
|
| 476 |
+
|
| 477 |
+
### 4.1. Inference Server
|
| 478 |
+
|
| 479 |
+
The **Triton Inference Server** was chosen as the deployment platform due to its flexibility, efficiency, and support for multiple machine learning frameworks, including PyTorch, TensorFlow, ONNX, and TensorRT. It supports inference on both CPU and GPU and offers native tools for performance analysis and optimization, making it ideal for scaling model deployment.
|
| 480 |
+
|
| 481 |
+
The repository containing the server configurations and utility code is available at: [https://github.com/tech4ai/t4ai-signature-detect-server](https://github.com/tech4ai/t4ai-signature-detect-server)
|
| 482 |
+
|
| 483 |
+
#### Server Configuration
|
| 484 |
+
|
| 485 |
+
For the Triton implementation, we opted for an optimized approach using a custom **Docker** container. Instead of using the default image—which includes all backends and results in a size of 17.4 GB, we included only the necessary backends for this project: **Python**, **ONNX**, and **OpenVINO**. This optimization reduced the image size to 12.54 GB, thereby improving deployment efficiency. For scenarios that require GPU inference, the **TensorRT** backend would need to be included and the model would have to be in the .engine format; however, in this case, we prioritized CPU execution to reduce costs and simplify the infrastructure.
|
| 486 |
+
|
| 487 |
+
The server was configured using the following startup command, which has been adapted to ensure explicit control over models and enhanced security:
|
| 488 |
+
|
| 489 |
+
```bash
|
| 490 |
+
tritonserver \
|
| 491 |
+
--model-repository=${TRITON_MODEL_REPOSITORY} \
|
| 492 |
+
--model-control-mode=explicit \
|
| 493 |
+
--load-model=* \
|
| 494 |
+
--log-verbose=1 \
|
| 495 |
+
--allow-metrics=false \
|
| 496 |
+
--allow-grpc=true \
|
| 497 |
+
--grpc-restricted-protocol=model-repository,model-config,shared-memory,statistics,trace:admin-key=${TRITON_ADMIN_KEY} \
|
| 498 |
+
--http-restricted-api=model-repository,model-config,shared-memory,statistics,trace:admin-key=${TRITON_ADMIN_KEY}
|
| 499 |
+
```
|
| 500 |
+
|
| 501 |
+
The `explicit` mode allows models to be dynamically loaded and unloaded via HTTP/GRPC protocols, providing the flexibility to update models without restarting the server.
|
| 502 |
+
|
| 503 |
+
#### Access Restriction
|
| 504 |
+
|
| 505 |
+
Triton is configured to restrict access to sensitive administrative endpoints such as `model-repository`, `model-config`, `shared-memory`, `statistics`, and `trace`. These endpoints are accessible only to requests that include the correct `admin-key` header, thereby safeguarding administrative operations while leaving inference requests open to all users.
|
| 506 |
+
|
| 507 |
+
#### Ensemble Model
|
| 508 |
+
|
| 509 |
+
We developed an **Ensemble Model** within Triton to integrate the **YOLOv8** model (in ONNX format) with dedicated pre- and post-processing scripts, thereby creating a complete inference pipeline executed directly on the server. This approach minimizes latency by eliminating the need for multiple network calls and simplifies client-side integration. The Ensemble Model workflow comprises:
|
| 510 |
+
|
| 511 |
+
* **Preprocessing (Python backend):**
|
| 512 |
+
- Decoding the image from BGR to RGB.
|
| 513 |
+
- Resizing the image to 640×640 pixels.
|
| 514 |
+
- Normalizing pixel values (dividing by 255.0).
|
| 515 |
+
- Transposing the data to the [C, H, W] format.
|
| 516 |
+
|
| 517 |
+
* **Inference (ONNX model):**
|
| 518 |
+
- The YOLOv8 model performs signature detection.
|
| 519 |
+
|
| 520 |
+
* **Post-processing (Python backend):**
|
| 521 |
+
- Transposing the model outputs.
|
| 522 |
+
- Filtering bounding boxes based on a confidence threshold.
|
| 523 |
+
- Applying **Non-Maximum Suppression (NMS)** with an IoU threshold to eliminate redundant detections.
|
| 524 |
+
- Formatting the results in the [x, y, w, h, score] format.
|
| 525 |
+
|
| 526 |
+

|
| 527 |
+
<div style="text-align: center; font-size: smaller;">
|
| 528 |
+
<strong>Figure 14: Sequence Diagram — Ensemble Model</strong>
|
| 529 |
+
</div>
|
| 530 |
+
|
| 531 |
+
The pre- and post-processing scripts are treated as separate "models" by Triton and are executed on the Python backend, enabling flexibility for adjustments or replacements without modifying the core model. This Ensemble Model encapsulates the entire inference pipeline into a single entry point, thereby optimizing performance and usability.
|
| 532 |
+
|
| 533 |
+
#### Inference Pipeline
|
| 534 |
+
|
| 535 |
+
Within the project repository, we developed multiple inference scripts to interact with the Triton Inference Server using various methods:
|
| 536 |
+
|
| 537 |
+
- **Triton Client:** Inference via the Triton SDK.
|
| 538 |
+
- **Vertex AI:** Integration with a Google Cloud Vertex AI endpoint.
|
| 539 |
+
- **HTTP:** Direct requests to the Triton server via the HTTP protocol.
|
| 540 |
+
|
| 541 |
+
These scripts were designed to test the server and facilitate future integrations. In addition, the pipeline includes supplementary tools:
|
| 542 |
+
|
| 543 |
+
- **Graphical User Interface (GUI):** Developed with Gradio, this interface enables interactive model testing with real-time visualization of results. For example:
|
| 544 |
+
|
| 545 |
+
```py
|
| 546 |
+
python signature-detection/gui/inference_gui.py --triton-url {triton_url}
|
| 547 |
+
```
|
| 548 |
+
|
| 549 |
+
https://cdn-uploads.huggingface.co/production/uploads/666b9ef5e6c60b6fc4156675/rsR7UNEeucN-felJeizkb.mp4
|
| 550 |
+
|
| 551 |
+
- **Command-Line Interface (CLI):** This tool allows for batch inference on datasets, timing metrics calculation, and report generation. For example:
|
| 552 |
+
|
| 553 |
+
```py
|
| 554 |
+
python signature-detection/inference/inference_pipeline.py
|
| 555 |
+
```
|
| 556 |
+
|
| 557 |
+
The pipeline was designed to be modular and extensible, supporting experimentation and deployment in various environments—from local setups to cloud-based infrastructures.
|
| 558 |
+
|
| 559 |
+
---
|
| 560 |
+
|
| 561 |
+
### 4.2. Hugging Face Hub
|
| 562 |
+
|
| 563 |
+
The signature detection model has been published on the **Hugging Face Hub** to make it accessible to the community and to meet the licensing requirements of Ultralytics YOLO. The model repository includes:
|
| 564 |
+
|
| 565 |
+
- [**Model Card**](https://huggingface.co/tech4humans/yolov8s-signature-detector):
|
| 566 |
+
A comprehensive document detailing the training process, performance metrics (such as precision and recall), and usage guidelines. Model files are available in **PyTorch**, **ONNX**, and **TensorRT** formats, offering flexibility in selecting the inference backend.
|
| 567 |
+
|
| 568 |
+
- [**Demo Space**](https://huggingface.co/spaces/tech4humans/signature-detection):
|
| 569 |
+
An interactive interface developed with **Gradio**, where users can test the model by uploading images and viewing real-time detections.
|
| 570 |
+
|
| 571 |
+
- [**Dataset**](https://huggingface.co/datasets/tech4humans/signature-detection):
|
| 572 |
+
The dataset used for training and validation is also hosted on Hugging Face, alongside Roboflow, accompanied by comprehensive documentation and files in accessible formats.
|
| 573 |
+
|
| 574 |
+
---
|
| 575 |
+
|
| 576 |
+
## 5. Conclusion
|
| 577 |
+
|
| 578 |
+
This work demonstrated the feasibility of developing an efficient model for handwritten signature detection in documents by combining modern computer vision techniques with robust deployment tools. The comparative analysis of architectures revealed that YOLO-based models—particularly YOLOv8s—offer an ideal balance between speed and accuracy for the studied scenario, achieving **94.74% precision** and **89.72% recall** following hyperparameter optimization with Optuna. The integration of the Triton Inference Server enabled the creation of a scalable inference pipeline, while publication on the Hugging Face Hub ensured transparency and accessibility, in line with open science principles.
|
| 579 |
+
|
| 580 |
+
The proposed solution has immediate applications in fields such as legal, financial, and administrative sectors, where automating document verification can reduce operational costs and minimize human error. The model’s inference performance on both CPU (171.56 ms) and GPU (7.65 ms) makes it versatile for deployment across a range of infrastructures, from cloud servers to edge devices.
|
| 581 |
+
|
| 582 |
+
Limitations include the reliance on the quality of dataset annotations and the need for further validation on documents with complex layouts or partially obscured signatures. Future work may explore:
|
| 583 |
+
- Expanding the dataset to include images with greater cultural and typographic diversity.
|
| 584 |
+
- Adapting the model to detect other document elements (e.g., stamps, seals).
|
| 585 |
+
|
| 586 |
+
Ultimately, the open availability of the code, model, and dataset on the Hugging Face Hub and GitHub fosters community collaboration, accelerating the development of similar solutions. This project not only validates the efficacy of the tested approaches but also establishes a blueprint for the practical deployment of detection models in production, reinforcing the potential of AI to transform traditional workflows.
|
| 587 |
+
|
| 588 |
+
</div>
|
assets/sine.png
ADDED

|
Git LFS Details
|
assets/train_diagram.md
ADDED
|
@@ -0,0 +1,83 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
```mermaid
|
| 2 |
+
classDiagram
|
| 3 |
+
namespace Train {
|
| 4 |
+
class TrainerBuilder {
|
| 5 |
+
+batch: INDArray[2]
|
| 6 |
+
+trainInputs: INDArray
|
| 7 |
+
+trainTargets: INDArray
|
| 8 |
+
+testInputs: INDArray
|
| 9 |
+
+testTargets: INDArray
|
| 10 |
+
+epochs: int = 100
|
| 11 |
+
+batchSize: int = 32
|
| 12 |
+
+earlyStopping: boolean = false
|
| 13 |
+
+verbose: boolean = true
|
| 14 |
+
+patience: int = 20
|
| 15 |
+
+evalEvery: int = 10
|
| 16 |
+
+trainRatio: double = 0.8
|
| 17 |
+
|
| 18 |
+
+TrainerBuilder(model:NeuralNetwork, trainInputs:INDArray, trainTargets:INDArray, lossFunction:ILossFunction)
|
| 19 |
+
+TrainerBuilder(model:NeuralNetwork, trainInputs:INDArray, trainTargets:INDArray, testInputs:INDArray, testTargets:INDArray, lossFunction:ILossFunction)
|
| 20 |
+
+setOptimizer(optimizer:Optimizer): TrainerBuilder
|
| 21 |
+
+setEpochs(epochs:int): TrainerBuilder
|
| 22 |
+
+setBatchSize(batchSize:int): TrainerBuilder
|
| 23 |
+
+setEarlyStopping(earlyStopping:boolean): TrainerBuilder
|
| 24 |
+
+setPatience(patience:int): TrainerBuilder
|
| 25 |
+
+setTrainRatio(trainRatio:double): TrainerBuilder
|
| 26 |
+
+setEvalEvery(evalEvery:int): TrainerBuilder
|
| 27 |
+
+setVerbose(verbose:boolean): TrainerBuilder
|
| 28 |
+
+setMetric(metric:IMetric): TrainerBuilder
|
| 29 |
+
+build(): Trainer
|
| 30 |
+
}
|
| 31 |
+
|
| 32 |
+
class Trainer {
|
| 33 |
+
-model: NeuralNetwork
|
| 34 |
+
-optimizer: Optimizer
|
| 35 |
+
-lossFunction: ILossFunction
|
| 36 |
+
-metric: IMetric
|
| 37 |
+
-trainInputs: INDArray
|
| 38 |
+
-trainTargets: INDArray
|
| 39 |
+
-testInputs: INDArray
|
| 40 |
+
-testTargets: INDArray
|
| 41 |
+
-batch: INDArray[2]
|
| 42 |
+
-epochs: int
|
| 43 |
+
-batchSize: int
|
| 44 |
+
-currentIndex: int
|
| 45 |
+
-patience: int
|
| 46 |
+
-evalEvery: int
|
| 47 |
+
-earlyStopping: boolean
|
| 48 |
+
-verbose: boolean
|
| 49 |
+
-bestLoss: double
|
| 50 |
+
-wait: int
|
| 51 |
+
-threshold: double
|
| 52 |
+
-trainLoss: double
|
| 53 |
+
-valLoss: double
|
| 54 |
+
-trainMetricValue: double
|
| 55 |
+
-valMetricValue: double
|
| 56 |
+
|
| 57 |
+
+Trainer(TrainerBuilder)
|
| 58 |
+
+fit(): void
|
| 59 |
+
+evaluate(): void
|
| 60 |
+
-earlyStopping(): boolean
|
| 61 |
+
-hasNextBatch(): boolean
|
| 62 |
+
-getNextBatch(): void
|
| 63 |
+
+splitData(inputs:INDArray, targets:INDArray, trainRatio:double): void
|
| 64 |
+
+printDataInfo(): void
|
| 65 |
+
+getTrainInputs(): INDArray
|
| 66 |
+
+getTrainTargets(): INDArray
|
| 67 |
+
+getTestInputs(): INDArray
|
| 68 |
+
+getTestTargets(): INDArray
|
| 69 |
+
}
|
| 70 |
+
}
|
| 71 |
+
|
| 72 |
+
%% Relationships for Train namespace
|
| 73 |
+
TrainerBuilder --> Trainer: builds >
|
| 74 |
+
TrainerBuilder o--> NeuralNetwork: model
|
| 75 |
+
TrainerBuilder o--> ILossFunction: lossFunction
|
| 76 |
+
TrainerBuilder o--> IMetric: metric
|
| 77 |
+
TrainerBuilder o--> Optimizer: optimizer
|
| 78 |
+
|
| 79 |
+
Trainer *--> NeuralNetwork: model
|
| 80 |
+
Trainer *--> Optimizer: optimizer
|
| 81 |
+
Trainer *--> ILossFunction: lossFunction
|
| 82 |
+
Trainer *--> IMetric: metric
|
| 83 |
+
```
|
pages/1_black_bee_drones.py
ADDED
|
@@ -0,0 +1,337 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import streamlit as st
|
| 2 |
+
import plotly.graph_objects as go
|
| 3 |
+
from streamlit_extras.badges import badge
|
| 4 |
+
import sys
|
| 5 |
+
import os
|
| 6 |
+
|
| 7 |
+
# Add the root directory to the path
|
| 8 |
+
sys.path.append(os.path.dirname(os.path.dirname(os.path.abspath(__file__))))
|
| 9 |
+
|
| 10 |
+
# Import helper functions
|
| 11 |
+
from utils.helpers import display_asset_or_placeholder, display_iframe_or_link
|
| 12 |
+
|
| 13 |
+
# Set page configuration
|
| 14 |
+
st.set_page_config(
|
| 15 |
+
page_title="Black Bee Drones | CV Journey",
|
| 16 |
+
page_icon="assets/black_bee.png",
|
| 17 |
+
layout="wide",
|
| 18 |
+
initial_sidebar_state="expanded",
|
| 19 |
+
)
|
| 20 |
+
|
| 21 |
+
# Title and introduction
|
| 22 |
+
st.header("🐝 Black Bee Drones - Autonomous Missions")
|
| 23 |
+
|
| 24 |
+
st.markdown(
|
| 25 |
+
"""
|
| 26 |
+
### First Autonomous Drone Team in Latin America
|
| 27 |
+
|
| 28 |
+
I joined the Black Bee Drones team in 2023 as a software member and continue to this day. The team, based at UNIFEI,
|
| 29 |
+
focuses on indoor and outdoor autonomous mission competitions, and we build our own drones from the ground up.
|
| 30 |
+
|
| 31 |
+
**Key Focus Areas:**
|
| 32 |
+
- Autonomous indoor/outdoor missions
|
| 33 |
+
- Custom drone building and integration
|
| 34 |
+
- Software development for autonomous flight
|
| 35 |
+
- Computer vision algorithms for navigation and object detection
|
| 36 |
+
|
| 37 |
+
**Main Competition:** International Micro Air Vehicles (IMAV) Conference and Competition
|
| 38 |
+
|
| 39 |
+
**Notable Achievement:** 3rd place in IMAV 2023 Indoor competition with a special award for being
|
| 40 |
+
the only team to perform the flight completely autonomously.
