
SafeEar ASVspoof2019 Audio Anti-Spoofing Model
This repository contains an audio anti-spoofing (spoof detection) model pre-trained on the ASVspoof2019 dataset using the SafeEar framework. The model is designed to distinguish between genuine human speech and various types of spoofed audio.
Model Details
- Developers: HyperStar Team (Zhijiang College of Zhejiang University of Technology)
- Model Type: Audio Anti-spoofing / Spoof Detection
- Framework: SafeEar
- Base Models/Tokenizers Used:
- SpeechTokenizer
- HuBERT Base (ls960)
- Training Dataset: ASVspoof2019 (Logical Access - LA)
- License: Apache 2.0
- Supported Languages: Primarily English, but trained on the diverse ASVspoof2019 dataset.
Repository File Description
SpeechTokenizer.pt: Pre-trained SpeechTokenizer model weights.hubert_base_ls960.pt: Pre-trained HuBERT base model weights.model.ckpt: Fine-tuned SafeEar anti-spoofing model checkpoint.SafeEar-Inference-Test-Script/: Directory containing example inference scripts and test audio.audio.flac: FLAC format audio sample for testing.infer_single_flac.py: Python script for inference on a single FLAC audio file.
How to Use
To perform inference with this model using the provided scripts:
Clone the repository:
git lfs install git clone https://huggingface.co/[your-username]/safeear-asvspoof2019-antispoof cd safeear-asvspoof2019-antispoofSet up the inference environment: Ensure Python is installed, along with any necessary libraries that
infer_single_flac.pymight depend on. You may need to check theSafeEarframework for its specific dependencies.Prepare model files for inference: Copy the model weights into the inference script directory:
cp SpeechTokenizer.pt hubert_base_ls960.pt model.ckpt SafeEar-Inference-Test-Script/Run the inference script: Navigate to the script directory and run the script:
cd SafeEar-Inference-Test-Script/ python infer_single_flac.pyThe script is expected to output the prediction results:
{ "label": [ 1 ], "probs": [ [ 0.00033402442932128906, 0.9996659755706787 ] ] }
Training Details
Framework
The model was trained using the SafeEar framework. SafeEar is designed for building robust speech anti-spoofing systems.
Dataset
The model was trained on the ASVspoof2019 dataset, specifically the Logical Access (LA) partition, which includes various synthetic speech and replay attacks.
Pre-trained Components
- SpeechTokenizer: Used for speech tokenization.
- HuBERT (hubert_base_ls960): Used as a powerful speech feature extractor. The
hubert_base_ls960.ptcheckpoint was used as the base.
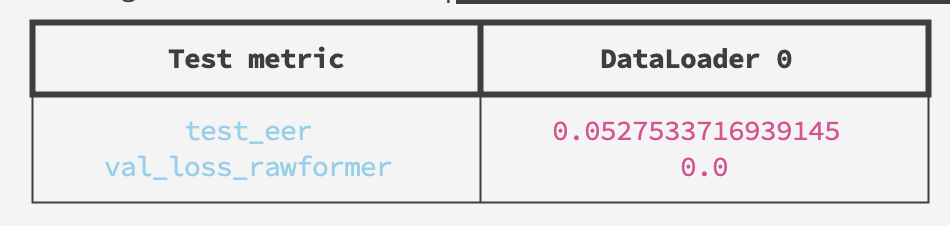
Performance Evaluation
The model achieves the following performance on the ASVspoof2019 LA evaluation set:
- Equal Error Rate (EER): 5.275%
Biases, Risks, and Limitations
- Generalization to Unseen Attacks: While trained on diverse spoofing attacks from ASVspoof2019, the model's performance may degrade on entirely new or significantly different spoofing techniques not present in the training data.
- Acoustic Environment Variability: Highly noisy environments or audio characteristics significantly different from the training data might affect performance.
- Dataset Specificity: The model is optimized for the attack types and audio present in the ASVspoof2019 dataset. It has not been tested on datasets in other languages.
- Threshold Dependency: Classification (bona fide/spoof) typically depends on a threshold. The optimal threshold may vary based on the specific requirements of the application.
Intended Use
This model is intended for researchers and developers working on speech anti-spoofing and voice security applications. It can serve as a baseline for further research or be integrated into systems requiring spoof detection capabilities. It should not be used for critical security applications without further rigorous testing and validation in the target environment.
How to Cite
If you use this model or the SafeEar framework in your research, please consider citing the relevant publications:
ASVspoof2019:
@inproceedings{ASVspoof2019, author={Todisco, Massimiliano and Wang, Xin and Evans, Nicholas and Sahidullah, Md and Delgado, Héctor and Nautsch, Andreas and Yamagishi, Junichi and Lee, Kong Aik and Vestman, Ville and Kinnunen, Tomi and others}, title={{ASVspoof 2019: Future horizons in spoofed and fake audio detection}}, year={2019}, booktitle={Proc. Interspeech 2019}, pages={1008--1012}, doi={10.21437/Interspeech.2019-2248} }SafeEar:
@misc{SafeEar, author = {Ivan Kukanov, Konstantin Okunev, Alexandra Kuznetsova, Anton Vasiliev}, title = {SafeEar: A versatile framework for speech anti-spoofing}, year = {2023}, publisher = {GitHub}, journal = {GitHub repository}, howpublished = {\url{https://github.com/IDRnD/SafeEar}} }HuBERT:
@article{Hsu2021HuBERT, title={{HuBERT: Self-Supervised Speech Representation Learning by Masked Prediction of Hidden Units}}, author={Wei-Ning Hsu and Benjamin Bolte and Yao-Hung Hubert Tsai and Kushal Lakhotia and Ruslan Salakhutdinov and Abdelrahman Mohamed}, journal={IEEE/ACM Transactions on Audio, Speech, and Language Processing}, year={2021}, volume={29}, pages={3451-3465}, doi={10.1109/TASLP.2021.3122891} }
Author Information
- Model Creator: https://huggingface.co/TEC2004
- If you have any questions or feedback, please submit an issue in the repository.