|
| 41 |
+
"""
|
| 42 |
+
)
|
| 43 |
+
|
| 44 |
+
# Create columns for team structure
|
| 45 |
+
st.subheader("Team Structure")
|
| 46 |
+
col1, col2, col3, col4 = st.columns(4)
|
| 47 |
+
|
| 48 |
+
with col1:
|
| 49 |
+
st.markdown("#### Hardware Team")
|
| 50 |
+
st.markdown(
|
| 51 |
+
"""
|
| 52 |
+
- Controller boards (PixHawk)
|
| 53 |
+
- Onboard computers (Raspberry Pi 4)
|
| 54 |
+
- Cameras (RaspCam, Oak-D)
|
| 55 |
+
- Positioning systems (GPS, LiDAR)
|
| 56 |
+
"""
|
| 57 |
+
)
|
| 58 |
+
|
| 59 |
+
with col2:
|
| 60 |
+
st.markdown("#### Software Team")
|
| 61 |
+
st.markdown(
|
| 62 |
+
"""
|
| 63 |
+
- Computer Vision algorithms
|
| 64 |
+
- Mapping & localization
|
| 65 |
+
- Position estimation
|
| 66 |
+
- Autonomous control
|
| 67 |
+
"""
|
| 68 |
+
)
|
| 69 |
+
|
| 70 |
+
with col3:
|
| 71 |
+
st.markdown("#### Mechanics Team")
|
| 72 |
+
st.markdown(
|
| 73 |
+
"""
|
| 74 |
+
- Frame design
|
| 75 |
+
- 3D printing
|
| 76 |
+
- Propulsion systems
|
| 77 |
+
- Component arrangement
|
| 78 |
+
"""
|
| 79 |
+
)
|
| 80 |
+
|
| 81 |
+
with col4:
|
| 82 |
+
st.markdown("#### Management Team")
|
| 83 |
+
st.markdown(
|
| 84 |
+
"""
|
| 85 |
+
- Competition strategy
|
| 86 |
+
- Documentation
|
| 87 |
+
- Team organization
|
| 88 |
+
- Resource allocation
|
| 89 |
+
"""
|
| 90 |
+
)
|
| 91 |
+
|
| 92 |
+
st.markdown("---")
|
| 93 |
+
|
| 94 |
+
# Technologies section
|
| 95 |
+
st.subheader("Core Technologies & Concepts")
|
| 96 |
+
|
| 97 |
+
tech_tab1, tech_tab2, tech_tab3 = st.tabs(
|
| 98 |
+
["Software Stack", "CV Techniques", "Hardware Components"]
|
| 99 |
+
)
|
| 100 |
+
|
| 101 |
+
with tech_tab1:
|
| 102 |
+
col1, col2 = st.columns(2)
|
| 103 |
+
|
| 104 |
+
with col1:
|
| 105 |
+
st.markdown(
|
| 106 |
+
"""
|
| 107 |
+
#### Main Software Tools
|
| 108 |
+
- **OpenCV:** Image processing and computer vision
|
| 109 |
+
- **ROS (Robot Operating System):** Distributed computing for robotics
|
| 110 |
+
- **TensorFlow/PyTorch:** Deep learning frameworks
|
| 111 |
+
- **Docker:** Containerization for deployment
|
| 112 |
+
- **MAVLink/MAVROS:** Drone communication protocols
|
| 113 |
+
"""
|
| 114 |
+
)
|
| 115 |
+
|
| 116 |
+
with col2:
|
| 117 |
+
st.markdown(
|
| 118 |
+
"""
|
| 119 |
+
#### Programming Languages
|
| 120 |
+
- **Python:** Main language for CV and high-level control
|
| 121 |
+
- **C++:** Performance-critical components and ROS nodes
|
| 122 |
+
"""
|
| 123 |
+
)
|
| 124 |
+
|
| 125 |
+
with tech_tab2:
|
| 126 |
+
st.markdown(
|
| 127 |
+
"""
|
| 128 |
+
#### Computer Vision & AI Techniques
|
| 129 |
+
- **Basic Image Processing:** Filters, morphological operations, thresholding
|
| 130 |
+
- **Feature Detection:** Corners, edges, and contours
|
| 131 |
+
- **Marker Detection:** ArUco markers for localization
|
| 132 |
+
- **Object Detection:** Custom models for mission-specific objects
|
| 133 |
+
- **Line Following:** Color segmentation and path estimation
|
| 134 |
+
- **Hand/Face Detection:** Using MediaPipe for gesture control
|
| 135 |
+
- **Visual Odometry:** For position estimation in GPS-denied environments
|
| 136 |
+
"""
|
| 137 |
+
)
|
| 138 |
+
|
| 139 |
+
with tech_tab3:
|
| 140 |
+
col1, col2 = st.columns(2)
|
| 141 |
+
|
| 142 |
+
with col1:
|
| 143 |
+
st.markdown(
|
| 144 |
+
"""
|
| 145 |
+
#### Control & Computing
|
| 146 |
+
- **PixHawk:** Flight controller board
|
| 147 |
+
- **Raspberry Pi 4:** Onboard computer
|
| 148 |
+
- **ESCs & Motors:** Propulsion system
|
| 149 |
+
- **Battery:** Power source
|
| 150 |
+
"""
|
| 151 |
+
)
|
| 152 |
+
|
| 153 |
+
with col2:
|
| 154 |
+
st.markdown(
|
| 155 |
+
"""
|
| 156 |
+
#### Sensors & Perception
|
| 157 |
+
- **RaspCam/Oak-D:** Cameras for visual perception
|
| 158 |
+
- **GPS:** Outdoor positioning (when available)
|
| 159 |
+
- **LiDAR:** Distance sensing and mapping
|
| 160 |
+
- **RealSense T265:** Visual-inertial odometry
|
| 161 |
+
- **PX4 Flow:** Optical flow sensor for position holding
|
| 162 |
+
"""
|
| 163 |
+
)
|
| 164 |
+
|
| 165 |
+
st.markdown("---")
|
| 166 |
+
|
| 167 |
+
# OpenCV Demo section
|
| 168 |
+
st.subheader("Demo: Real-time OpenCV Operations")
|
| 169 |
+
|
| 170 |
+
st.markdown(
|
| 171 |
+
"""
|
| 172 |
+
Basic image processing is fundamental to drone perception. This demo showcases real-time:
|
| 173 |
+
- Various image filters and transformations
|
| 174 |
+
- ArUco marker detection (used for drone localization)
|
| 175 |
+
- Hand and face detection using MediaPipe
|
| 176 |
+
"""
|
| 177 |
+
)
|
| 178 |
+
|
| 179 |
+
display_iframe_or_link("https://samuellimabraz-opencv-gui.hf.space", height=800)
|
| 180 |
+
|
| 181 |
+
st.caption(
|
| 182 |
+
"Link to Hugging Face Space: [OpenCV GUI Demo](https://samuellimabraz-opencv-gui.hf.space)"
|
| 183 |
+
)
|
| 184 |
+
|
| 185 |
+
st.markdown("---")
|
| 186 |
+
|
| 187 |
+
# Line Following Challenge
|
| 188 |
+
st.subheader("IMAV 2023 Indoor Mission: Line Following Challenge")
|
| 189 |
+
|
| 190 |
+
col1, col2 = st.columns(2)
|
| 191 |
+
|
| 192 |
+
with col1:
|
| 193 |
+
st.markdown(
|
| 194 |
+
"""
|
| 195 |
+
### The Challenge
|
| 196 |
+
|
| 197 |
+
The [IMAV 2023 Indoor](https://2023.imavs.org/index.php/indoor-competition/) Mission required drones to:
|
| 198 |
+
|
| 199 |
+
1. Navigate using ArUco markers for initial positioning
|
| 200 |
+
2. Follow a colored line on the floor to reach a deposit location
|
| 201 |
+
3. Deliver a block autonomously
|
| 202 |
+
|
| 203 |
+
This mission tested precise control, vision-based navigation, and autonomous decision-making.
|
| 204 |
+
"""
|
| 205 |
+
)
|
| 206 |
+
|
| 207 |
+
display_asset_or_placeholder(
|
| 208 |
+
"imav_mission_diagram.jpg",
|
| 209 |
+
caption="Diagram of the IMAV 2023 Indoor Mission",
|
| 210 |
+
use_column_width=True,
|
| 211 |
+
)
|
| 212 |
+
|
| 213 |
+
with col2:
|
| 214 |
+
st.markdown(
|
| 215 |
+
"""
|
| 216 |
+
### Line Following Algorithm
|
| 217 |
+
|
| 218 |
+
I developed a robust line-following algorithm consisting of:
|
| 219 |
+
|
| 220 |
+
1. **Color Filtering:** Isolate the colored line using HSV thresholding in OpenCV
|
| 221 |
+
2. **Line Detection & Orientation:** Estimate the line's position and direction
|
| 222 |
+
3. **PID Controller:** Adjust the drone's heading based on the line's position relative to the center
|
| 223 |
+
|
| 224 |
+
The algorithm was robust to varying lighting conditions and line widths, which was crucial for the competition environment.
|
| 225 |
+
"""
|
| 226 |
+
)
|
| 227 |
+
|
| 228 |
+
# Create a simple PID visualization
|
| 229 |
+
st.markdown("#### PID Control Visualization")
|
| 230 |
+
|
| 231 |
+
fig = go.Figure()
|
| 232 |
+
|
| 233 |
+
# Create data for the PID controller visualization
|
| 234 |
+
import numpy as np
|
| 235 |
+
|
| 236 |
+
# Time points
|
| 237 |
+
t = np.linspace(0, 10, 100)
|
| 238 |
+
|
| 239 |
+
# Target (setpoint)
|
| 240 |
+
setpoint = np.ones_like(t) * 0
|
| 241 |
+
|
| 242 |
+
# PID response for roll (center line error)
|
| 243 |
+
center_error = np.sin(t) * np.exp(-0.3 * t)
|
| 244 |
+
roll_output = -center_error * 0.8
|
| 245 |
+
|
| 246 |
+
# PID response for yaw (angle error)
|
| 247 |
+
angle_error = np.cos(t) * np.exp(-0.4 * t)
|
| 248 |
+
yaw_output = -angle_error * 0.7
|
| 249 |
+
|
| 250 |
+
# Add traces
|
| 251 |
+
fig.add_trace(
|
| 252 |
+
go.Scatter(
|
| 253 |
+
x=t,
|
| 254 |
+
y=setpoint,
|
| 255 |
+
mode="lines",
|
| 256 |
+
name="Setpoint",
|
| 257 |
+
line=dict(color="green", width=2, dash="dash"),
|
| 258 |
+
)
|
| 259 |
+
)
|
| 260 |
+
fig.add_trace(
|
| 261 |
+
go.Scatter(
|
| 262 |
+
x=t,
|
| 263 |
+
y=center_error,
|
| 264 |
+
mode="lines",
|
| 265 |
+
name="Center Line Error",
|
| 266 |
+
line=dict(color="red", width=2),
|
| 267 |
+
)
|
| 268 |
+
)
|
| 269 |
+
fig.add_trace(
|
| 270 |
+
go.Scatter(
|
| 271 |
+
x=t,
|
| 272 |
+
y=angle_error,
|
| 273 |
+
mode="lines",
|
| 274 |
+
name="Angle Error",
|
| 275 |
+
line=dict(color="orange", width=2),
|
| 276 |
+
)
|
| 277 |
+
)
|
| 278 |
+
fig.add_trace(
|
| 279 |
+
go.Scatter(
|
| 280 |
+
x=t,
|
| 281 |
+
y=roll_output,
|
| 282 |
+
mode="lines",
|
| 283 |
+
name="Roll Correction",
|
| 284 |
+
line=dict(color="blue", width=2),
|
| 285 |
+
)
|
| 286 |
+
)
|
| 287 |
+
fig.add_trace(
|
| 288 |
+
go.Scatter(
|
| 289 |
+
x=t,
|
| 290 |
+
y=yaw_output,
|
| 291 |
+
mode="lines",
|
| 292 |
+
name="Yaw Correction",
|
| 293 |
+
line=dict(color="purple", width=2),
|
| 294 |
+
)
|
| 295 |
+
)
|
| 296 |
+
|
| 297 |
+
# Update layout
|
| 298 |
+
fig.update_layout(
|
| 299 |
+
title="PID Controllers for Line Following",
|
| 300 |
+
xaxis_title="Time",
|
| 301 |
+
yaxis_title="Error / Correction",
|
| 302 |
+
legend=dict(y=0.99, x=0.01, orientation="h"),
|
| 303 |
+
margin=dict(l=0, r=0, t=40, b=0),
|
| 304 |
+
height=300,
|
| 305 |
+
)
|
| 306 |
+
|
| 307 |
+
st.plotly_chart(fig, use_container_width=True)
|
| 308 |
+
|
| 309 |
+
# Demo iFrame
|
| 310 |
+
st.markdown("### Line Following Simulation Demo")
|
| 311 |
+
display_iframe_or_link("https://samuellimabraz-line-follow-pid.hf.space", height=1200)
|
| 312 |
+
st.caption(
|
| 313 |
+
"Link to Hugging Face Space: [Line Follow PID Demo](https://samuellimabraz-line-follow-pid.hf.space)"
|
| 314 |
+
)
|
| 315 |
+
|
| 316 |
+
# Video demo
|
| 317 |
+
st.markdown("### Real Flight Footage (IMAV 2023)")
|
| 318 |
+
display_asset_or_placeholder(
|
| 319 |
+
"drone_line_following_video.mp4",
|
| 320 |
+
asset_type="video",
|
| 321 |
+
caption="Black Bee Drone executing the line following task during IMAV 2023",
|
| 322 |
+
)
|
| 323 |
+
|
| 324 |
+
|
| 325 |
+
st.markdown("---")
|
| 326 |
+
st.markdown(
|
| 327 |
+
"""
|
| 328 |
+
### Team Recognition
|
| 329 |
+
|
| 330 |
+
This work was made possible by the incredible Black Bee Drones team at UNIFEI. Special thanks to all members
|
| 331 |
+
who contributed their expertise in hardware, software, mechanics, and management.
|
| 332 |
+
"""
|
| 333 |
+
)
|
| 334 |
+
|
| 335 |
+
st.markdown(
|
| 336 |
+
"[Black Bee Drones](https://www.linkedin.com/company/blackbeedrones/posts/?feedView=all)"
|
| 337 |
+
)
|
pages/2_asimo_foundation.py
ADDED
|
@@ -0,0 +1,286 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import streamlit as st
|
| 2 |
+
import plotly.graph_objects as go
|
| 3 |
+
from streamlit_extras.badges import badge
|
| 4 |
+
|
| 5 |
+
# Set page configuration
|
| 6 |
+
st.set_page_config(
|
| 7 |
+
page_title="Asimo Foundation | CV Journey",
|
| 8 |
+
page_icon="🤖",
|
| 9 |
+
layout="wide",
|
| 10 |
+
initial_sidebar_state="expanded",
|
| 11 |
+
)
|
| 12 |
+
|
| 13 |
+
# Title and introduction
|
| 14 |
+
st.header("🤖 Asimo Foundation - STEM Education")
|
| 15 |
+
|
| 16 |
+
st.markdown(
|
| 17 |
+
"""
|
| 18 |
+
### Bringing Technology Education to Public Schools
|
| 19 |
+
|
| 20 |
+
The Asimo Foundation is a social project at UNIFEI that aims to reduce educational inequality
|
| 21 |
+
by bringing STEAM (Science, Technology, Engineering, Arts, and Mathematics) education to public schools in the region.
|
| 22 |
+
|
| 23 |
+
This initiative:
|
| 24 |
+
- Introduces students to robotics, programming, and technology
|
| 25 |
+
- Provides hands-on experience with Arduino, Lego Mindstorms, and ESP32
|
| 26 |
+
- Develops problem-solving and critical thinking skills
|
| 27 |
+
- Inspires interest in technology and engineering careers
|
| 28 |
+
"""
|
| 29 |
+
)
|
| 30 |
+
|
| 31 |
+
# Project details in tabs
|
| 32 |
+
project_tabs = st.tabs(["Mission & Impact", "Technologies", "Teaching Methodology"])
|
| 33 |
+
|
| 34 |
+
with project_tabs[0]:
|
| 35 |
+
col1, col2 = st.columns([3, 2])
|
| 36 |
+
|
| 37 |
+
with col1:
|
| 38 |
+
st.markdown(
|
| 39 |
+
"""
|
| 40 |
+
### Our Mission
|
| 41 |
+
|
| 42 |
+
The Asimo Foundation believes that all students, regardless of socioeconomic background,
|
| 43 |
+
deserve access to high-quality STEM education. By bringing technology education to public
|
| 44 |
+
schools, we aim to:
|
| 45 |
+
|
| 46 |
+
- **Bridge the digital divide** between private and public education
|
| 47 |
+
- **Empower students** with technical skills for the future job market
|
| 48 |
+
- **Inspire curiosity and innovation** in young minds
|
| 49 |
+
- **Provide university students** with teaching experience and community engagement
|
| 50 |
+
"""
|
| 51 |
+
)
|
| 52 |
+
|
| 53 |
+
|
| 54 |
+
with project_tabs[1]:
|
| 55 |
+
col1, col2, col3 = st.columns(3)
|
| 56 |
+
|
| 57 |
+
with col1:
|
| 58 |
+
st.markdown(
|
| 59 |
+
"""
|
| 60 |
+
### Arduino
|
| 61 |
+
|
| 62 |
+
**Applications:**
|
| 63 |
+
- Basic circuits and electronics
|
| 64 |
+
- Sensor integration (temperature, light, distance)
|
| 65 |
+
- Simple robotics projects (line followers, obstacle avoidance)
|
| 66 |
+
- LED control and displays
|
| 67 |
+
|
| 68 |
+
**Benefits:**
|
| 69 |
+
- Low cost and widely available
|
| 70 |
+
- Excellent introduction to programming and electronics
|
| 71 |
+
- Versatile platform with thousands of project examples
|
| 72 |
+
"""
|
| 73 |
+
)
|
| 74 |
+
|
| 75 |
+
with col2:
|
| 76 |
+
st.markdown(
|
| 77 |
+
"""
|
| 78 |
+
### Lego Mindstorms
|
| 79 |
+
|
| 80 |
+
**Applications:**
|
| 81 |
+
- Robot construction and design
|
| 82 |
+
- Visual programming introduction
|
| 83 |
+
- Sensor integration and robotics concepts
|
| 84 |
+
- Competitive challenges and problem-solving
|
| 85 |
+
|
| 86 |
+
**Benefits:**
|
| 87 |
+
- Intuitive building system
|
| 88 |
+
- Robust components for classroom use
|
| 89 |
+
- Engaging form factor that appeals to students
|
| 90 |
+
- Scaffolded learning progression
|
| 91 |
+
"""
|
| 92 |
+
)
|
| 93 |
+
|
| 94 |
+
with col3:
|
| 95 |
+
st.markdown(
|
| 96 |
+
"""
|
| 97 |
+
### ESP32
|
| 98 |
+
|
| 99 |
+
**Applications:**
|
| 100 |
+
- IoT (Internet of Things) projects
|
| 101 |
+
- Wireless communication
|
| 102 |
+
- Advanced sensing and control
|
| 103 |
+
- Web-based interfaces
|
| 104 |
+
|
| 105 |
+
**Benefits:**
|
| 106 |
+
- Built-in Wi-Fi and Bluetooth
|
| 107 |
+
- Powerful processing capabilities
|
| 108 |
+
- Low power consumption
|
| 109 |
+
- Bridge to more advanced applications
|
| 110 |
+
"""
|
| 111 |
+
)
|
| 112 |
+
|
| 113 |
+
with project_tabs[2]:
|
| 114 |
+
st.markdown(
|
| 115 |
+
"""
|
| 116 |
+
### Our Teaching Approach
|
| 117 |
+
|
| 118 |
+
We follow a project-based learning methodology that emphasizes:
|
| 119 |
+
|
| 120 |
+
1. **Hands-on Exploration:** Students learn by doing, building, and experimenting
|
| 121 |
+
2. **Collaborative Problem-Solving:** Group projects that encourage teamwork
|
| 122 |
+
3. **Incremental Challenges:** Starting with simple concepts and building to complex projects
|
| 123 |
+
4. **Real-World Applications:** Connecting technology concepts to everyday life
|
| 124 |
+
5. **Student-Led Innovation:** Encouraging creativity and independent thinking
|
| 125 |
+
|
| 126 |
+
This approach ensures that students not only learn technical skills but also develop critical thinking,
|
| 127 |
+
collaboration, and self-confidence.
|
| 128 |
+
"""
|
| 129 |
+
)
|
| 130 |
+
|
| 131 |
+
st.markdown("---")
|
| 132 |
+
|
| 133 |
+
# Gesture-controlled robotic arm project
|
| 134 |
+
st.subheader("Featured Project: Gesture-Controlled Robotic Arm")
|
| 135 |
+
|
| 136 |
+
col1, col2 = st.columns(2)
|
| 137 |
+
|
| 138 |
+
with col1:
|
| 139 |
+
st.markdown(
|
| 140 |
+
"""
|
| 141 |
+
### Computer Vision Meets Robotics
|
| 142 |
+
|
| 143 |
+
This project combines computer vision with robotic control to create an intuitive
|
| 144 |
+
interface for controlling a robotic arm using hand gestures.
|
| 145 |
+
|
| 146 |
+
**How it works:**
|
| 147 |
+
1. A webcam captures the user's hand movements
|
| 148 |
+
2. MediaPipe hand tracking detects hand landmarks in real-time
|
| 149 |
+
3. Custom algorithms convert hand position to servo angles
|
| 150 |
+
4. Arduino/ESP32 receives commands and controls the servo motors
|
| 151 |
+
5. The robotic arm mimics the user's hand movements
|
| 152 |
+
|
| 153 |
+
This project demonstrates how computer vision can create natural human-machine interfaces
|
| 154 |
+
and serves as an engaging introduction to both robotics and CV concepts.
|
| 155 |
+
"""
|
| 156 |
+
)
|
| 157 |
+
|
| 158 |
+
with col2:
|
| 159 |
+
# Placeholder for robotic arm image
|
| 160 |
+
st.image(
|
| 161 |
+
"assets/robotic_arm.jpg",
|
| 162 |
+
caption="Robotic Arm used in the Asimo Foundation project",
|
| 163 |
+
use_container_width=True,
|
| 164 |
+
)
|
| 165 |
+
|
| 166 |
+
# Technical implementation details
|
| 167 |
+
st.subheader("Technical Implementation")
|
| 168 |
+
|
| 169 |
+
implementation_tabs = st.tabs(["Hand Tracking", "Angle Calculation", "Arduino Control"])
|
| 170 |
+
|
| 171 |
+
with implementation_tabs[0]:
|
| 172 |
+
st.markdown(
|
| 173 |
+
"""
|
| 174 |
+
### MediaPipe Hand Tracking
|
| 175 |
+
|
| 176 |
+
We use Google's MediaPipe framework to detect and track hand landmarks in real-time.
|
| 177 |
+
|
| 178 |
+
**Key Technologies:**
|
| 179 |
+
- [MediaPipe](https://developers.google.com/mediapipe) - Google's open-source framework for building multimodal ML pipelines
|
| 180 |
+
- [MediaPipe Hands](https://developers.google.com/mediapipe/solutions/vision/hand_landmarker) - Specific solution for hand tracking
|
| 181 |
+
- [OpenCV](https://opencv.org/) - Open source computer vision library
|
| 182 |
+
|
| 183 |
+
**What it does:**
|
| 184 |
+
- Detects up to 21 landmarks on each hand
|
| 185 |
+
- Works in real-time on CPU
|
| 186 |
+
- Provides robust tracking even with partial occlusion
|
| 187 |
+
- Returns normalized 3D coordinates for each landmark
|
| 188 |
+
|
| 189 |
+
**Resources:**
|
| 190 |
+
- [MediaPipe GitHub](https://github.com/google/mediapipe)
|
| 191 |
+
- [Hand Tracking Tutorial](https://developers.google.com/mediapipe/solutions/vision/hand_landmarker/python)
|
| 192 |
+
- [OpenCV Documentation](https://docs.opencv.org/)
|
| 193 |
+
"""
|
| 194 |
+
)
|
| 195 |
+
|
| 196 |
+
with implementation_tabs[1]:
|
| 197 |
+
st.markdown(
|
| 198 |
+
"""
|
| 199 |
+
### Mapping Hand Position to Servo Angles
|
| 200 |
+
|
| 201 |
+
Converting hand landmark positions to meaningful servo angles requires mathematical transformations.
|
| 202 |
+
|
| 203 |
+
**Key Technologies:**
|
| 204 |
+
- [NumPy](https://numpy.org/) - Fundamental package for scientific computing in Python
|
| 205 |
+
- [SciPy](https://scipy.org/) - Library for mathematics, science, and engineering
|
| 206 |
+
|
| 207 |
+
**What it does:**
|
| 208 |
+
- Calculates angles between landmarks
|
| 209 |
+
- Maps raw angles to appropriate servo ranges
|
| 210 |
+
- Applies smoothing and filtering to reduce jitter
|
| 211 |
+
- Converts 3D hand positions to robotic arm coordinate space
|
| 212 |
+
|
| 213 |
+
**Resources:**
|
| 214 |
+
- [NumPy Documentation](https://numpy.org/doc/stable/)
|
| 215 |
+
- [SciPy Spatial Transforms](https://docs.scipy.org/doc/scipy/reference/spatial.html)
|
| 216 |
+
- [Vector Mathematics Tutorial](https://realpython.com/python-linear-algebra/)
|
| 217 |
+
"""
|
| 218 |
+
)
|
| 219 |
+
|
| 220 |
+
with implementation_tabs[2]:
|
| 221 |
+
st.markdown(
|
| 222 |
+
"""
|
| 223 |
+
### Arduino Communication and Control
|
| 224 |
+
|
| 225 |
+
The calculated angles are sent to an Arduino to control the servos.
|
| 226 |
+
|
| 227 |
+
**Key Technologies:**
|
| 228 |
+
- [pyFirmata2](https://github.com/berndporr/pyFirmata2) - Python interface for the Firmata protocol
|
| 229 |
+
- [Firmata](https://github.com/firmata/arduino) - Protocol for communicating with microcontrollers
|
| 230 |
+
- [PySerial](https://pyserial.readthedocs.io/en/latest/) - Python serial port access library
|
| 231 |
+
- [Arduino Servo Library](https://www.arduino.cc/reference/en/libraries/servo/) - Controls servo motors
|
| 232 |
+
|
| 233 |
+
**What it does:**
|
| 234 |
+
- Establishes serial communication between Python and Arduino
|
| 235 |
+
- Formats and sends servo angle commands
|
| 236 |
+
- Controls multiple servo motors in the robotic arm
|
| 237 |
+
- Provides real-time response to hand position changes
|
| 238 |
+
"""
|
| 239 |
+
)
|
| 240 |
+
|
| 241 |
+
# Demo video
|
| 242 |
+
st.markdown("### Demo Video")
|
| 243 |
+
st.video(
|
| 244 |
+
"assets/hand_control_arm_video.mp4",
|
| 245 |
+
# caption="Demonstration of hand gesture-controlled robotic arm",
|
| 246 |
+
)
|
| 247 |
+
st.markdown(
|
| 248 |
+
"""
|
| 249 |
+
* [GitHub Repository](https://github.com/Fundacao-Asimo/RoboArm)
|
| 250 |
+
"""
|
| 251 |
+
)
|
| 252 |
+
|
| 253 |
+
# Educational impact
|
| 254 |
+
st.markdown("---")
|
| 255 |
+
st.subheader("Educational Impact")
|
| 256 |
+
|
| 257 |
+
st.markdown(
|
| 258 |
+
"""
|
| 259 |
+
### Learning Outcomes
|
| 260 |
+
- **Computer Vision Concepts:** Introduction to image processing, feature detection, and tracking
|
| 261 |
+
- **Robotics Fundamentals:** Servo control, degrees of freedom, coordinate systems
|
| 262 |
+
- **Programming Skills:** Python, Arduino/C++, communication protocols
|
| 263 |
+
- **Engineering Design:** System integration, calibration, testing
|
| 264 |
+
|
| 265 |
+
### Student Feedback
|
| 266 |
+
Students find this project particularly engaging because it:
|
| 267 |
+
- Provides immediate visual feedback
|
| 268 |
+
- Feels like "magic" when the arm responds to hand movements
|
| 269 |
+
- Combines multiple disciplines in a tangible application
|
| 270 |
+
- Offers many opportunities for creative extensions and customization
|
| 271 |
+
"""
|
| 272 |
+
)
|
| 273 |
+
|
| 274 |
+
# Footer with attribution
|
| 275 |
+
st.markdown("---")
|
| 276 |
+
st.markdown(
|
| 277 |
+
"""
|
| 278 |
+
### Project Team
|
| 279 |
+
|
| 280 |
+
This work was developed and implemented as part of the Asimo Foundation at UNIFEI.
|
| 281 |
+
Special thanks to all the volunteers, educators, and students who contributed to this initiative.
|
| 282 |
+
"""
|
| 283 |
+
)
|
| 284 |
+
|
| 285 |
+
|
| 286 |
+
st.markdown("[🌎 Asimo Foundation](https://www.instagram.com/fundacaoasimo/)")
|
pages/3_cafe_dl.py
ADDED
|
@@ -0,0 +1,596 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import streamlit as st
|
| 2 |
+
from streamlit_mermaid import st_mermaid
|
| 3 |
+
from streamlit_extras.badges import badge
|
| 4 |
+
|
| 5 |
+
# Set page configuration
|
| 6 |
+
st.set_page_config(
|
| 7 |
+
page_title="CafeDL Project | CV Journey",
|
| 8 |
+
page_icon="☕",
|
| 9 |
+
layout="wide",
|
| 10 |
+
initial_sidebar_state="expanded",
|
| 11 |
+
)
|
| 12 |
+
|
| 13 |
+
# Title and introduction
|
| 14 |
+
st.header("☕ CafeDL - A Java Deep Learning Library")
|
| 15 |
+
|
| 16 |
+
st.markdown(
|
| 17 |
+
"""
|
| 18 |
+
### Building Neural Networks from Scratch in Java
|
| 19 |
+
|
| 20 |
+
CafeDL is a deep learning framework I developed from scratch during my Software Design undergraduate course.
|
| 21 |
+
Inspired by Keras' architecture and API, it's an educational exploration of neural network fundamentals,
|
| 22 |
+
implemented entirely in Java.
|
| 23 |
+
|
| 24 |
+
This project combines software engineering principles with machine learning concepts, demonstrating how
|
| 25 |
+
modern deep learning frameworks are designed under the hood.
|
| 26 |
+
"""
|
| 27 |
+
)
|
| 28 |
+
|
| 29 |
+
st.markdown(
|
| 30 |
+
"[GitHub Repository: samuellimabraz/cafedl](https://github.com/samuellimabraz/cafedl)"
|
| 31 |
+
)
|
| 32 |
+
|
| 33 |
+
# Project motivation
|
| 34 |
+
st.markdown("---")
|
| 35 |
+
st.subheader("Project Motivation")
|
| 36 |
+
|
| 37 |
+
st.markdown(
|
| 38 |
+
"""
|
| 39 |
+
### Why Build a DL Framework from Scratch?
|
| 40 |
+
|
| 41 |
+
Most deep learning courses teach how to use existing frameworks like TensorFlow or PyTorch.
|
| 42 |
+
While valuable for practical applications, this approach often leaves engineers with knowledge gaps
|
| 43 |
+
in the fundamental concepts that power these frameworks.
|
| 44 |
+
|
| 45 |
+
**By building CafeDL, I aimed to:**
|
| 46 |
+
|
| 47 |
+
- **Deepen Understanding:** Learn the mathematical foundations and computational challenges of neural networks
|
| 48 |
+
- **Apply Design Patterns:** Explore software architecture patterns in a complex domain
|
| 49 |
+
- **Bridge Engineering & ML:** Connect software engineering principles with machine learning concepts
|
| 50 |
+
- **Challenge Myself:** Implement gradient descent, backpropagation, convolutional operations, and more without relying on existing libraries
|
| 51 |
+
"""
|
| 52 |
+
)
|
| 53 |
+
|
| 54 |
+
|
| 55 |
+
# Technology Stack
|
| 56 |
+
st.markdown("---")
|
| 57 |
+
st.subheader("Technology Stack")
|
| 58 |
+
|
| 59 |
+
col1, col2 = st.columns(2)
|
| 60 |
+
|
| 61 |
+
with col1:
|
| 62 |
+
st.markdown(
|
| 63 |
+
"""
|
| 64 |
+
### Core Technologies
|
| 65 |
+
|
| 66 |
+
- **Java:** The entire library is implemented in pure Java
|
| 67 |
+
- **ND4J (N-Dimensional Arrays for Java):** Used for tensor and matrix manipulation
|
| 68 |
+
- **MongoDB & Morphia:** For Object Document Mapping (ODM) and persisting trained models
|
| 69 |
+
- **JavaFX:** For the QuickDraw game interface
|
| 70 |
+
|
| 71 |
+
ND4J provides efficient data structures similar to NumPy arrays, enabling vectorized operations
|
| 72 |
+
while still implementing my own mathematical operations for learning purposes.
|
| 73 |
+
"""
|
| 74 |
+
)
|
| 75 |
+
|
| 76 |
+
with col2:
|
| 77 |
+
st.markdown(
|
| 78 |
+
"""
|
| 79 |
+
### Design Philosophy
|
| 80 |
+
|
| 81 |
+
- **Educational Focus:** Prioritizes readability and understanding over raw performance
|
| 82 |
+
- **Object-Oriented Design:** Heavy use of design patterns and clean architecture
|
| 83 |
+
- **API Familiarity:** Interface inspired by Keras for intuitive model building
|
| 84 |
+
- **Modularity:** Components are designed to be mixed and matched
|
| 85 |
+
- **Extensibility:** Easy to add new layers, optimizers, and activation functions
|
| 86 |
+
"""
|
| 87 |
+
)
|
| 88 |
+
|
| 89 |
+
# Key features
|
| 90 |
+
st.markdown("---")
|
| 91 |
+
st.subheader("Key Features of CafeDL")
|
| 92 |
+
|
| 93 |
+
col1, col2 = st.columns(2)
|
| 94 |
+
|
| 95 |
+
with col1:
|
| 96 |
+
st.markdown(
|
| 97 |
+
"""
|
| 98 |
+
### Neural Network Components
|
| 99 |
+
|
| 100 |
+
- **Layers:**
|
| 101 |
+
- Dense (Fully Connected)
|
| 102 |
+
- Convolutional 2D
|
| 103 |
+
- Max Pooling 2D
|
| 104 |
+
- Zero Padding 2D
|
| 105 |
+
- Flattening
|
| 106 |
+
- Dropout
|
| 107 |
+
|
| 108 |
+
- **Activation Functions:**
|
| 109 |
+
- ReLU
|
| 110 |
+
- Leaky ReLU
|
| 111 |
+
- SiLU (Sigmoid Linear Unit)
|
| 112 |
+
- Sigmoid
|
| 113 |
+
- Tanh
|
| 114 |
+
- Softmax
|
| 115 |
+
- Linear
|
| 116 |
+
|
| 117 |
+
- **Loss Functions:**
|
| 118 |
+
- Mean Squared Error (MSE)
|
| 119 |
+
- Binary Cross-Entropy
|
| 120 |
+
- Categorical Cross-Entropy
|
| 121 |
+
- Softmax Cross-Entropy
|
| 122 |
+
"""
|
| 123 |
+
)
|
| 124 |
+
|
| 125 |
+
with col2:
|
| 126 |
+
st.markdown(
|
| 127 |
+
"""
|
| 128 |
+
### Training Components
|
| 129 |
+
|
| 130 |
+
- **Optimizers:**
|
| 131 |
+
- SGD (Stochastic Gradient Descent)
|
| 132 |
+
- SGD with Momentum
|
| 133 |
+
- SGD with Nesterov Momentum
|
| 134 |
+
- Regularized SGD
|
| 135 |
+
- Adam
|
| 136 |
+
- RMSProp
|
| 137 |
+
- AdaGrad
|
| 138 |
+
- AdaDelta
|
| 139 |
+
|
| 140 |
+
- **Learning Rate Strategies:**
|
| 141 |
+
- Linear Decay
|
| 142 |
+
- Exponential Decay
|
| 143 |
+
|
| 144 |
+
- **Metrics:**
|
| 145 |
+
- Accuracy
|
| 146 |
+
- Precision
|
| 147 |
+
- Recall
|
| 148 |
+
- F1 Score
|
| 149 |
+
- MSE, RMSE, MAE
|
| 150 |
+
- R²
|
| 151 |
+
"""
|
| 152 |
+
)
|
| 153 |
+
|
| 154 |
+
# Data Processing Features
|
| 155 |
+
st.markdown("---")
|
| 156 |
+
st.subheader("Data Processing Features")
|
| 157 |
+
|
| 158 |
+
st.markdown(
|
| 159 |
+
"""
|
| 160 |
+
### Comprehensive Data Pipeline
|
| 161 |
+
|
| 162 |
+
- **Data Loading:** Utility functions to load and preprocess training/testing data
|
| 163 |
+
- **Preprocessing:** Tools for data normalization and transformation
|
| 164 |
+
- StandardScaler
|
| 165 |
+
- MinMaxScaler
|
| 166 |
+
- One-hot encoding
|
| 167 |
+
- **Visualization:** Functions to plot model predictions and training performance
|
| 168 |
+
- **Image Utilities:** Convert between array and image formats
|
| 169 |
+
"""
|
| 170 |
+
)
|
| 171 |
+
|
| 172 |
+
# Example usage code
|
| 173 |
+
st.markdown("---")
|
| 174 |
+
|
| 175 |
+
# Add a more complete model example from the README
|
| 176 |
+
st.markdown("### Example: Building & Training a CNN Model")
|
| 177 |
+
|
| 178 |
+
st.code(
|
| 179 |
+
"""
|
| 180 |
+
DataLoader dataLoader = new DataLoader(root + "/npy/train/x_train250.npy", root + "/npy/train/y_train250.npy", root + "/npy/test/x_test250.npy", root + "/npy/test/y_test250.npy");
|
| 181 |
+
INDArray xTrain = dataLoader.getAllTrainImages().get(NDArrayIndex.interval(0, trainSize));
|
| 182 |
+
INDArray yTrain = dataLoader.getAllTrainLabels().reshape(-1, 1).get(NDArrayIndex.interval(0, trainSize));
|
| 183 |
+
INDArray xTest = dataLoader.getAllTestImages().get(NDArrayIndex.interval(0, testSize));
|
| 184 |
+
INDArray yTest = dataLoader.getAllTestLabels().reshape(-1, 1).get(NDArrayIndex.interval(0, testSize));
|
| 185 |
+
|
| 186 |
+
// Normalization
|
| 187 |
+
xTrain = xTrain.divi(255);
|
| 188 |
+
xTest = xTest.divi(255);
|
| 189 |
+
// Reshape
|
| 190 |
+
xTrain = xTrain.reshape(xTrain.rows(), 28, 28, 1);
|
| 191 |
+
xTest = xTest.reshape(xTest.rows(), 28, 28, 1);
|
| 192 |
+
|
| 193 |
+
NeuralNetwork model = new ModelBuilder()
|
| 194 |
+
.add(new Conv2D(32, 2, Arrays.asList(2, 2), "valid", Activation.create("relu"), "he"))
|
| 195 |
+
.add(new Conv2D(16, 1, Arrays.asList(1, 1), "valid", Activation.create("relu"), "he"))
|
| 196 |
+
.add(new Flatten())
|
| 197 |
+
.add(new Dense(178, Activation.create("relu"), "he"))
|
| 198 |
+
.add(new Dropout(0.4))
|
| 199 |
+
.add(new Dense(49, Activation.create("relu"), "he"))
|
| 200 |
+
.add(new Dropout(0.3))
|
| 201 |
+
.add(new Dense(numClasses, Activation.create("linear"), "he"))
|
| 202 |
+
.build();
|
| 203 |
+
|
| 204 |
+
int epochs = 20;
|
| 205 |
+
int batchSize = 64;
|
| 206 |
+
|
| 207 |
+
LearningRateDecayStrategy lr = new ExponentialDecayStrategy(0.01, 0.0001, epochs);
|
| 208 |
+
Optimizer optimizer = new RMSProp(lr);
|
| 209 |
+
Trainer trainer = new TrainerBuilder(model, xTrain, yTrain, xTest, yTest, new SoftmaxCrossEntropy())
|
| 210 |
+
.setOptimizer(optimizer)
|
| 211 |
+
.setBatchSize(batchSize)
|
| 212 |
+
.setEpochs(epochs)
|
| 213 |
+
.setEvalEvery(2)
|
| 214 |
+
.setEarlyStopping(true)
|
| 215 |
+
.setPatience(4)
|
| 216 |
+
.setMetric(new Accuracy())
|
| 217 |
+
.build();
|
| 218 |
+
trainer.fit();
|
| 219 |
+
""",
|
| 220 |
+
language="java",
|
| 221 |
+
)
|
| 222 |
+
|
| 223 |
+
# Application: QuickDraw Game
|
| 224 |
+
st.markdown("---")
|
| 225 |
+
st.subheader("Application: QuickDraw Game Clone")
|
| 226 |
+
|
| 227 |
+
col1, col2 = st.columns(2)
|
| 228 |
+
|
| 229 |
+
with col1:
|
| 230 |
+
st.markdown(
|
| 231 |
+
"""
|
| 232 |
+
### Project Demo: Real-time Drawing Recognition
|
| 233 |
+
|
| 234 |
+
As a demonstration of CafeDL's capabilities, I developed a JavaFX application inspired by Google's QuickDraw game.
|
| 235 |
+
|
| 236 |
+
**Features:**
|
| 237 |
+
|
| 238 |
+
- Real-time classification of hand-drawn sketches
|
| 239 |
+
- Drawing canvas with intuitive UI
|
| 240 |
+
- Displays model confidence for each class
|
| 241 |
+
- User feedback and game mechanics
|
| 242 |
+
- 10 different object categories for classification
|
| 243 |
+
- Database integration to store drawings and game sessions
|
| 244 |
+
|
| 245 |
+
**Technical Implementation:**
|
| 246 |
+
|
| 247 |
+
- **CNN Model:** Trained using CafeDL on the QuickDraw dataset
|
| 248 |
+
- **Game Logic:** 4 rounds per session, requiring >50% confidence for success
|
| 249 |
+
- **Database:** MongoDB for storing drawings and game statistics
|
| 250 |
+
- **MVC Architecture:** Clean separation of game components using JavaFX
|
| 251 |
+
"""
|
| 252 |
+
)
|
| 253 |
+
|
| 254 |
+
with col2:
|
| 255 |
+
# Placeholder for QuickDraw game video
|
| 256 |
+
st.video(
|
| 257 |
+
"assets/quickdraw_game_video.mp4",
|
| 258 |
+
)
|
| 259 |
+
|
| 260 |
+
# Regression Examples
|
| 261 |
+
st.markdown("---")
|
| 262 |
+
st.subheader("Regression Examples")
|
| 263 |
+
|
| 264 |
+
st.markdown(
|
| 265 |
+
"""
|
| 266 |
+
### Function Approximation Capabilities
|
| 267 |
+
|
| 268 |
+
CafeDL isn't limited to classification problems. It can also tackle regression tasks, approximating various functions:
|
| 269 |
+
|
| 270 |
+
- Linear regression
|
| 271 |
+
- Sine waves
|
| 272 |
+
- Complex 3D surfaces like Rosenbrock and Saddle functions
|
| 273 |
+
|
| 274 |
+
Example visualizations from the original project include:
|
| 275 |
+
"""
|
| 276 |
+
)
|
| 277 |
+
|
| 278 |
+
|
| 279 |
+
col1, col2 = st.columns(2)
|
| 280 |
+
col3, col4 = st.columns(2)
|
| 281 |
+
|
| 282 |
+
with col1:
|
| 283 |
+
st.markdown("#### Saddle Function")
|
| 284 |
+
st.image("assets/saddle_function2.png", use_container_width=True)
|
| 285 |
+
|
| 286 |
+
with col2:
|
| 287 |
+
st.markdown("#### Rosenbrock Function")
|
| 288 |
+
st.image("assets/rosenbrock2.png", use_container_width=True)
|
| 289 |
+
|
| 290 |
+
with col3:
|
| 291 |
+
st.markdown("#### Sine Function")
|
| 292 |
+
st.image("assets/sine.png", use_container_width=True)
|
| 293 |
+
|
| 294 |
+
with col4:
|
| 295 |
+
st.markdown("#### Linear Regression")
|
| 296 |
+
st.image("assets/linear.png", use_container_width=True)
|
| 297 |
+
|
| 298 |
+
|
| 299 |
+
# UML Diagrams with Mermaid
|
| 300 |
+
st.markdown("---")
|
| 301 |
+
st.subheader("CafeDL Architecture: UML Diagrams")
|
| 302 |
+
|
| 303 |
+
# Create all diagram file paths
|
| 304 |
+
diagram_files = {
|
| 305 |
+
"Full Diagram": "assets/full_diagram.md",
|
| 306 |
+
"Layers": "assets/layers_diagram.md",
|
| 307 |
+
"Activations": "assets/activations_diagram.md",
|
| 308 |
+
"Models": "assets/models_diagram.md",
|
| 309 |
+
"Optimizers": "assets/optimizers_diagram.md",
|
| 310 |
+
"Losses": "assets/losses_diagram.md",
|
| 311 |
+
"Metrics": "assets/metrics_diagram.md",
|
| 312 |
+
"Data": "assets/data_diagram.md",
|
| 313 |
+
"Database": "assets/database_diagram.md",
|
| 314 |
+
"Train": "assets/train_diagram.md",
|
| 315 |
+
}
|
| 316 |
+
|
| 317 |
+
|
| 318 |
+
# Function to extract Mermaid diagram text from .md files
|
| 319 |
+
def extract_mermaid_from_md(file_path):
|
| 320 |
+
try:
|
| 321 |
+
with open(file_path, "r") as file:
|
| 322 |
+
content = file.read()
|
| 323 |
+
# Extract the Mermaid content between the ```mermaid and ``` tags
|
| 324 |
+
if "```mermaid" in content and "```" in content:
|
| 325 |
+
start_idx = content.find("```mermaid") + len("```mermaid")
|
| 326 |
+
end_idx = content.rfind("```")
|
| 327 |
+
return content[start_idx:end_idx].strip()
|
| 328 |
+
return None
|
| 329 |
+
except Exception as e:
|
| 330 |
+
st.error(f"Error reading diagram file {file_path}: {e}")
|
| 331 |
+
return None
|
| 332 |
+
|
| 333 |
+
|
| 334 |
+
# Display diagrams sequentially
|
| 335 |
+
st.info(
|
| 336 |
+
"The following UML diagrams represent the architecture of the CafeDL framework, organized by namespace."
|
| 337 |
+
)
|
| 338 |
+
|
| 339 |
+
# For each diagram, display it sequentially
|
| 340 |
+
for name, file_path in diagram_files.items():
|
| 341 |
+
st.markdown(f"### {name}")
|
| 342 |
+
st.markdown(f"UML class diagram showing the {name.lower()} structure.")
|
| 343 |
+
|
| 344 |
+
mermaid_content = extract_mermaid_from_md(file_path)
|
| 345 |
+
|
| 346 |
+
if mermaid_content:
|
| 347 |
+
st_mermaid(mermaid_content)
|
| 348 |
+
else:
|
| 349 |
+
st.warning(f"Could not load diagram from {file_path}")
|
| 350 |
+
|
| 351 |
+
# Fallback diagrams for common namespace views
|
| 352 |
+
if name == "Activations":
|
| 353 |
+
st_mermaid(
|
| 354 |
+
"""
|
| 355 |
+
classDiagram
|
| 356 |
+
class IActivation {
|
| 357 |
+
<<interface>>
|
| 358 |
+
+forward(input): INDArray
|
| 359 |
+
+backward(gradient): INDArray
|
| 360 |
+
}
|
| 361 |
+
|
| 362 |
+
class Sigmoid {
|
| 363 |
+
+forward(input): INDArray
|
| 364 |
+
+backward(gradient): INDArray
|
| 365 |
+
}
|
| 366 |
+
|
| 367 |
+
class TanH {
|
| 368 |
+
+forward(input): INDArray
|
| 369 |
+
+backward(gradient): INDArray
|
| 370 |
+
}
|
| 371 |
+
|
| 372 |
+
class ReLU {
|
| 373 |
+
+forward(input): INDArray
|
| 374 |
+
+backward(gradient): INDArray
|
| 375 |
+
}
|
| 376 |
+
|
| 377 |
+
class LeakyReLU {
|
| 378 |
+
-alpha: double
|
| 379 |
+
+forward(input): INDArray
|
| 380 |
+
+backward(gradient): INDArray
|
| 381 |
+
}
|
| 382 |
+
|
| 383 |
+
class Linear {
|
| 384 |
+
+forward(input): INDArray
|
| 385 |
+
+backward(gradient): INDArray
|
| 386 |
+
}
|
| 387 |
+
|
| 388 |
+
class SiLU {
|
| 389 |
+
+forward(input): INDArray
|
| 390 |
+
+backward(gradient): INDArray
|
| 391 |
+
}
|
| 392 |
+
|
| 393 |
+
class Softmax {
|
| 394 |
+
+forward(input): INDArray
|
| 395 |
+
+backward(gradient): INDArray
|
| 396 |
+
}
|
| 397 |
+
|
| 398 |
+
IActivation <|.. Sigmoid
|
| 399 |
+
IActivation <|.. TanH
|
| 400 |
+
IActivation <|.. ReLU
|
| 401 |
+
IActivation <|.. LeakyReLU
|
| 402 |
+
IActivation <|.. Linear
|
| 403 |
+
IActivation <|.. SiLU
|
| 404 |
+
IActivation <|.. Softmax
|
| 405 |
+
"""
|
| 406 |
+
)
|
| 407 |
+
elif name == "Layers":
|
| 408 |
+
st_mermaid(
|
| 409 |
+
"""
|
| 410 |
+
classDiagram
|
| 411 |
+
class Layer {
|
| 412 |
+
<<abstract>>
|
| 413 |
+
#inputShape: int[]
|
| 414 |
+
#outputShape: int[]
|
| 415 |
+
+forward(input): double[][]
|
| 416 |
+
+backward(gradient): double[][]
|
| 417 |
+
+getParameters(): Map<String, double[][]>
|
| 418 |
+
+updateParameters(optimizer): void
|
| 419 |
+
}
|
| 420 |
+
|
| 421 |
+
class TrainableLayer {
|
| 422 |
+
<<abstract>>
|
| 423 |
+
#params: INDArray
|
| 424 |
+
#grads: INDArray
|
| 425 |
+
#trainable: boolean
|
| 426 |
+
+setup(input): void
|
| 427 |
+
+getParams(): INDArray
|
| 428 |
+
+getGrads(): INDArray
|
| 429 |
+
}
|
| 430 |
+
|
| 431 |
+
class Dense {
|
| 432 |
+
-weights: INDArray
|
| 433 |
+
-bias: INDArray
|
| 434 |
+
-activation: IActivation
|
| 435 |
+
+Dense(units, activation)
|
| 436 |
+
+forward(input): INDArray
|
| 437 |
+
+backward(gradient): INDArray
|
| 438 |
+
}
|
| 439 |
+
|
| 440 |
+
class Conv2D {
|
| 441 |
+
-filters: INDArray
|
| 442 |
+
-biases: INDArray
|
| 443 |
+
-kernelSize: int[]
|
| 444 |
+
-strides: int[]
|
| 445 |
+
-padding: String
|
| 446 |
+
-activation: IActivation
|
| 447 |
+
+Conv2D(filters, kernelHeight, kernelWidth, activation, padding)
|
| 448 |
+
+forward(input): INDArray
|
| 449 |
+
+backward(gradient): INDArray
|
| 450 |
+
}
|
| 451 |
+
|
| 452 |
+
class MaxPooling2D {
|
| 453 |
+
-poolSize: int[]
|
| 454 |
+
-strides: int[]
|
| 455 |
+
+MaxPooling2D(poolHeight, poolWidth, strides)
|
| 456 |
+
+forward(input): INDArray
|
| 457 |
+
+backward(gradient): INDArray
|
| 458 |
+
}
|
| 459 |
+
|
| 460 |
+
class Flatten {
|
| 461 |
+
+forward(input): INDArray
|
| 462 |
+
+backward(gradient): INDArray
|
| 463 |
+
}
|
| 464 |
+
|
| 465 |
+
class Dropout {
|
| 466 |
+
-rate: double
|
| 467 |
+
-mask: INDArray
|
| 468 |
+
+Dropout(rate)
|
| 469 |
+
+forward(input): INDArray
|
| 470 |
+
+backward(gradient): INDArray
|
| 471 |
+
}
|
| 472 |
+
|
| 473 |
+
class ZeroPadding2D {
|
| 474 |
+
-padding: int
|
| 475 |
+
+ZeroPadding2D(padding)
|
| 476 |
+
+forward(input): INDArray
|
| 477 |
+
+backward(gradient): INDArray
|
| 478 |
+
}
|
| 479 |
+
|
| 480 |
+
Layer <|-- TrainableLayer
|
| 481 |
+
TrainableLayer <|-- Dense
|
| 482 |
+
TrainableLayer <|-- Conv2D
|
| 483 |
+
Layer <|-- MaxPooling2D
|
| 484 |
+
Layer <|-- Flatten
|
| 485 |
+
Layer <|-- Dropout
|
| 486 |
+
Layer <|-- ZeroPadding2D
|
| 487 |
+
Conv2D --> ZeroPadding2D : uses
|
| 488 |
+
"""
|
| 489 |
+
)
|
| 490 |
+
elif name == "Optimizers":
|
| 491 |
+
st_mermaid(
|
| 492 |
+
"""
|
| 493 |
+
classDiagram
|
| 494 |
+
class Optimizer {
|
| 495 |
+
<<abstract>>
|
| 496 |
+
#learningRate: double
|
| 497 |
+
#neuralNetwork: NeuralNetwork
|
| 498 |
+
+update(): void
|
| 499 |
+
+updateEpoch(): void
|
| 500 |
+
#createAuxParams(params): List<INDArray>
|
| 501 |
+
#updateRule(params, grads, auxParams): void
|
| 502 |
+
}
|
| 503 |
+
|
| 504 |
+
class LearningRateDecayStrategy {
|
| 505 |
+
<<abstract>>
|
| 506 |
+
#decayPerEpoch: double
|
| 507 |
+
#learningRate: double
|
| 508 |
+
+updateLearningRate(): double
|
| 509 |
+
}
|
| 510 |
+
|
| 511 |
+
class SGD {
|
| 512 |
+
+SGD(learningRate)
|
| 513 |
+
#updateRule(params, grads, auxParams): void
|
| 514 |
+
}
|
| 515 |
+
|
| 516 |
+
class SGDMomentum {
|
| 517 |
+
-momentum: double
|
| 518 |
+
+SGDMomentum(learningRate, momentum)
|
| 519 |
+
#updateRule(params, grads, auxParams): void
|
| 520 |
+
}
|
| 521 |
+
|
| 522 |
+
class Adam {
|
| 523 |
+
-beta1: double
|
| 524 |
+
-beta2: double
|
| 525 |
+
-epsilon: double
|
| 526 |
+
+Adam(learningRate, beta1, beta2, epsilon)
|
| 527 |
+
#updateRule(params, grads, auxParams): void
|
| 528 |
+
}
|
| 529 |
+
|
| 530 |
+
class RMSProp {
|
| 531 |
+
-decayRate: double
|
| 532 |
+
-epsilon: double
|
| 533 |
+
+RMSProp(learningRate, decayRate, epsilon)
|
| 534 |
+
#updateRule(params, grads, auxParams): void
|
| 535 |
+
}
|
| 536 |
+
|
| 537 |
+
Optimizer <|-- SGD
|
| 538 |
+
Optimizer <|-- SGDMomentum
|
| 539 |
+
Optimizer <|-- Adam
|
| 540 |
+
Optimizer <|-- RMSProp
|
| 541 |
+
|
| 542 |
+
LearningRateDecayStrategy <|-- ExponentialDecayStrategy
|
| 543 |
+
LearningRateDecayStrategy <|-- LinearDecayStrategy
|
| 544 |
+
|
| 545 |
+
Optimizer o-- LearningRateDecayStrategy
|
| 546 |
+
"""
|
| 547 |
+
)
|
| 548 |
+
|
| 549 |
+
# Add a separator between diagrams
|
| 550 |
+
st.markdown("---")
|
| 551 |
+
|
| 552 |
+
# Technical challenges
|
| 553 |
+
st.markdown("---")
|
| 554 |
+
|
| 555 |
+
st.markdown(
|
| 556 |
+
"""
|
| 557 |
+
### Key Learning Outcomes
|
| 558 |
+
|
| 559 |
+
- **Deep Understanding of Neural Networks:** Gained insights into the mathematical foundations of deep learning
|
| 560 |
+
- **Software Design Patterns:** Applied OOP principles to a complex domain
|
| 561 |
+
- **Algorithm Implementation:** Translated mathematical concepts into efficient code
|
| 562 |
+
- **Performance Optimization:** Balanced readability with computational efficiency
|
| 563 |
+
- **Full Stack Development:** Combined ML models with UI and database components
|
| 564 |
+
- **Documentation & API Design:** Created an intuitive interface for users
|
| 565 |
+
"""
|
| 566 |
+
)
|
| 567 |
+
|
| 568 |
+
# Conclusion and future work
|
| 569 |
+
st.markdown("---")
|
| 570 |
+
st.subheader("Conclusion & Future Work")
|
| 571 |
+
|
| 572 |
+
st.markdown(
|
| 573 |
+
"""
|
| 574 |
+
### Project Impact & Next Steps
|
| 575 |
+
|
| 576 |
+
The CafeDL project successfully demonstrates how modern deep learning frameworks function internally,
|
| 577 |
+
while providing a practical educational tool for exploring neural network concepts.
|
| 578 |
+
|
| 579 |
+
**Future Enhancements:**
|
| 580 |
+
- Additional layer types (LSTM, GRU, BatchNorm)
|
| 581 |
+
- More optimization algorithms
|
| 582 |
+
- Transfer learning capabilities
|
| 583 |
+
- Data augmentation pipeline
|
| 584 |
+
- Enhanced visualization tools
|
| 585 |
+
- Performance optimizations
|
| 586 |
+
|
| 587 |
+
This project represents the intersection of software engineering principles and machine learning concepts,
|
| 588 |
+
providing a foundation for deeper exploration of both fields.
|
| 589 |
+
"""
|
| 590 |
+
)
|
| 591 |
+
|
| 592 |
+
badge(
|
| 593 |
+
type="github",
|
| 594 |
+
name="samuellimabraz/cafedl",
|
| 595 |
+
url="https://github.com/samuellimabraz/cafedl",
|
| 596 |
+
)
|
pages/4_tech4humans.py
ADDED
|
@@ -0,0 +1,695 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import streamlit as st
|
| 2 |
+
import plotly.graph_objects as go
|
| 3 |
+
import plotly.express as px
|
| 4 |
+
import pandas as pd
|
| 5 |
+
from streamlit_extras.badges import badge
|
| 6 |
+
import numpy as np
|
| 7 |
+
import pathlib
|
| 8 |
+
import streamlit.components.v1 as components
|
| 9 |
+
|
| 10 |
+
# Set page configuration
|
| 11 |
+
st.set_page_config(
|
| 12 |
+
page_title="Tech4Humans Projects | CV Journey",
|
| 13 |
+
page_icon="💼",
|
| 14 |
+
layout="wide",
|
| 15 |
+
initial_sidebar_state="expanded",
|
| 16 |
+
)
|
| 17 |
+
|
| 18 |
+
# Title and introduction
|
| 19 |
+
st.header("💼 Tech4Humans - Industry Applications of CV")
|
| 20 |
+
|
| 21 |
+
st.markdown(
|
| 22 |
+
"""
|
| 23 |
+
### Professional Experience in Machine Learning Engineering
|
| 24 |
+
|
| 25 |
+
I joined Tech4Humans initially as an ML Engineering intern in mid-2024 and was later hired as a full-time
|
| 26 |
+
Machine Learning Engineer. My work focuses on customizing and creating AI models for real-world applications,
|
| 27 |
+
with a strong emphasis on computer vision solutions.
|
| 28 |
+
|
| 29 |
+
This section showcases two significant CV projects I've worked on at Tech4Humans:
|
| 30 |
+
"""
|
| 31 |
+
)
|
| 32 |
+
|
| 33 |
+
# Project tabs
|
| 34 |
+
projects_tab = st.tabs(["Signature Detection", "Document Information Extraction"])
|
| 35 |
+
|
| 36 |
+
# Signature Detection Project
|
| 37 |
+
with projects_tab[0]:
|
| 38 |
+
st.subheader("Open-Source Signature Detection Model")
|
| 39 |
+
|
| 40 |
+
col1, col2 = st.columns([1, 1])
|
| 41 |
+
|
| 42 |
+
with col1:
|
| 43 |
+
html_content = """
|
| 44 |
+
<div style="
|
| 45 |
+
display: flex;
|
| 46 |
+
gap: 24px;
|
| 47 |
+
margin: 2em 0;
|
| 48 |
+
line-height: 1.6;
|
| 49 |
+
">
|
| 50 |
+
|
| 51 |
+
<!-- Left Column - Text -->
|
| 52 |
+
<div style="flex: 1; padding-right: 16px;">
|
| 53 |
+
<p style="font-size: 1.1rem; margin-bottom: 1em;">
|
| 54 |
+
This article presents an <strong>open-source project</strong> for automated signature detection in document processing, structured into four key phases:
|
| 55 |
+
</p>
|
| 56 |
+
<ul style="padding-left: 20px; margin-bottom: 1em; font-size: 1rem;">
|
| 57 |
+
<li><strong>Dataset Engineering:</strong> Curation of a hybrid dataset through aggregation of two public collections.</li>
|
| 58 |
+
<li><strong>Architecture Benchmarking:</strong> Systematic evaluation of state-of-the-art object detection architectures (<em>YOLO series, DETR variants, and YOLOS</em>), focusing on accuracy, computational efficiency, and deployment constraints.</li>
|
| 59 |
+
<li><strong>Model Optimization:</strong> Leveraged Optuna for hyperparameter tuning, yielding a 7.94% F1-score improvement over baseline configurations.</li>
|
| 60 |
+
<li><strong>Production Deployment:</strong> Utilized Triton Inference Server for OpenVINO CPU-optimized inference.</li>
|
| 61 |
+
</ul>
|
| 62 |
+
<p style="font-size: 1.1rem; margin-top: 1em;">
|
| 63 |
+
Experimental results demonstrate a robust balance between precision, recall, and inference speed, validating the solution's practicality for real-world applications.
|
| 64 |
+
</p>
|
| 65 |
+
</div>
|
| 66 |
+
|
| 67 |
+
<!-- Right Column - Images -->
|
| 68 |
+
<div style="
|
| 69 |
+
flex: 1;
|
| 70 |
+
display: flex;
|
| 71 |
+
flex-direction: column;
|
| 72 |
+
gap: 12px;
|
| 73 |
+
">
|
| 74 |
+
<img src="https://cdn-uploads.huggingface.co/production/uploads/666b9ef5e6c60b6fc4156675/6AnC1ut7EOLa6EjibXZXY.webp"
|
| 75 |
+
style="max-width: 100%; height: auto; border-radius: 8px; box-shadow: 0 4px 8px rgba(0,0,0,0.1);">
|
| 76 |
+
<div style="display: flex; gap: 12px;">
|
| 77 |
+
<img src="https://cdn-uploads.huggingface.co/production/uploads/666b9ef5e6c60b6fc4156675/jWxcAUZPt8Bzup8kL-bor.webp"
|
| 78 |
+
style="flex: 1; max-width: 50%; height: auto; border-radius: 8px; box-shadow: 0 4px 8px rgba(0,0,0,0.1);">
|
| 79 |
+
<img src="https://cdn-uploads.huggingface.co/production/uploads/666b9ef5e6c60b6fc4156675/tzK0lJz7mI2fazpY9pB1w.webp"
|
| 80 |
+
style="flex: 1; max-width: 50%; height: auto; border-radius: 8px; box-shadow: 0 4px 8px rgba(0,0,0,0.1);">
|
| 81 |
+
</div>
|
| 82 |
+
</div>
|
| 83 |
+
|
| 84 |
+
</div>
|
| 85 |
+
"""
|
| 86 |
+
st.html(html_content)
|
| 87 |
+
|
| 88 |
+
# Dataset section
|
| 89 |
+
st.markdown("---")
|
| 90 |
+
st.markdown("### Dataset Engineering")
|
| 91 |
+
|
| 92 |
+
col1, col2 = st.columns([2, 1])
|
| 93 |
+
|
| 94 |
+
with col1:
|
| 95 |
+
st.markdown(
|
| 96 |
+
"""
|
| 97 |
+
#### Dataset Composition & Preprocessing
|
| 98 |
+
|
| 99 |
+
The dataset was constructed by merging two publicly available benchmarks:
|
| 100 |
+
|
| 101 |
+
- **[Tobacco800](https://paperswithcode.com/dataset/tobacco-800):** Scanned documents with signature annotations.
|
| 102 |
+
- **[Signatures-XC8UP](https://universe.roboflow.com/roboflow-100/signatures-xc8up):** Part of the Roboflow 100 benchmark with handwritten signature images.
|
| 103 |
+
|
| 104 |
+
**Preprocessing & Augmentation (using [Roboflow](https://roboflow.com/)):**
|
| 105 |
+
- **Split:** Training (70%), Validation (15%), Test (15%) from 2,819 total images.
|
| 106 |
+
- **Preprocessing:** Auto-orientation, resize to 640x640px.
|
| 107 |
+
- **Augmentation:** Rotation, shear, brightness/exposure changes, blur, noise to enhance model robustness.
|
| 108 |
+
|
| 109 |
+
The final dataset combines diverse document types and signature styles.
|
| 110 |
+
"""
|
| 111 |
+
)
|
| 112 |
+
|
| 113 |
+
with col2:
|
| 114 |
+
st.image(
|
| 115 |
+
"https://cdn-uploads.huggingface.co/production/uploads/666b9ef5e6c60b6fc4156675/_o4PZzTyj17qhUYMLM2Yn.png",
|
| 116 |
+
caption="Figure 10: Annotated document samples (Source: Signature Detection Article)",
|
| 117 |
+
use_container_width=True,
|
| 118 |
+
)
|
| 119 |
+
st.caption(
|
| 120 |
+
"The dataset includes various document types with annotated signatures and logos."
|
| 121 |
+
)
|
| 122 |
+
|
| 123 |
+
# Architecture evaluation
|
| 124 |
+
st.markdown("---")
|
| 125 |
+
st.markdown("### Architecture Evaluation")
|
| 126 |
+
|
| 127 |
+
st.markdown(
|
| 128 |
+
"""
|
| 129 |
+
We systematically evaluated multiple state-of-the-art object detection architectures (YOLO series, DETR variants, YOLOS)
|
| 130 |
+
to find the optimal balance between accuracy (mAP), inference speed (CPU ONNX), and training time.
|
| 131 |
+
The results below are based on training for 35 epochs.
|
| 132 |
+
"""
|
| 133 |
+
)
|
| 134 |
+
|
| 135 |
+
# Actual model performance comparison data from Article Table 3
|
| 136 |
+
model_data = {
|
| 137 |
+
"Model": [
|
| 138 |
+
"rtdetr-l",
|
| 139 |
+
"yolos-base",
|
| 140 |
+
"yolos-tiny",
|
| 141 |
+
"conditional-detr",
|
| 142 |
+
"detr",
|
| 143 |
+
"yolov8x",
|
| 144 |
+
"yolov8l",
|
| 145 |
+
"yolov8m",
|
| 146 |
+
"yolov8s",
|
| 147 |
+
"yolov8n",
|
| 148 |
+
"yolo11x",
|
| 149 |
+
"yolo11l",
|
| 150 |
+
"yolo11m",
|
| 151 |
+
"yolo11s",
|
| 152 |
+
"yolo11n",
|
| 153 |
+
"yolov10x",
|
| 154 |
+
"yolov10l",
|
| 155 |
+
"yolov10b",
|
| 156 |
+
"yolov10m",
|
| 157 |
+
"yolov10s",
|
| 158 |
+
"yolov10n",
|
| 159 |
+
"yolo12n",
|
| 160 |
+
"yolo12s",
|
| 161 |
+
"yolo12m",
|
| 162 |
+
"yolo12l",
|
| 163 |
+
"yolo12x",
|
| 164 |
+
],
|
| 165 |
+
"mAP@50 (%)": [
|
| 166 |
+
92.71,
|
| 167 |
+
90.12,
|
| 168 |
+
86.98,
|
| 169 |
+
93.65,
|
| 170 |
+
88.89,
|
| 171 |
+
79.42,
|
| 172 |
+
80.03,
|
| 173 |
+
87.53,
|
| 174 |
+
87.47,
|
| 175 |
+
81.61,
|
| 176 |
+
66.71,
|
| 177 |
+
70.74,
|
| 178 |
+
80.96,
|
| 179 |
+
83.56,
|
| 180 |
+
81.38,
|
| 181 |
+
68.10,
|
| 182 |
+
72.68,
|
| 183 |
+
78.98,
|
| 184 |
+
78.77,
|
| 185 |
+
66.39,
|
| 186 |
+
73.43,
|
| 187 |
+
75.86,
|
| 188 |
+
66.66,
|
| 189 |
+
61.96,
|
| 190 |
+
54.92,
|
| 191 |
+
51.16,
|
| 192 |
+
],
|
| 193 |
+
"Inference Time (ms)": [
|
| 194 |
+
583.6,
|
| 195 |
+
1706.5,
|
| 196 |
+
265.3,
|
| 197 |
+
476.8,
|
| 198 |
+
425.6,
|
| 199 |
+
1259.5,
|
| 200 |
+
871.3,
|
| 201 |
+
401.2,
|
| 202 |
+
216.6,
|
| 203 |
+
110.4,
|
| 204 |
+
1016.7,
|
| 205 |
+
518.1,
|
| 206 |
+
381.7,
|
| 207 |
+
179.8,
|
| 208 |
+
106.7,
|
| 209 |
+
821.2,
|
| 210 |
+
580.8,
|
| 211 |
+
473.1,
|
| 212 |
+
320.1,
|
| 213 |
+
150.1,
|
| 214 |
+
73.9,
|
| 215 |
+
90.4,
|
| 216 |
+
166.6,
|
| 217 |
+
372.8,
|
| 218 |
+
505.7,
|
| 219 |
+
1022.8,
|
| 220 |
+
],
|
| 221 |
+
"mAP@50-95 (%)": [ # Added for hover data
|
| 222 |
+
62.24,
|
| 223 |
+
58.36,
|
| 224 |
+
46.91,
|
| 225 |
+
65.33,
|
| 226 |
+
57.94,
|
| 227 |
+
55.29,
|
| 228 |
+
59.40,
|
| 229 |
+
66.55,
|
| 230 |
+
65.46,
|
| 231 |
+
62.40,
|
| 232 |
+
48.23,
|
| 233 |
+
49.91,
|
| 234 |
+
60.08,
|
| 235 |
+
63.88,
|
| 236 |
+
61.75,
|
| 237 |
+
47.45,
|
| 238 |
+
52.27,
|
| 239 |
+
57.89,
|
| 240 |
+
58.13,
|
| 241 |
+
47.39,
|
| 242 |
+
55.27,
|
| 243 |
+
55.87,
|
| 244 |
+
48.54,
|
| 245 |
+
45.62,
|
| 246 |
+
41.00,
|
| 247 |
+
35.42,
|
| 248 |
+
],
|
| 249 |
+
}
|
| 250 |
+
|
| 251 |
+
model_df = pd.DataFrame(model_data)
|
| 252 |
+
model_df = model_df.sort_values(
|
| 253 |
+
"Inference Time (ms)"
|
| 254 |
+
) # Sort for better visualization
|
| 255 |
+
|
| 256 |
+
# Create a scatter plot for model comparison (based on Article Figure 11)
|
| 257 |
+
fig = px.scatter(
|
| 258 |
+
model_df,
|
| 259 |
+
x="Inference Time (ms)",
|
| 260 |
+
y="mAP@50 (%)",
|
| 261 |
+
color="Model", # Color by model
|
| 262 |
+
hover_name="Model",
|
| 263 |
+
hover_data=["mAP@50-95 (%)"], # Show mAP50-95 on hover
|
| 264 |
+
text="Model", # Display model names on points (optional, can be cluttered)
|
| 265 |
+
title="Model Architecture Comparison (CPU ONNX Inference)",
|
| 266 |
+
)
|
| 267 |
+
|
| 268 |
+
fig.update_traces(textposition="top center") # Adjust text position if displayed
|
| 269 |
+
fig.update_layout(
|
| 270 |
+
xaxis_title="Inference Time (ms) - lower is better",
|
| 271 |
+
yaxis_title="mAP@50 (%) - higher is better",
|
| 272 |
+
height=600, # Increased height for clarity
|
| 273 |
+
margin=dict(l=20, r=20, t=50, b=20),
|
| 274 |
+
legend_title_text="Model Variant",
|
| 275 |
+
)
|
| 276 |
+
# Optional: Add annotations for key models if needed
|
| 277 |
+
# fig.add_annotation(x=216.6, y=87.47, text="YOLOv8s", showarrow=True, arrowhead=1)
|
| 278 |
+
# fig.add_annotation(x=73.9, y=73.43, text="YOLOv10n (Fastest)", showarrow=True, arrowhead=1)
|
| 279 |
+
# fig.add_annotation(x=476.8, y=93.65, text="Conditional DETR (Highest mAP@50)", showarrow=True, arrowhead=1)
|
| 280 |
+
|
| 281 |
+
st.plotly_chart(fig, use_container_width=True)
|
| 282 |
+
|
| 283 |
+
st.markdown(
|
| 284 |
+
"""
|
| 285 |
+
**Model Selection:**
|
| 286 |
+
|
| 287 |
+
While `conditional-detr-resnet-50` achieved the highest mAP@50 (93.65%), and `yolov10n` had the lowest CPU inference time (73.9 ms), **YOLOv8s** was selected for further optimization.
|
| 288 |
+
|
| 289 |
+
**Rationale for YOLOv8s:**
|
| 290 |
+
- **Strong Balance:** Offered a competitive mAP@50 (87.47%) and mAP@50-95 (65.46%) with a reasonable inference time (216.6 ms).
|
| 291 |
+
- **Efficiency:** Convolutional architectures like YOLO generally showed faster inference and training times compared to transformer models in this experiment.
|
| 292 |
+
- **Export & Ecosystem:** Excellent support for various export formats (ONNX, OpenVINO, TensorRT) facilitated by the Ultralytics library, simplifying deployment.
|
| 293 |
+
- **Community & Development:** Active development and large community support.
|
| 294 |
+
"""
|
| 295 |
+
)
|
| 296 |
+
|
| 297 |
+
# Hyperparameter tuning
|
| 298 |
+
st.markdown("---")
|
| 299 |
+
st.markdown("### Hyperparameter Optimization")
|
| 300 |
+
|
| 301 |
+
col1, col2 = st.columns([2, 1]) # Keep ratio
|
| 302 |
+
|
| 303 |
+
with col1:
|
| 304 |
+
st.markdown(
|
| 305 |
+
"""
|
| 306 |
+
Using **Optuna**, we performed hyperparameter tuning on the selected **YOLOv8s** model over 20 trials, optimizing for the F1-score on the test set.
|
| 307 |
+
|
| 308 |
+
**Key Parameters Explored:**
|
| 309 |
+
- `dropout`: (0.0 to 0.5)
|
| 310 |
+
- `lr0` (Initial Learning Rate): (1e-5 to 1e-1, log scale)
|
| 311 |
+
- `box` (Box Loss Weight): (3.0 to 7.0)
|
| 312 |
+
- `cls` (Class Loss Weight): (0.5 to 1.5)
|
| 313 |
+
- `optimizer`: (AdamW, RMSProp)
|
| 314 |
+
|
| 315 |
+
**Optimization Objective:**
|
| 316 |
+
Maximize F1-score, balancing precision and recall, crucial for signature detection where both false positives and false negatives are problematic.
|
| 317 |
+
|
| 318 |
+
**Results:**
|
| 319 |
+
The best trial (#10) significantly improved performance compared to the baseline YOLOv8s configuration, notably increasing Recall.
|
| 320 |
+
"""
|
| 321 |
+
)
|
| 322 |
+
|
| 323 |
+
with col2:
|
| 324 |
+
# Data from Article Table 4
|
| 325 |
+
hp_results = {
|
| 326 |
+
"Model": ["YOLOv8s (Base)", "YOLOv8s (Tuned)"],
|
| 327 |
+
"F1-score (%)": [85.42, 93.36],
|
| 328 |
+
"Precision (%)": [97.23, 95.61],
|
| 329 |
+
"Recall (%)": [76.16, 91.21],
|
| 330 |
+
"mAP@50 (%)": [87.47, 95.75],
|
| 331 |
+
"mAP@50-95 (%)": [65.46, 66.26],
|
| 332 |
+
}
|
| 333 |
+
hp_df = pd.DataFrame(hp_results)
|
| 334 |
+
|
| 335 |
+
# Create bar chart comparing F1 scores
|
| 336 |
+
fig_hp = px.bar(
|
| 337 |
+
hp_df,
|
| 338 |
+
x="Model",
|
| 339 |
+
y="F1-score (%)",
|
| 340 |
+
color="Model",
|
| 341 |
+
title="F1-Score Improvement After HPO",
|
| 342 |
+
text="F1-score (%)",
|
| 343 |
+
color_discrete_sequence=px.colors.qualitative.Pastel,
|
| 344 |
+
labels={"F1-score (%)": "F1-Score (%)"},
|
| 345 |
+
hover_data=["Precision (%)", "Recall (%)", "mAP@50 (%)", "mAP@50-95 (%)"],
|
| 346 |
+
)
|
| 347 |
+
fig_hp.update_traces(texttemplate="%{text:.2f}%", textposition="outside")
|
| 348 |
+
fig_hp.update_layout(
|
| 349 |
+
yaxis_range=[0, 100], # Set y-axis from 0 to 100
|
| 350 |
+
height=400, # Adjusted height
|
| 351 |
+
margin=dict(l=20, r=20, t=40, b=20),
|
| 352 |
+
showlegend=False,
|
| 353 |
+
)
|
| 354 |
+
st.plotly_chart(fig_hp, use_container_width=True)
|
| 355 |
+
st.markdown(
|
| 356 |
+
f"The tuning resulted in a **{hp_df.loc[1, 'F1-score (%)'] - hp_df.loc[0, 'F1-score (%)']:.2f}% absolute improvement** in F1-score."
|
| 357 |
+
)
|
| 358 |
+
|
| 359 |
+
# Production deployment
|
| 360 |
+
st.markdown("---")
|
| 361 |
+
st.markdown("### Production Deployment")
|
| 362 |
+
|
| 363 |
+
st.markdown(
|
| 364 |
+
"""
|
| 365 |
+
The final, optimized YOLOv8s model was deployed using a production-ready inference pipeline designed for efficiency and scalability.
|
| 366 |
+
|
| 367 |
+
**Key Components:**
|
| 368 |
+
- **Model Format:** Exported to **ONNX** for broad compatibility and optimized CPU inference with **OpenVINO**. TensorRT format also available for GPU inference.
|
| 369 |
+
- **Inference Server:** **Triton Inference Server** used for serving the model, chosen for its flexibility and performance.
|
| 370 |
+
- **Deployment:** Containerized using **Docker** for reproducible environments. A custom Docker image including only necessary backends (Python, ONNX, OpenVINO) was built to reduce size.
|
| 371 |
+
- **Ensemble Model:** A Triton Ensemble Model integrates preprocessing (Python), inference (ONNX/OpenVINO), and postprocessing (Python, including NMS) into a single server-side pipeline, minimizing latency.
|
| 372 |
+
|
| 373 |
+
**Final Performance Metrics (Test Set):**
|
| 374 |
+
- **Precision:** 94.74%
|
| 375 |
+
- **Recall:** 89.72%
|
| 376 |
+
- **F1-score:** 93.36% (derived from Precision/Recall or Table 4)
|
| 377 |
+
- **mAP@50:** 94.50%
|
| 378 |
+
- **mAP@50-95:** 67.35%
|
| 379 |
+
- **Inference Latency:**
|
| 380 |
+
- CPU (ONNX Runtime): **~171.6 ms**
|
| 381 |
+
- GPU (TensorRT on T4): **~7.7 ms**
|
| 382 |
+
"""
|
| 383 |
+
)
|
| 384 |
+
|
| 385 |
+
# Architecture diagram
|
| 386 |
+
st.markdown("### Deployment Architecture (Triton Ensemble)")
|
| 387 |
+
|
| 388 |
+
# Mermaid diagram for the Ensemble Model (based on Article Figure 14)
|
| 389 |
+
mermaid_code = """
|
| 390 |
+
flowchart TB
|
| 391 |
+
subgraph "Triton Inference Server"
|
| 392 |
+
direction TB
|
| 393 |
+
subgraph "Ensemble Model Pipeline"
|
| 394 |
+
direction TB
|
| 395 |
+
subgraph Input
|
| 396 |
+
raw["raw_image
|
| 397 |
+
(UINT8, [-1])"]
|
| 398 |
+
conf["confidence_threshold
|
| 399 |
+
(FP16, [1])"]
|
| 400 |
+
iou["iou_threshold
|
| 401 |
+
(FP16, [1])"]
|
| 402 |
+
end
|
| 403 |
+
|
| 404 |
+
subgraph "Preprocess Py-Backend"
|
| 405 |
+
direction TB
|
| 406 |
+
pre1["Decode Image
|
| 407 |
+
BGR to RGB"]
|
| 408 |
+
pre2["Resize (640x640)"]
|
| 409 |
+
pre3["Normalize (/255.0)"]
|
| 410 |
+
pre4["Transpose
|
| 411 |
+
[H,W,C]->[C,H,W]"]
|
| 412 |
+
pre1 --> pre2 --> pre3 --> pre4
|
| 413 |
+
end
|
| 414 |
+
|
| 415 |
+
subgraph "YOLOv8 Model ONNX Backend"
|
| 416 |
+
yolo["Inference YOLOv8s"]
|
| 417 |
+
end
|
| 418 |
+
|
| 419 |
+
subgraph "Postproces Python Backend"
|
| 420 |
+
direction TB
|
| 421 |
+
post1["Transpose
|
| 422 |
+
Outputs"]
|
| 423 |
+
post2["Filter Boxes (confidence_threshold)"]
|
| 424 |
+
post3["NMS (iou_threshold)"]
|
| 425 |
+
post4["Format Results [x,y,w,h,score]"]
|
| 426 |
+
post1 --> post2 --> post3 --> post4
|
| 427 |
+
end
|
| 428 |
+
|
| 429 |
+
subgraph Output
|
| 430 |
+
result["detection_result
|
| 431 |
+
(FP16, [-1,5])"]
|
| 432 |
+
end
|
| 433 |
+
|
| 434 |
+
raw --> pre1
|
| 435 |
+
pre4 --> |"preprocessed_image (FP32, [3,-1,-1])"| yolo
|
| 436 |
+
yolo --> |"output0"| post1
|
| 437 |
+
conf --> post2
|
| 438 |
+
iou --> post3
|
| 439 |
+
post4 --> result
|
| 440 |
+
end
|
| 441 |
+
end
|
| 442 |
+
|
| 443 |
+
subgraph Client
|
| 444 |
+
direction TB
|
| 445 |
+
client_start["Client Application"]
|
| 446 |
+
response["Detections Result
|
| 447 |
+
[x,y,w,h,score]"]
|
| 448 |
+
end
|
| 449 |
+
|
| 450 |
+
client_start -->|"HTTP/gRPC Request
|
| 451 |
+
with raw image
|
| 452 |
+
confidence_threshold
|
| 453 |
+
iou_threshold"| raw
|
| 454 |
+
result -->|"HTTP/gRPC Response with detections"| response
|
| 455 |
+
"""
|
| 456 |
+
|
| 457 |
+
# Check if streamlit_mermaid is available
|
| 458 |
+
try:
|
| 459 |
+
from streamlit_mermaid import st_mermaid
|
| 460 |
+
|
| 461 |
+
st_mermaid(mermaid_code)
|
| 462 |
+
except ImportError:
|
| 463 |
+
st.warning(
|
| 464 |
+
"`streamlit-mermaid` not installed. Displaying Mermaid code instead."
|
| 465 |
+
)
|
| 466 |
+
st.code(mermaid_code, language="mermaid")
|
| 467 |
+
|
| 468 |
+
# Project resources
|
| 469 |
+
st.markdown("---")
|
| 470 |
+
st.markdown("### Project Resources")
|
| 471 |
+
|
| 472 |
+
st.markdown(
|
| 473 |
+
"""
|
| 474 |
+
| Resource | Links / Badges | Details |
|
| 475 |
+
|----------|----------------|---------|
|
| 476 |
+
| **Article** | [](https://huggingface.co/blog/samuellimabraz/signature-detection-model) | A detailed community article covering the full development process of the project |
|
| 477 |
+
| **Model Files** | [](https://huggingface.co/tech4humans/yolov8s-signature-detector) | **Available formats:** [](https://pytorch.org/) [](https://onnx.ai/) [](https://developer.nvidia.com/tensorrt) |
|
| 478 |
+
| **Dataset – Original** | [](https://universe.roboflow.com/tech-ysdkk/signature-detection-hlx8j) | 2,819 document images annotated with signature coordinates |
|
| 479 |
+
| **Dataset – Processed** | [](https://huggingface.co/datasets/tech4humans/signature-detection) | Augmented and pre-processed version (640px) for model training |
|
| 480 |
+
| **Notebooks – Model Experiments** | [](https://colab.research.google.com/drive/1wSySw_zwyuv6XSaGmkngI4dwbj-hR4ix) [](https://api.wandb.ai/links/samuel-lima-tech4humans/30cmrkp8) | Complete training and evaluation pipeline with selection among different architectures (yolo, detr, rt-detr, conditional-detr, yolos) |
|
| 481 |
+
| **Notebooks – HP Tuning** | [](https://colab.research.google.com/drive/1wSySw_zwyuv6XSaGmkngI4dwbj-hR4ix) [](https://api.wandb.ai/links/samuel-lima-tech4humans/31a6zhb1) | Optuna trials for optimizing the precision/recall balance |
|
| 482 |
+
| **Inference Server** | [](https://github.com/tech4ai/t4ai-signature-detect-server) | Complete deployment and inference pipeline with Triton Inference Server<br> [](https://docs.openvino.ai/2025/index.html) [](https://www.docker.com/) [](https://developer.nvidia.com/triton-inference-server) |
|
| 483 |
+
| **Live Demo** | [](https://huggingface.co/spaces/tech4humans/signature-detection) | Graphical interface with real-time inference<br> [](https://www.gradio.app/) [](https://plotly.com/python/) |
|
| 484 |
+
""",
|
| 485 |
+
unsafe_allow_html=True,
|
| 486 |
+
)
|
| 487 |
+
|
| 488 |
+
# Live demo using iframe
|
| 489 |
+
st.markdown("### Live Demo")
|
| 490 |
+
st.components.v1.iframe(
|
| 491 |
+
"https://tech4humans-signature-detection.hf.space", height=1000, scrolling=True
|
| 492 |
+
)
|
| 493 |
+
|
| 494 |
+
# Project impact
|
| 495 |
+
st.markdown("---")
|
| 496 |
+
st.markdown("### Project Impact")
|
| 497 |
+
|
| 498 |
+
col1, col2 = st.columns(2)
|
| 499 |
+
|
| 500 |
+
with col1:
|
| 501 |
+
st.markdown(
|
| 502 |
+
"""
|
| 503 |
+
#### Community Recognition
|
| 504 |
+
|
| 505 |
+
This project gained visibility in the ML community:
|
| 506 |
+
|
| 507 |
+
- +100 upvote in Community Articles
|
| 508 |
+
- Shared by [Merve Noyan](https://huggingface.co/merve) on LinkedIn
|
| 509 |
+
- Served as a reference for end-to-end computer vision projects
|
| 510 |
+
"""
|
| 511 |
+
)
|
| 512 |
+
|
| 513 |
+
with col2:
|
| 514 |
+
st.markdown(
|
| 515 |
+
"""
|
| 516 |
+
#### Business Impact
|
| 517 |
+
|
| 518 |
+
The model has been integrated into document processing pipelines, resulting in:
|
| 519 |
+
|
| 520 |
+
- **Automation:** Reduction in manual verification steps
|
| 521 |
+
- **Accuracy:** Fewer missed signatures and false positives
|
| 522 |
+
- **Speed:** Faster document processing throughput
|
| 523 |
+
"""
|
| 524 |
+
)
|
| 525 |
+
|
| 526 |
+
# Document Data Extraction Project
|
| 527 |
+
with projects_tab[1]:
|
| 528 |
+
st.subheader("Fine-tuning Vision-Language Models for Structured Document Extraction")
|
| 529 |
+
|
| 530 |
+
st.markdown("""
|
| 531 |
+
### Project Goal: Extracting Structured Data from Brazilian Documents
|
| 532 |
+
|
| 533 |
+
This project explores fine-tuning open-source Vision-Language Models (VLMs) to extract structured data (JSON format) from images of Brazilian documents (National IDs - RG, Driver's Licenses - CNH, Invoices - NF) based on user-defined schemas.
|
| 534 |
+
|
| 535 |
+
The objective wasn't to replace existing solutions immediately but to validate the capabilities of smaller, fine-tuned VLMs and our ability to train and deploy them efficiently.
|
| 536 |
+
""")
|
| 537 |
+
|
| 538 |
+
# --- Dataset Section ---
|
| 539 |
+
st.markdown("---")
|
| 540 |
+
st.markdown("### 1. Dataset Refinement and Preparation")
|
| 541 |
+
st.markdown("""
|
| 542 |
+
Building upon public datasets, we initially faced inconsistencies in annotations and data standardization.
|
| 543 |
+
|
| 544 |
+
**Refinement Process:**
|
| 545 |
+
- Manually selected and re-annotated 170 examples each for CNH and RG.
|
| 546 |
+
- Selected high-quality Invoice (Nota Fiscal - NF) samples.
|
| 547 |
+
- **Split:** 70% Training, 15% Validation, 15% Test, maintaining class balance using Roboflow. ([Dataset Link](https://universe.roboflow.com/tech-ysdkk/brazilian-document-extration))
|
| 548 |
+
- **Augmentation:** Used Roboflow to apply image transformations (e.g., rotations, noise) to the training set, tripling its size.
|
| 549 |
+
- **Preprocessing:** Resized images to a maximum of 640x640 (maintaining aspect ratio) for evaluation and training. Initially avoided complex preprocessing like grayscale conversion to prevent model bias.
|
| 550 |
+
|
| 551 |
+
The final dataset provides a robust foundation for evaluating and fine-tuning models on specific Brazilian document types.
|
| 552 |
+
""")
|
| 553 |
+
|
| 554 |
+
# --- Evaluation Section ---
|
| 555 |
+
st.markdown("---")
|
| 556 |
+
st.markdown("### 2. Base Model Evaluation")
|
| 557 |
+
st.markdown("""
|
| 558 |
+
We benchmarked several open-source VLMs (1B to 10B parameters, suitable for L4 GPU) using the [Open VLM Leaderboard](https://huggingface.co/spaces/opencompass/open_vlm_leaderboard) as a reference. Key architectures considered include Qwen-VL, InternVL, Ovis, MiniCPM, DeepSeek-VL, Phi-3.5-Vision, etc.
|
| 559 |
+
|
| 560 |
+
**Efficient Inference with vLLM:**
|
| 561 |
+
- Utilized **vLLM** for optimized inference, leveraging its support for various vision models and features like structured output generation (though not used in the final fine-tuned evaluations). This significantly accelerated prediction compared to standard Transformers pipelines.
|
| 562 |
+
|
| 563 |
+
**Metrics:**
|
| 564 |
+
- Developed custom Python functions to calculate field similarity between predicted and ground truth JSONs.
|
| 565 |
+
- Normalized values (dates, numbers, case, special characters) and used **rapidfuzz** (based on Indel distance) for string similarity scoring (0-100).
|
| 566 |
+
- Calculated overall accuracy and field coverage.
|
| 567 |
+
""")
|
| 568 |
+
|
| 569 |
+
# --- Finetuning Section ---
|
| 570 |
+
st.markdown("---")
|
| 571 |
+
st.markdown("### 3. Fine-tuning Experiments")
|
| 572 |
+
st.markdown("""
|
| 573 |
+
We fine-tuned promising architectures using parameter-efficient techniques (LoRA) to improve performance on our specific dataset.
|
| 574 |
+
|
| 575 |
+
**Frameworks & Tools:**
|
| 576 |
+
- **Unsloth:** Leveraged for optimized training kernels, initially exploring Qwen2.5 but settling on **Qwen2-VL (2B, 7B)** due to better stability and merge compatibility with vLLM.
|
| 577 |
+
- **MS-Swift:** Adopted this comprehensive framework from ModelScope (Alibaba) for its broad support of architectures and fine-tuning methods. Tuned **InternVL-2.5-MPO (1B, 4B)**, **Qwen2.5-VL (3B)**, and **DeepSeek-VL2**.
|
| 578 |
+
- **LoRA:** Employed low-rank adaptation (ranks 2 and 4) with RSLora decay strategy.
|
| 579 |
+
|
| 580 |
+
**Fine-tuning Results:**
|
| 581 |
+
Fine-tuning demonstrated significant accuracy improvements, especially for smaller models, making them competitive with larger base models.
|
| 582 |
+
""")
|
| 583 |
+
|
| 584 |
+
# --- Embed Performance by Category Plot ---
|
| 585 |
+
st.markdown("#### Performance Comparison: Base vs. Fine-tuned (by Category)")
|
| 586 |
+
try:
|
| 587 |
+
# Construct path relative to the current script file
|
| 588 |
+
current_dir = pathlib.Path(__file__).parent
|
| 589 |
+
perf_cat_path = current_dir.parent / "assets/model_performance_by_category.html"
|
| 590 |
+
if perf_cat_path.is_file():
|
| 591 |
+
with open(perf_cat_path, 'r', encoding='utf-8') as f:
|
| 592 |
+
perf_cat_html = f.read()
|
| 593 |
+
components.html(perf_cat_html, height=700, scrolling=True)
|
| 594 |
+
else:
|
| 595 |
+
st.warning(f"Performance by category plot file not found at `{perf_cat_path}`")
|
| 596 |
+
except NameError:
|
| 597 |
+
# Handle case where __file__ is not defined
|
| 598 |
+
st.warning("Cannot determine file path automatically. Make sure `assets/model_performance_by_category.html` exists relative to the execution directory.")
|
| 599 |
+
except Exception as e:
|
| 600 |
+
st.error(f"Error loading performance by category plot: {e}")
|
| 601 |
+
|
| 602 |
+
# --- Embed Heatmap Plot ---
|
| 603 |
+
st.markdown("#### Accuracy Heatmap (Base Models)")
|
| 604 |
+
try:
|
| 605 |
+
# Construct path relative to the current script file
|
| 606 |
+
current_dir = pathlib.Path(__file__).parent
|
| 607 |
+
heatmap_path = current_dir.parent / "assets/heatmap_accuracy.html"
|
| 608 |
+
if heatmap_path.is_file():
|
| 609 |
+
with open(heatmap_path, 'r', encoding='utf-8') as f:
|
| 610 |
+
heatmap_html = f.read()
|
| 611 |
+
components.html(heatmap_html, height=600, scrolling=True)
|
| 612 |
+
else:
|
| 613 |
+
st.warning(f"Heatmap plot file not found at `{heatmap_path}`")
|
| 614 |
+
except NameError:
|
| 615 |
+
# Handle case where __file__ is not defined (e.g. interactive environment)
|
| 616 |
+
st.warning("Cannot determine file path automatically. Make sure `assets/heatmap_accuracy.html` exists relative to the execution directory.")
|
| 617 |
+
except Exception as e:
|
| 618 |
+
st.error(f"Error loading heatmap plot: {e}")
|
| 619 |
+
|
| 620 |
+
st.markdown("""
|
| 621 |
+
**Key Fine-tuning Observations:**
|
| 622 |
+
- **Small Models (1-3B):** Showed the largest relative gains (e.g., `InternVL2_5-1B-MPO-tuned` +28% absolute accuracy, reaching 83% overall). Fine-tuned small models outperformed larger base models.
|
| 623 |
+
- **Medium Models (~4B):** Also improved significantly (e.g., `InternVL2_5-4B-MPO-tuned` +18%, reaching 87% overall, with >90% on CNH).
|
| 624 |
+
- **Large Models (7B+):** Showed more modest gains (+13-14%), suggesting diminishing returns for fine-tuning very large models on this dataset/task.
|
| 625 |
+
- **Efficiency:** Fine-tuning often slightly *reduced* inference time, potentially because structured output guidance (used in base eval) was removed for tuned models as they performed better without it.
|
| 626 |
+
- **Challenge:** Extracting data from Invoices (NF) remained the most difficult task, even after tuning (max ~77% accuracy).
|
| 627 |
+
""")
|
| 628 |
+
|
| 629 |
+
# --- Generalization Section ---
|
| 630 |
+
st.markdown("---")
|
| 631 |
+
st.markdown("### 4. Generalization Analysis (Ongoing)")
|
| 632 |
+
st.markdown("""
|
| 633 |
+
To assess if fine-tuning caused the models to "forget" how to handle different document types, we are evaluating their performance on an out-of-distribution dataset.
|
| 634 |
+
|
| 635 |
+
**Methodology:**
|
| 636 |
+
- Used the English-language [`getomni-ai/ocr-benchmark`](https://huggingface.co/datasets/getomni-ai/ocr-benchmark) dataset.
|
| 637 |
+
- Selected samples from 8 document types with varying layouts and relatively simple JSON schemas.
|
| 638 |
+
- Focus is on the *relative* performance drop between the base model and its fine-tuned version on these unseen documents, rather than absolute accuracy.
|
| 639 |
+
|
| 640 |
+
**Preliminary Results:**
|
| 641 |
+
This plot compares the performance of base vs. fine-tuned models on the original Brazilian dataset vs. the English benchmark dataset. (*Note: Evaluation is ongoing*)
|
| 642 |
+
""")
|
| 643 |
+
|
| 644 |
+
# --- Embed Generalization Plot ---
|
| 645 |
+
st.markdown("#### Generalization Performance: Original vs. English Benchmark")
|
| 646 |
+
try:
|
| 647 |
+
# Construct path relative to the current script file
|
| 648 |
+
current_dir = pathlib.Path(__file__).parent
|
| 649 |
+
gen_path = current_dir.parent / "assets/generic_eval_all.html"
|
| 650 |
+
if gen_path.is_file():
|
| 651 |
+
with open(gen_path, 'r', encoding='utf-8') as f:
|
| 652 |
+
gen_html = f.read()
|
| 653 |
+
components.html(gen_html, height=850, scrolling=True)
|
| 654 |
+
else:
|
| 655 |
+
st.warning(f"Generalization plot file not found at `{gen_path}`")
|
| 656 |
+
except NameError:
|
| 657 |
+
# Handle case where __file__ is not defined
|
| 658 |
+
st.warning("Cannot determine file path automatically. Make sure `assets/generic_eval_all.html` exists relative to the execution directory.")
|
| 659 |
+
except Exception as e:
|
| 660 |
+
st.error(f"Error loading generalization plot: {e}")
|
| 661 |
+
|
| 662 |
+
|
| 663 |
+
# --- Conclusions & Next Steps ---
|
| 664 |
+
st.markdown("---")
|
| 665 |
+
st.markdown("### Conclusions & Next Steps")
|
| 666 |
+
st.markdown("""
|
| 667 |
+
**Key Insights:**
|
| 668 |
+
- Fine-tuned open-source VLMs (even smaller ones) can achieve high accuracy on specific document extraction tasks, rivaling larger models.
|
| 669 |
+
- Parameter-efficient fine-tuning (LoRA) with tools like Unsloth and MS-Swift is effective and feasible on standard hardware (e.g., L4 GPU).
|
| 670 |
+
- vLLM significantly optimizes inference speed for VLMs.
|
| 671 |
+
- There's a trade-off: Fine-tuning boosts performance on target domains but may reduce generalization to unseen document types (analysis ongoing).
|
| 672 |
+
|
| 673 |
+
**Ongoing Work:**
|
| 674 |
+
- Completing the generalization evaluation.
|
| 675 |
+
- Implementing a production-ready inference pipeline using optimized fine-tuned models.
|
| 676 |
+
- Exploring few-shot adaptation techniques for new document types.
|
| 677 |
+
- Investigating model distillation to potentially create even smaller, efficient models.
|
| 678 |
+
""")
|
| 679 |
+
|
| 680 |
+
|
| 681 |
+
# Additional career highlights
|
| 682 |
+
st.markdown("---")
|
| 683 |
+
st.subheader("Additional ML Engineering Experience at Tech4Humans")
|
| 684 |
+
|
| 685 |
+
st.markdown(
|
| 686 |
+
"""
|
| 687 |
+
Beyond the computer vision projects detailed above, my role at Tech4Humans has involved:
|
| 688 |
+
|
| 689 |
+
- **MLOps Pipeline Development:** Building robust training and deployment pipelines for ML models
|
| 690 |
+
- **Performance Optimization:** Tuning models for efficient inference in resource-constrained environments
|
| 691 |
+
- **Data Engineering:** Creating pipelines for data acquisition, cleaning, and annotation
|
| 692 |
+
- **Model Monitoring:** Implementing systems to track model performance and detect drift
|
| 693 |
+
- **Client Consulting:** Working directly with clients to understand requirements and translate them into ML solutions
|
| 694 |
+
"""
|
| 695 |
+
)
|
pages/5_conclusion.py
ADDED
|
@@ -0,0 +1,266 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import streamlit as st
|
| 2 |
+
from streamlit_extras.badges import badge
|
| 3 |
+
import plotly.express as px
|
| 4 |
+
import pandas as pd
|
| 5 |
+
|
| 6 |
+
# Set page configuration
|
| 7 |
+
st.set_page_config(
|
| 8 |
+
page_title="Conclusion | CV Journey",
|
| 9 |
+
page_icon="✅",
|
| 10 |
+
layout="wide",
|
| 11 |
+
initial_sidebar_state="expanded",
|
| 12 |
+
)
|
| 13 |
+
|
| 14 |
+
# Title and introduction
|
| 15 |
+
st.header("✅ Key Takeaways & Future Directions")
|
| 16 |
+
|
| 17 |
+
st.markdown(
|
| 18 |
+
"""
|
| 19 |
+
### My Computer Vision Journey: Connecting the Dots
|
| 20 |
+
|
| 21 |
+
Throughout this presentation, we've explored different facets of my journey in Computer Vision - from robotics and
|
| 22 |
+
autonomous systems to deep learning frameworks and cutting-edge VLMs for document analysis.
|
| 23 |
+
|
| 24 |
+
What connects these diverse projects is a progression of skills, knowledge, and application complexity that
|
| 25 |
+
reflects the broader evolution of the computer vision field itself.
|
| 26 |
+
"""
|
| 27 |
+
)
|
| 28 |
+
|
| 29 |
+
# Core knowledge areas
|
| 30 |
+
st.markdown("---")
|
| 31 |
+
st.subheader("Core Knowledge Areas")
|
| 32 |
+
|
| 33 |
+
col1, col2, col3 = st.columns(3)
|
| 34 |
+
|
| 35 |
+
with col1:
|
| 36 |
+
st.markdown(
|
| 37 |
+
"""
|
| 38 |
+
### Computer Vision Fundamentals
|
| 39 |
+
|
| 40 |
+
- Image processing and filtering techniques
|
| 41 |
+
- Feature detection and tracking
|
| 42 |
+
- Camera calibration and homography
|
| 43 |
+
- Geometric transformations
|
| 44 |
+
- Color spaces and thresholding
|
| 45 |
+
- Motion estimation and optical flow
|
| 46 |
+
- Object detection techniques
|
| 47 |
+
"""
|
| 48 |
+
)
|
| 49 |
+
|
| 50 |
+
with col2:
|
| 51 |
+
st.markdown(
|
| 52 |
+
"""
|
| 53 |
+
### Deep Learning for Vision
|
| 54 |
+
|
| 55 |
+
- Convolutional Neural Networks (CNNs)
|
| 56 |
+
- Model architecture design principles
|
| 57 |
+
- Training and optimization strategies
|
| 58 |
+
- Transfer learning and fine-tuning
|
| 59 |
+
- Object detection frameworks
|
| 60 |
+
- Vision Transformers (ViT)
|
| 61 |
+
- Vision-Language Models (VLMs)
|
| 62 |
+
"""
|
| 63 |
+
)
|
| 64 |
+
|
| 65 |
+
with col3:
|
| 66 |
+
st.markdown(
|
| 67 |
+
"""
|
| 68 |
+
### MLOps & Production Engineering
|
| 69 |
+
|
| 70 |
+
- Dataset engineering and annotation
|
| 71 |
+
- Hyperparameter optimization
|
| 72 |
+
- Model conversion and optimization
|
| 73 |
+
- Inference server deployment
|
| 74 |
+
- Performance benchmarking
|
| 75 |
+
- Integration with larger systems
|
| 76 |
+
- Monitoring and maintenance
|
| 77 |
+
"""
|
| 78 |
+
)
|
| 79 |
+
|
| 80 |
+
# Key experiences by project
|
| 81 |
+
st.markdown("---")
|
| 82 |
+
st.subheader("Key Experiences by Project")
|
| 83 |
+
|
| 84 |
+
project_tabs = st.tabs(
|
| 85 |
+
["Black Bee Drones", "Asimo Foundation", "CafeDL", "Tech4Humans"]
|
| 86 |
+
)
|
| 87 |
+
|
| 88 |
+
with project_tabs[0]:
|
| 89 |
+
col1, col2 = st.columns(2)
|
| 90 |
+
|
| 91 |
+
with col1:
|
| 92 |
+
st.markdown(
|
| 93 |
+
"""
|
| 94 |
+
### Black Bee Drones
|
| 95 |
+
|
| 96 |
+
**Technical Skills:**
|
| 97 |
+
- Real-time image processing
|
| 98 |
+
- Control systems integration (PID)
|
| 99 |
+
- Vision-based, indoor navigation
|
| 100 |
+
- Marker detection and tracking
|
| 101 |
+
- Line following algorithms
|
| 102 |
+
|
| 103 |
+
**Soft Skills:**
|
| 104 |
+
- Teamwork in a multidisciplinary environment
|
| 105 |
+
- Working under competition pressure
|
| 106 |
+
- Quick prototyping and iteration
|
| 107 |
+
- Technical presentation
|
| 108 |
+
"""
|
| 109 |
+
)
|
| 110 |
+
|
| 111 |
+
with col2:
|
| 112 |
+
st.markdown(
|
| 113 |
+
"""
|
| 114 |
+
### Key Lessons
|
| 115 |
+
|
| 116 |
+
1. **Robustness Over Perfection:** In the real world, perception systems must handle varying conditions and edge cases.
|
| 117 |
+
|
| 118 |
+
2. **System Integration Challenges:** Computer vision is just one piece of a complex autonomous system.
|
| 119 |
+
|
| 120 |
+
3. **Resource Constraints:** Balancing computational load with real-time response requirements.
|
| 121 |
+
|
| 122 |
+
4. **Testing is Critical:** Simulation testing before real flights saves time and prevents crashes.
|
| 123 |
+
|
| 124 |
+
5. **Iterative Development:** Start simple, verify, then add complexity incrementally.
|
| 125 |
+
"""
|
| 126 |
+
)
|
| 127 |
+
|
| 128 |
+
with project_tabs[1]:
|
| 129 |
+
col1, col2 = st.columns(2)
|
| 130 |
+
|
| 131 |
+
with col1:
|
| 132 |
+
st.markdown(
|
| 133 |
+
"""
|
| 134 |
+
### Asimo Foundation
|
| 135 |
+
|
| 136 |
+
**Technical Skills:**
|
| 137 |
+
- Computer vision for educational applications
|
| 138 |
+
- Hand and gesture recognition
|
| 139 |
+
- Hardware integration (Arduino, servos)
|
| 140 |
+
- Real-time control systems
|
| 141 |
+
- Simple UI development
|
| 142 |
+
|
| 143 |
+
**Soft Skills:**
|
| 144 |
+
- Teaching complex concepts to beginners
|
| 145 |
+
- Project planning for educational contexts
|
| 146 |
+
- Adapting technical solutions to limited resources
|
| 147 |
+
- Public speaking and demonstration
|
| 148 |
+
"""
|
| 149 |
+
)
|
| 150 |
+
|
| 151 |
+
with col2:
|
| 152 |
+
st.markdown(
|
| 153 |
+
"""
|
| 154 |
+
### Key Lessons
|
| 155 |
+
|
| 156 |
+
1. **Accessibility Matters:** Technology should be approachable for beginners with appropriate scaffolding.
|
| 157 |
+
|
| 158 |
+
2. **Engagement Through Interactivity:** Visual, hands-on applications provide immediate feedback and motivation.
|
| 159 |
+
|
| 160 |
+
3. **Simplified Interfaces:** Complex technology can be presented through simplified interfaces.
|
| 161 |
+
|
| 162 |
+
4. **Project-Based Learning:** Students learn best when working toward tangible, interesting goals.
|
| 163 |
+
|
| 164 |
+
5. **Educational Impact:** Computer vision can be a gateway to broader STEM interest.
|
| 165 |
+
"""
|
| 166 |
+
)
|
| 167 |
+
|
| 168 |
+
with project_tabs[2]:
|
| 169 |
+
col1, col2 = st.columns(2)
|
| 170 |
+
|
| 171 |
+
with col1:
|
| 172 |
+
st.markdown(
|
| 173 |
+
"""
|
| 174 |
+
### CafeDL
|
| 175 |
+
|
| 176 |
+
**Technical Skills:**
|
| 177 |
+
- Deep understanding of neural network architectures
|
| 178 |
+
- Backpropagation and gradient calculation
|
| 179 |
+
- Convolutional operations implementation
|
| 180 |
+
- Software architecture and design patterns
|
| 181 |
+
- Algorithm optimization
|
| 182 |
+
|
| 183 |
+
**Soft Skills:**
|
| 184 |
+
- Independent research and learning
|
| 185 |
+
- Technical documentation writing
|
| 186 |
+
- Project planning and execution
|
| 187 |
+
- Problem decomposition
|
| 188 |
+
"""
|
| 189 |
+
)
|
| 190 |
+
|
| 191 |
+
with col2:
|
| 192 |
+
st.markdown(
|
| 193 |
+
"""
|
| 194 |
+
### Key Lessons
|
| 195 |
+
|
| 196 |
+
1. **First Principles Matter:** Building ML systems from scratch provides deep understanding of the fundamentals.
|
| 197 |
+
|
| 198 |
+
2. **Software Design Matters:** Good architecture makes complex systems maintainable and extensible.
|
| 199 |
+
|
| 200 |
+
3. **Mathematics Underlies Everything:** Strong mathematical foundation is essential for ML implementation.
|
| 201 |
+
|
| 202 |
+
4. **Performance Engineering:** Optimization requires understanding both mathematical and computing constraints.
|
| 203 |
+
|
| 204 |
+
5. **Documentation is Critical:** Clear APIs and documentation are as important as the code itself.
|
| 205 |
+
"""
|
| 206 |
+
)
|
| 207 |
+
|
| 208 |
+
with project_tabs[3]:
|
| 209 |
+
col1, col2 = st.columns(2)
|
| 210 |
+
|
| 211 |
+
with col1:
|
| 212 |
+
st.markdown(
|
| 213 |
+
"""
|
| 214 |
+
### Tech4Humans
|
| 215 |
+
|
| 216 |
+
**Technical Skills:**
|
| 217 |
+
- State-of-the-art model selection and evaluation
|
| 218 |
+
- Dataset engineering and curation
|
| 219 |
+
- Hyperparameter optimization
|
| 220 |
+
- Production deployment pipelines
|
| 221 |
+
- Fine-tuning large models
|
| 222 |
+
- Benchmarking and evaluation
|
| 223 |
+
|
| 224 |
+
**Soft Skills:**
|
| 225 |
+
- Project management
|
| 226 |
+
- Client communication
|
| 227 |
+
- Technical writing
|
| 228 |
+
- Presentation of complex results
|
| 229 |
+
- Collaboration in a business environment
|
| 230 |
+
"""
|
| 231 |
+
)
|
| 232 |
+
|
| 233 |
+
with col2:
|
| 234 |
+
st.markdown(
|
| 235 |
+
"""
|
| 236 |
+
### Key Lessons
|
| 237 |
+
|
| 238 |
+
1. **Problem Definition is Critical:** Understanding business requirements before technical solutions.
|
| 239 |
+
|
| 240 |
+
2. **Data Quality Trumps Model Complexity:** Better data often yields better results than more complex models.
|
| 241 |
+
|
| 242 |
+
3. **Production Readiness:** Considerations beyond model accuracy include inference speed, resource usage, and maintainability.
|
| 243 |
+
|
| 244 |
+
4. **Evaluation Methodology:** Careful evaluation with appropriate metrics is essential for comparing approaches.
|
| 245 |
+
|
| 246 |
+
5. **Generalization Challenges:** Models may perform differently on out-of-distribution data, requiring careful testing.
|
| 247 |
+
"""
|
| 248 |
+
)
|
| 249 |
+
|
| 250 |
+
|
| 251 |
+
# Thank you and Q&A
|
| 252 |
+
st.markdown("---")
|
| 253 |
+
st.markdown("## Thank You for Your Attention!")
|
| 254 |
+
|
| 255 |
+
st.markdown(
|
| 256 |
+
"""
|
| 257 |
+
I hope this presentation has given you an overview of my journey into the world of Computer Vision and that you may have gained some insight or even learned something from it as well.
|
| 258 |
+
|
| 259 |
+
I am excited to continue exploring this field and expanding my knowledge.
|
| 260 |
+
|
| 261 |
+
Feel free to reach out if you have any questions or would like to discuss computer vision or machine learning further!
|
| 262 |
+
"""
|
| 263 |
+
)
|
| 264 |
+
|
| 265 |
+
# Add some fun at the end
|
| 266 |
+
st.balloons()
|
requirements.txt
ADDED
|
@@ -0,0 +1,7 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
streamlit==1.33.0
|
| 2 |
+
plotly==5.18.0
|
| 3 |
+
streamlit-mermaid==0.1.0
|
| 4 |
+
pillow==10.1.0
|
| 5 |
+
pandas==2.1.1
|
| 6 |
+
streamlit-embedcode==0.1.3
|
| 7 |
+
streamlit-extras==0.3.6
|
utils/__init__.py
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
# Utils package initialization file
|
utils/helpers.py
ADDED
|
@@ -0,0 +1,80 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""
|
| 2 |
+
Helper functions for the Computer Vision Journey presentation.
|
| 3 |
+
"""
|
| 4 |
+
|
| 5 |
+
import os
|
| 6 |
+
import streamlit as st
|
| 7 |
+
|
| 8 |
+
|
| 9 |
+
def check_asset_exists(filename):
|
| 10 |
+
"""
|
| 11 |
+
Check if an asset file exists and return the path if it does, otherwise return None.
|
| 12 |
+
|
| 13 |
+
Args:
|
| 14 |
+
filename (str): The filename to check in the assets directory
|
| 15 |
+
|
| 16 |
+
Returns:
|
| 17 |
+
str or None: The full path to the asset if it exists, None otherwise
|
| 18 |
+
"""
|
| 19 |
+
assets_dir = os.path.join(os.path.dirname(os.path.dirname(__file__)), "assets")
|
| 20 |
+
filepath = os.path.join(assets_dir, filename)
|
| 21 |
+
|
| 22 |
+
if os.path.exists(filepath):
|
| 23 |
+
return filepath
|
| 24 |
+
else:
|
| 25 |
+
return None
|
| 26 |
+
|
| 27 |
+
|
| 28 |
+
def display_asset_or_placeholder(
|
| 29 |
+
filename, asset_type="image", caption=None, use_column_width=True
|
| 30 |
+
):
|
| 31 |
+
"""
|
| 32 |
+
Display an asset or a placeholder if the asset doesn't exist.
|
| 33 |
+
|
| 34 |
+
Args:
|
| 35 |
+
filename (str): The filename of the asset
|
| 36 |
+
asset_type (str): The type of asset ('image' or 'video')
|
| 37 |
+
caption (str, optional): Caption for the asset
|
| 38 |
+
use_column_width (bool, optional): Whether to use the full column width
|
| 39 |
+
"""
|
| 40 |
+
filepath = check_asset_exists(filename)
|
| 41 |
+
|
| 42 |
+
if filepath:
|
| 43 |
+
if asset_type == "image":
|
| 44 |
+
st.image(filepath, caption=caption, use_container_width=use_column_width)
|
| 45 |
+
elif asset_type == "video":
|
| 46 |
+
st.video(filepath)
|
| 47 |
+
else:
|
| 48 |
+
if asset_type == "image":
|
| 49 |
+
st.warning(
|
| 50 |
+
f"Place '{filename}' in the assets directory to display the {caption or 'image'}"
|
| 51 |
+
)
|
| 52 |
+
elif asset_type == "video":
|
| 53 |
+
st.warning(
|
| 54 |
+
f"Place '{filename}' in the assets directory to display the {caption or 'video'}"
|
| 55 |
+
)
|
| 56 |
+
|
| 57 |
+
|
| 58 |
+
def display_iframe_or_link(url, height=500):
|
| 59 |
+
"""
|
| 60 |
+
Display an iframe to an external URL or a link if iframe loading fails.
|
| 61 |
+
|
| 62 |
+
Args:
|
| 63 |
+
url (str): The URL to embed
|
| 64 |
+
height (int, optional): Height of the iframe
|
| 65 |
+
"""
|
| 66 |
+
try:
|
| 67 |
+
st.components.v1.iframe(url, height=height)
|
| 68 |
+
except Exception:
|
| 69 |
+
st.warning(f"Unable to load iframe. Please visit the link directly: {url}")
|
| 70 |
+
st.markdown(f"[Open in new tab]({url})")
|
| 71 |
+
|
| 72 |
+
|
| 73 |
+
def get_project_tabs():
|
| 74 |
+
"""
|
| 75 |
+
Return a list of project tab names for consistent naming across pages.
|
| 76 |
+
|
| 77 |
+
Returns:
|
| 78 |
+
list: List of project tab names
|
| 79 |
+
"""
|
| 80 |
+
return ["Black Bee Drones", "Asimov Foundation", "CafeDL", "Tech4Humans"]
|